목차
MLOps 에 대한 사전조사

MLOps 를 조사하면서 그림들이랑 다이어그램들이 정말 많이 나온다고 느꼈는데, 이 그림들 하나하나가 굉장히 배울 점이 많기 때문에, 그냥 참고하는 느낌으로 그림을 보는 것이 아니라 정말 이 그림들을 보고 배우겠다는 생각으로 그림을 봐야 내용들이 눈에 들어올거라고 생각해요.
현실 세계에 있는 다양한 Drift
현실 세계에서 사용할 수 있는 모델에는 다양한 Drift 가 존재한다. 우리가 과거 데이터로부터 학습한 예측 모델 y=f(x) 가 있다고 생각을 해 보자. 이때, f 는 우리가 궁금해하는 특징 공간으로 mapping 을 해 주는 함수이다.
Often, this mapping is assumed to be static, meaning that the mapping learned from historical data is just as valid in the future on new data and that the relationships between input and output data do not change.
종종 우리는 이 mapping 이, 과거 사건으로부터 학습한 이 input-output 의 과정이 미래에도 동일하게 적용될 것이라고 static 할 것이라고 여긴다. 하지만, 현실은 그렇지 않다.
Concept Drift
In most challenging data analysis applications, data evolve over time and must be analyzed in near real time. Patterns and relations in such data often evolve over time, thus, models built for analyzing such data quickly become obsolete over time. In machine learning and data mining this phenomenon is referred to as concept drift.
Concept drift 에서 Cocept 란, unknown and hidden relationship between inputs and output variables 을 의미한다. 그래서, Concept drift 는 종속 변수의 속성이 변경되는 모델 드리프트 유형이다. 예를 들어, 'A를 하고 B를 하고 C를 하는 사람들은 공포 영화를 좋아해!' 라는 방식으로 예측하는 모델이 있다고 생각해 보자. 하지만 이 모델은 미래에도 잘 작동할 것이라고 생각할 수 없다. A 라는 기준이 바뀌어도, B 라는 기준이 바뀌어도, C 라는 기준이 바뀌어도 작동하지 않는 모델이 된다.
Data Drift / Upstream data changes
독립변수의 속성이 변경되는 모델 드리프트 유형이며, 파이프라인의 운영데이터 변경으로부터 발생하기도 한다. 피처가 더이상 생성되지 않아 값이 누락되는 경우, 피처의 단위가 달라지는 경우 등이 이에 속한다. 모델 입력 데이터의 변경 내용이다.
•
대체 중인 센서와 같이 측정 단위를 인치에서 센티미터 단위로 변경 하는 업스트림 프로세스 변경 내용
•
손상 된 센서로부터 항상 0을 읽어들임.
•
계절으로 변화 하는 평균 온도와 같이 자연적인 입력 데이터의 변화
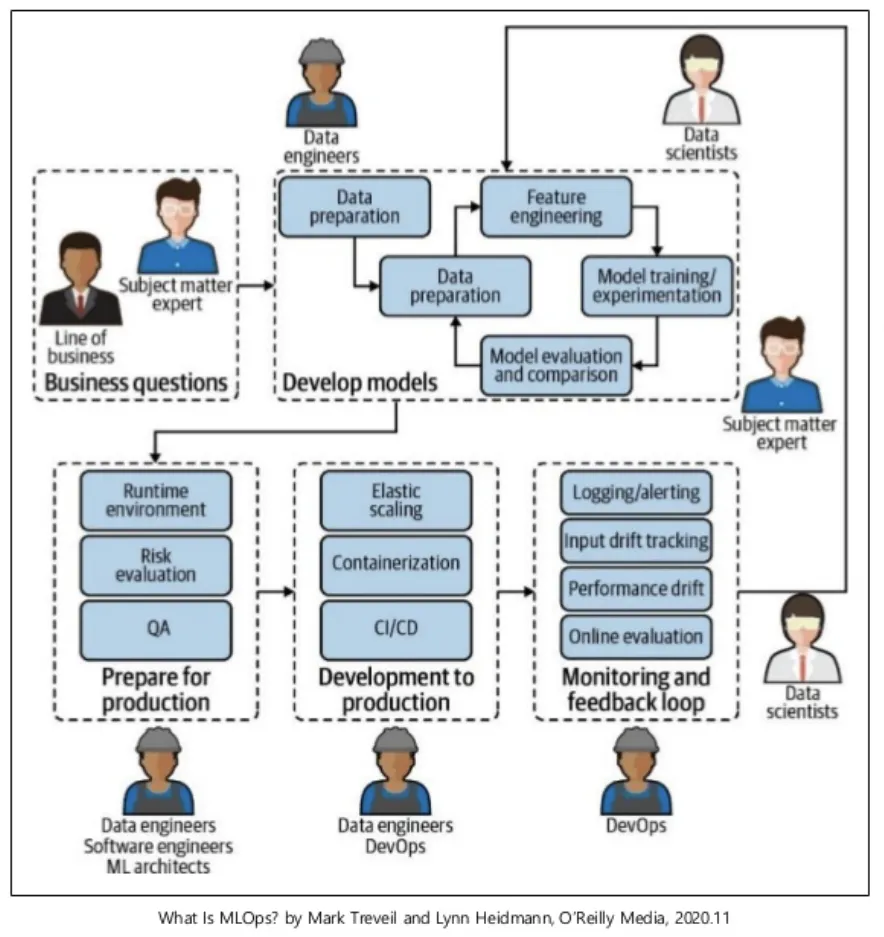
머신러닝 라이프사이클

머신러닝을 활용해서 문제를 해결하기 위한 전체 과정을 일반화하면 위 그림과 같다.
1.
풀어야 할 문제가 발생한다.
2.
문제를 정확히 정의한다.
3.
데이터를 수집하고 전처리한다.
4.
피처 엔지니어링
5.
모델 학습
6.
모델 평가
•
문제를 정확히 다시 정의한다.
•
데이터를 다시 수집하고 전처리한다.
•
피처 엔지니어링을 다시 한다.
7.
모델을 배포한다.
8.
모델을 서빙한다.
9.
모델을 지속적으로 감시한다.
10.
모델을 유지보수한다.
•
유지보수 과정에서 데이터를 다시 수집해야 할 수 있다.
•
유지보수 과정에서 다시 피처 엔지니어링을 해야 할 수 있다.
그리고 현실

하지만 요즘 머신러닝 모델 개발 방식의 현실은 이렇다.
•
네모 점선박스 안에 있는 부분을 사람이 일일히 하고 있다. but 사람이 할 필요 없는 부분이기도 하다.
•
그리고, 그렇게 훈련시킨 모델 (Trained Model) 을 저장소에 넣어 둔다.
•
저장소에서 하나씩 모델을 꺼내가며 배포한다.
•
그리고 Training Session 과 Serving Session 이 완전히 다른 영역처럼 분리되어 있다.

머신러닝 팀의 구성원
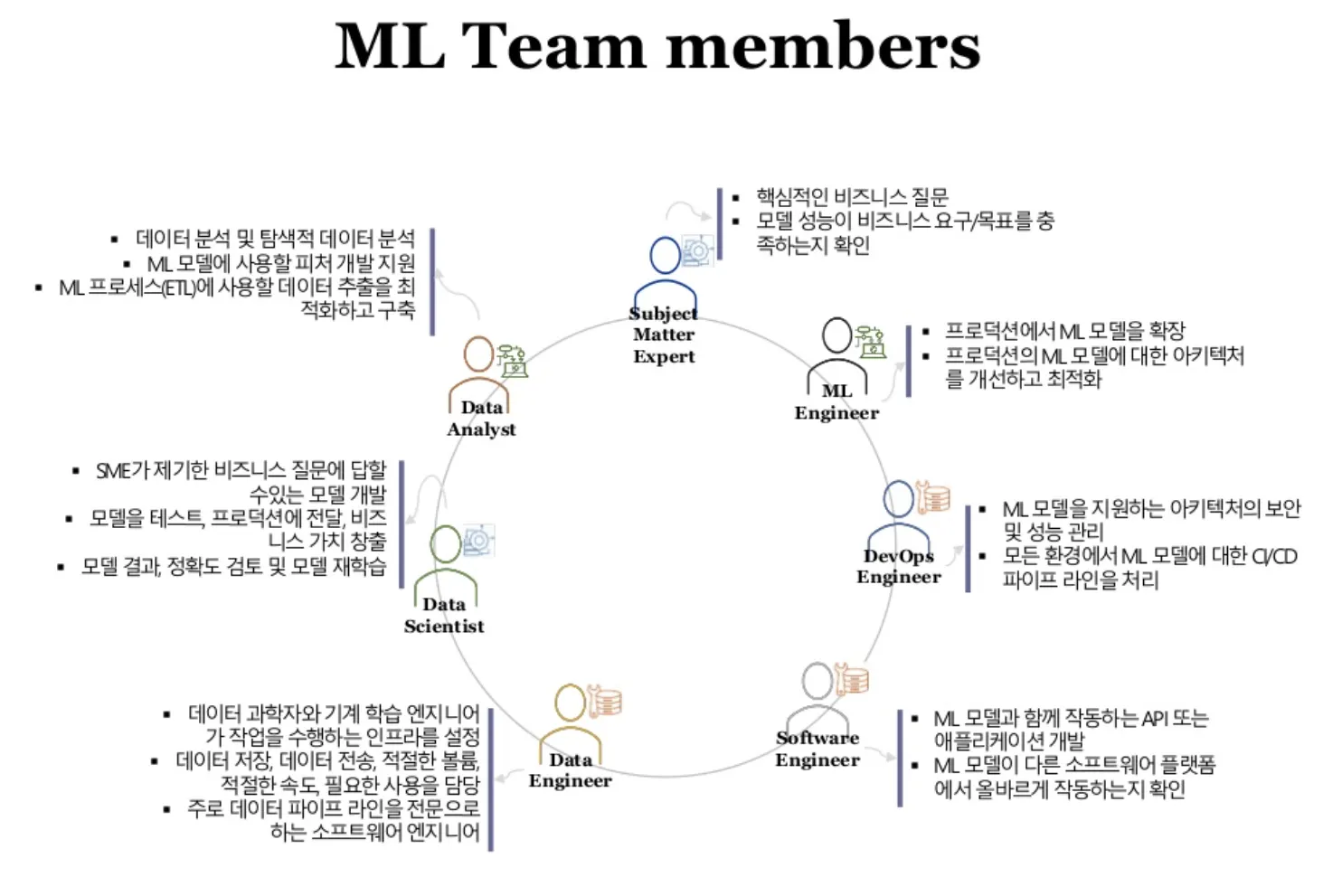

똑같은 그림인데 예쁘게 그린거~
하나의 머신러닝 팀은 이렇게 구성된다.
•
도메인 문제 전문가 (SME) : 풀려고 하는 문제의 요구사항을 확인
◦
데이터 분석가 : EDA, 데이터 정제
◦
데이터 과학자 : ML 모델 개발
◦
데이터 엔지니어 : 인프라 설정, 환경 구축, 데이터 송수신 관리
◦
소프트웨어 엔지니어 : ML 모델 API 개발
◦
DevOps 엔지니어 : ML 모델 보안, 성능관리, CI/CD 파이프라인 처리
◦
머신러닝 엔지니어 : 프로덕션 ML 모델 확장, ML 모델 최적화

하지만, 이렇게 하나의 회사에도 정말 많은 팀이 있을 것이고, 이들이 다루는 언어, 이들이 소통하는 방식, 이들의 도메인, 이들의 도구가 모두 다르다. 이게 말이 되는가!
머신러닝 라이프사이클에서 나타난 문제들
•
너무 static 하다. 유연하지 못하고, 유지보수가 어려운 머신러닝 모델 제작과 배포 전반.
•
정말 점점점 많아지는 머신러닝 팀들이 사용하는 언어가 모두 다르다.
MLOps 을 개발하는 회사들
머신러닝 팀의 확장에 대한 요구

그리고 머신러닝 도구들의 발전과 진화

나는 왜 석기시대에 사는가
MLOps 에 대한 요구들
위의 "머신러닝 라이프사이클" 등에서 보았듯,
MLOps 가 해결해 주어야 하는 내용을 크게 추상화하면 아래와 같다.
•
CI : Continuous Integration
•
CD : Continuous Delivery
•
CT : Continuous Training
•
CM : Continuous Monitoring
MLOps 의 정의
•
머신러닝 라이프사이클에서, 데이터 과학자와 실질적으로 회사의 도메인 업무를 처리하는 사람 사이에서 협업과 소통을 도와주는 도구.
•
머신러닝 프로덕트의 질을 높이고 자동화되는 비율을 높인다.
•
머신러닝, DevOps, 데이터 엔지니어링이 MLOps 의 뼈대를 이룬다.
이것을 사용하면 뭐가 좋은가
•
강력한 기계학습 수명주기 관리를 통해, 신속한 혁신
•
재사용 가능하고, 쉽게 재현 가능한 모델의 생성
•
적절한 위치에 좋은 모델을 쉽게 배치
•
전체 머신러닝 수명주기를 효과적으로 관리
•
머신러닝 리소스를 쉽게 관리하고 제어

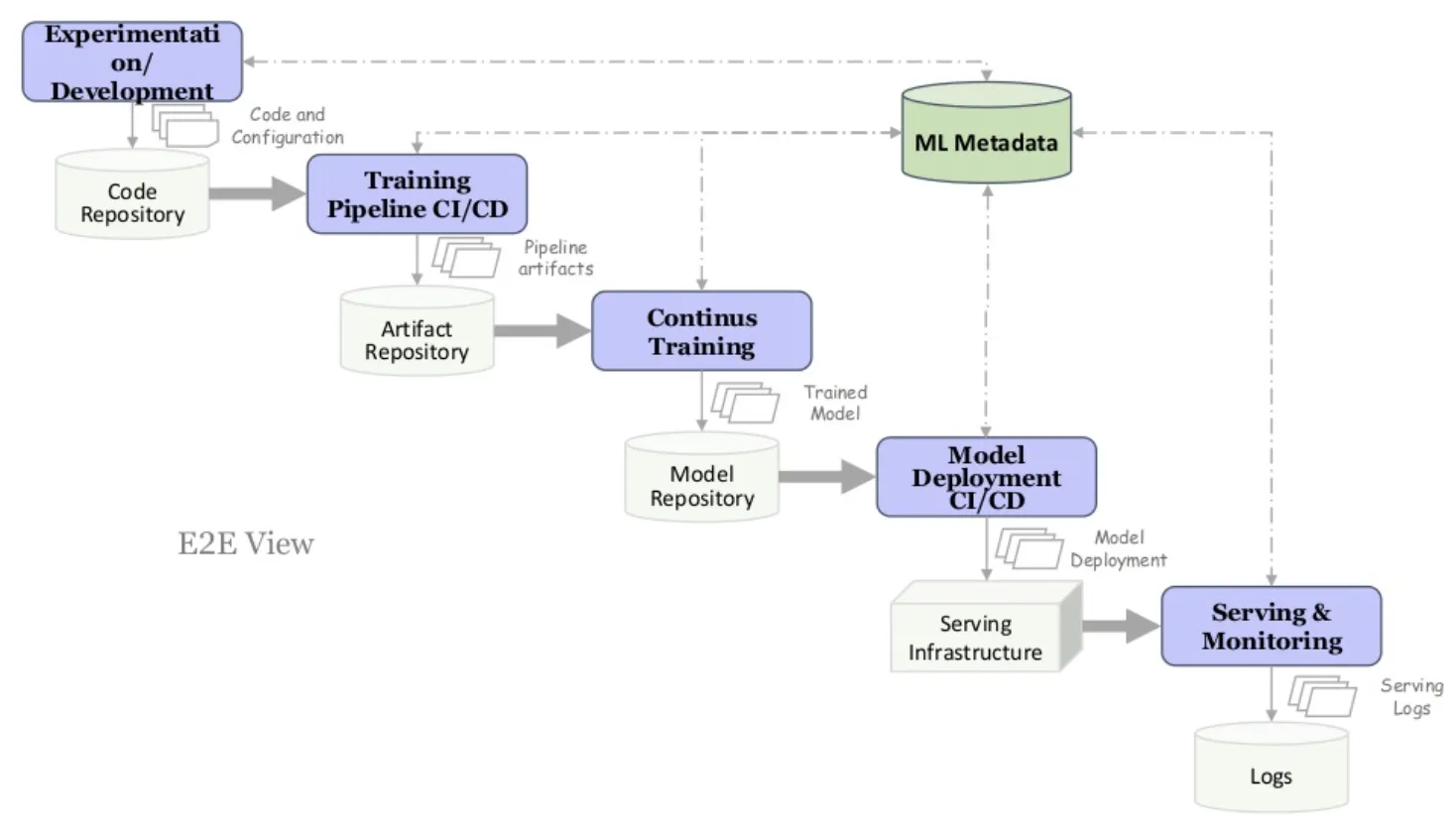
MLOps 의 핵심 컴포넌트들
모델을 한두번 학습시켜 보고, 배포해본 사람들은 이런 과정들이
상당히 손이 많이 간다는 사실을 알고 있을 것이다.







MLOps 의 성숙도에 따른 구분
자율주행차량도 level 에 따라 나누고, 이를 자율주행차의 기술성숙도를 판단하는 기준으로 삼듯이
MLOps 도 이와 같은 맥락이라고 할 수 있다.
Google 의 MLOps 가이드라인의 성숙도 기준

MS Azure 의 MLOps 성숙도 기준

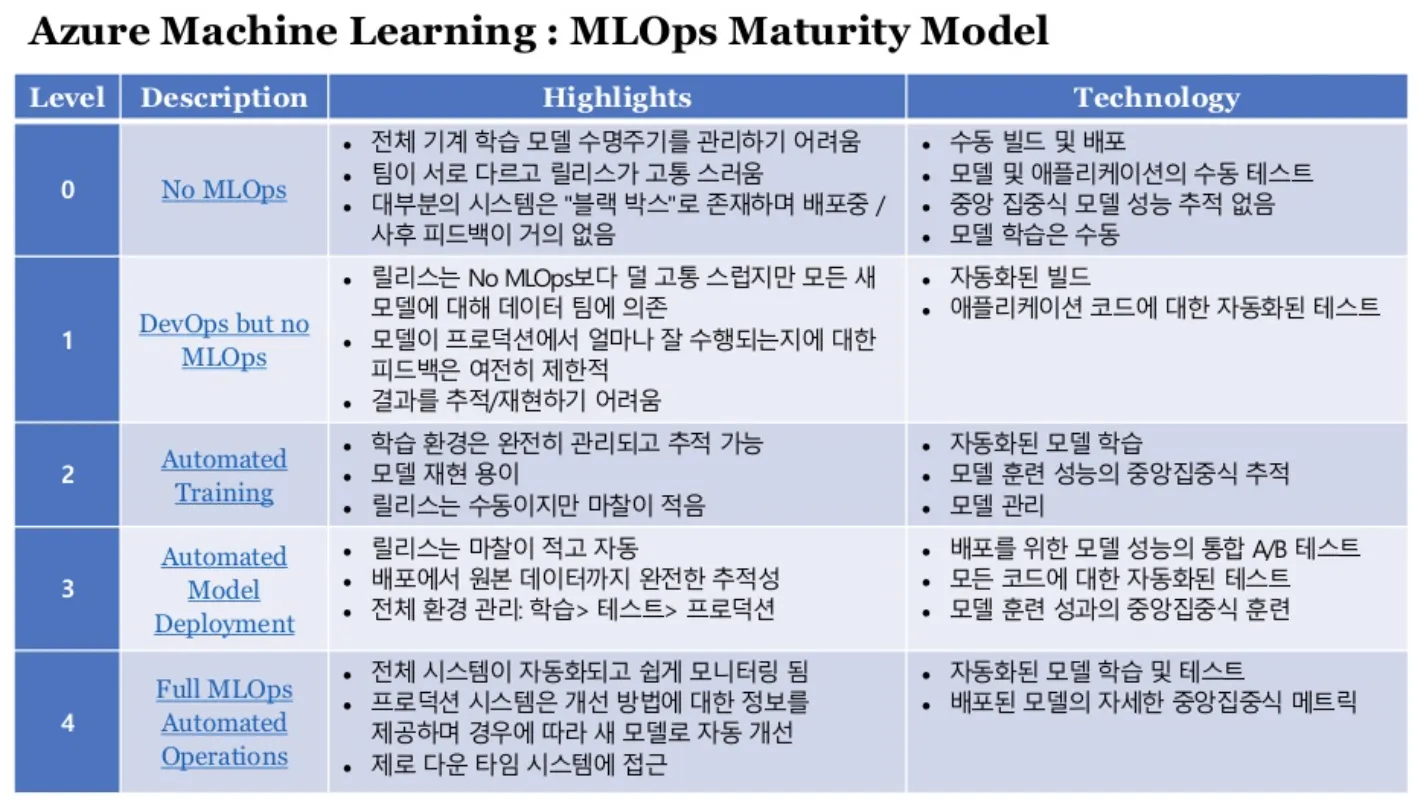
위에서 우리가 보았던 두 개의 머신러닝 서비스 라이프사이클과 MLOps 가 도입된 상황을 그림으로 비교해 보자.


단순화하면

이 단순화된 그림에서 왼쪽, Training 에 MLOps 가 적용되는 그림을 보자.

이 단순화된 그림에서 오른쪽, Serving 에 MLOps 가 적용되는 그림을 보자.

MLOps Level 0
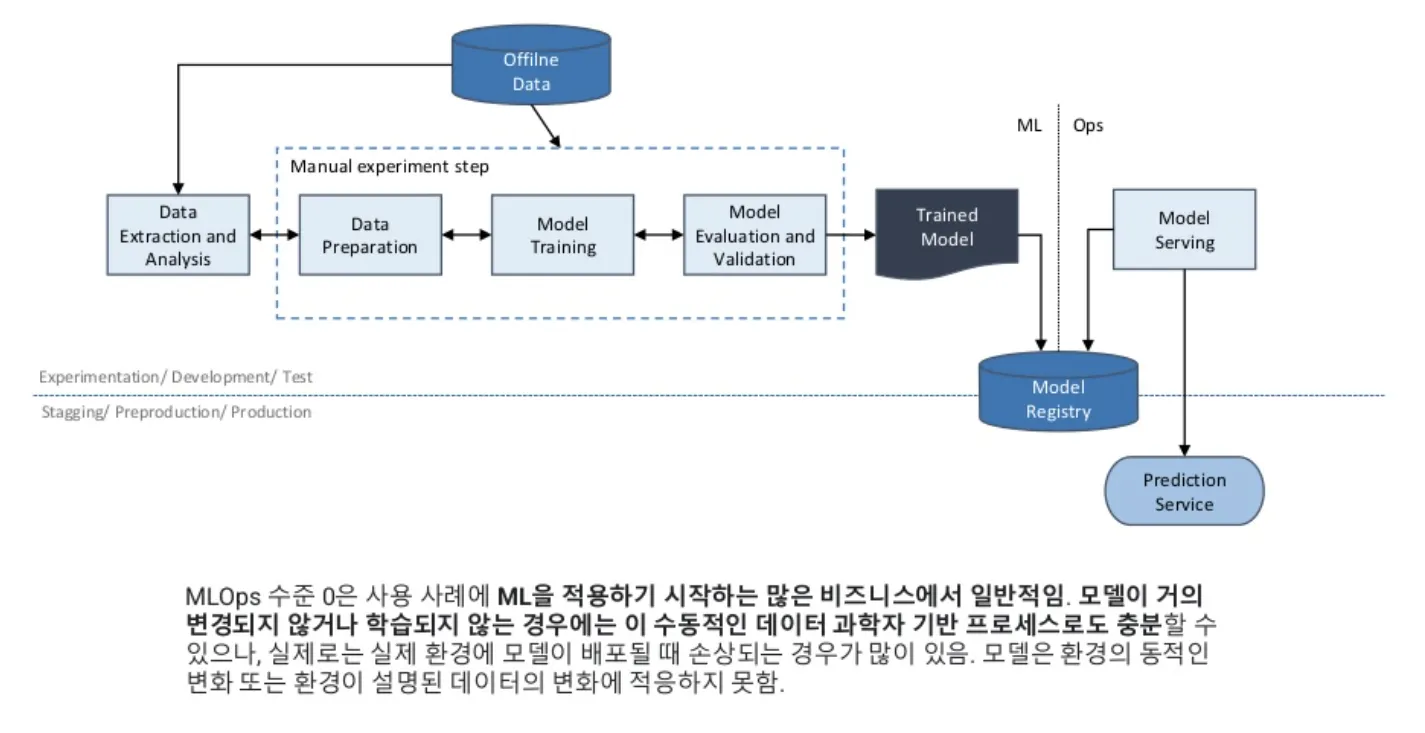
'아무것도 없는, 그리고 "그냥 대학생이 프로젝트를 한다고 했을 때 처리하게 되는 상황" 이다.
즉, EDA 를 한 뒤 이런저런 파라미터들을 실험해 보며, 구조를 바꿔 보고 모델의 실험을 엑셀로 관리한다.
그냥 일반적인 대용량 저장장치나 클라우드 저장소에 모델을 보관한다.
이러한 모델들 중 마음에 드는 것을 올려 사용하지만 대부분은 사용하지 않는다.
MLOps Level 1

•
CI : Continuous Integration
•
CD : Continuous Delivery
•
CT : Continuous Training
•
CM : Continuous Monitoring
MLOps Level 2
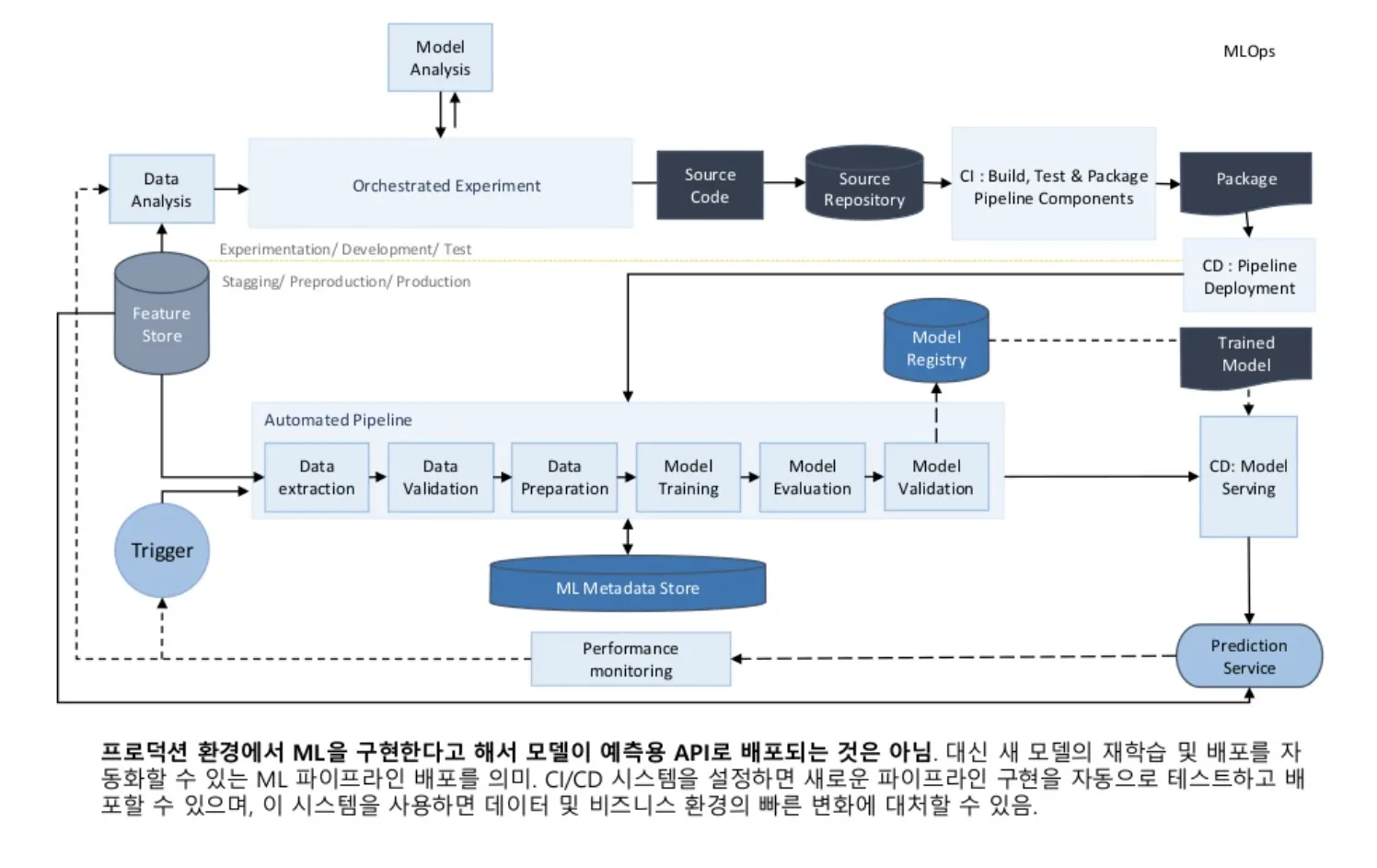

•
CI : Continuous Integration
•
CD : Continuous Delivery
•
CT : Continuous Training
•
CM : Continuous Monitoring
여기까지의 내용을 어느정도 이해했다면, 아래 그림에서 눈에 들어오는 내용이 있을 것이다!
기계학습 모델 운영 관리 솔루션의 핵심 구성 요소들과 그 기능들

인터뷰
인터뷰이를 소개합니다! 어떤 일을 하고 계시는지, 간단한 소개를 부탁드릴게요!
안녕하세요. 서기원입니다.
저는 세종대학교 컴퓨터공학과 14학번으로, 작년에 학교를 졸업 했고
현재 회사에서 5개월 차 재직 중이예요.
(저는 저를 구글링과 구걸링으로 성장 중인 데린이라고 소개하고 싶습니다)
)직무적으로는 '데이터 엔지니어'의 직무를 갖고 있는데,
데이터 엔지니어링의 업무만을 하고 있지는 않고,
데이터 엔지니어링, 데이터 분석, 데이터 시각화 전반의 업무를 배우면서 하고 있어요. (일이 많다는 뜻입니다 ㅎㅎ)
세부적으로 말하면 웹 개발도 하고, 데이터 마이그레이션도 하고, 데이터 분석도 하고, 플랫폼 개발도 하고, 운영도 하고, 데이터 시각화도 하고 하루종일 쿼리도 날리고 ... 정말 데이터로 할 수 있는 모든 업무들을 하고 있어요.
데이터가 생성 되고, 데이터를 기반으로 의사 결정자들이 의사 결정을 내리게 되기 까지 싸이클의 전반을 겪으면서 느끼는 바가 많은 요즘이예요.
데이터 == csv 라고 생각하던 과거에 비하면 많이 성장 했다고 생각 합니다!
앞서 장후가 잘 정리 해 준 내용이나,
아래에서 제가 언급 할 내용들에 있어서
만약 처음 접하는 내용이라면 다소 추상적으로 느껴질 만한 표현들이 많이 등장할 수도 있다고 생각해요!
만약 그런 부분이 다소 낯설게 생각 되신다면 절대 벽을 두지는 마시고 아... 이런 것도 있구나 이 정도로 가볍게 보시는 걸 추천 드립니다!
아아, 그리고 절대적인 것은 없습니다.
5개월차 데린이는 이런 생각으로 이런 일을 하고 있구나...
이 정도로 생각하시고 가볍게 봐 주세요!
위 내용의 MLOps 에 대한 설명은 충분히 현실의 문제와 현재 MLOps 의 개발 방향을 잘 표현한 것 같나요? 없거나 부족한 내용이 있다면 추가해주시면 감사하겠습니다.
전반적인 내용은 장후가 잘 정리 해 준 것 같아요!
그런데 항상 절대적인 것은 없고,
회사 마다, 팀 마다, 파트 마다, 프로젝트 마다 성격이 다르기 때문에 하나의 팀 안에서도 프로젝트마다 개발 방향이 달라질 수가 있어요.
어떤 리더는 모델의 성능을 너무나도 중요하게 생각 할 수도 있고,
어떤 리더는 서비스화 하는 것을 너무나도 중요하게 생각 할 수도 있고,
어떤 리더는 거버넌스적인 측면을 너무나도 중요하게 생각 할 수도 있고,
어떤 리더는 데이터 적인 측면을 너무나도 중요하게 생각 할 수 있어요.
(그렇기 때문에 어떤 조직에 속하더라도 항상 절대적이라고 생각하지 말고, 의심 하는 것이 중요하다고 생각해요. 지금 제가 말하는 모든 것도 의심 해 주세요!)
제가 지금 진행하고 있는 프로젝트를 기반으로 앞선 내용을 조금 수정 하자면,
데이터를 활용해서 프로젝트를 진행 할 때 저희 팀은 아래의 과정을 거칩니다!
(아, 아래 과정을 말씀 드리기 전에 저희 회사의 특성을 먼저 이해 해야 할 것 같아요. 저희 회사는 여러 법인, 여러 계열사로 분리 되어 있어서 각각 계열사 별로 다른 상품/서비스를 제공 하고 있어요. 저희 팀은 그룹사에 소속 되어 있어서 각각 계열사의 분들을 '현업'이라고 칭하고 있습니다.)
1. 풀어야 할 문제가 발생한다.
2. 문제를 정확히 정의한다.
•
이 과정에서 '현업' 분들과 데이터에 대한 도메인 지식을 맞추기 위해 매주 회의를 하게 됩니다. 분명 현업들 만이 갖고 있는 데이터에 대한 지식이 있고, 그들이 정의하는 부분이 있어요. 그런데 현업 분들은 종종 당연하다고 생각하거나 혹은 무언가의 이유에 의해 감추는 경우가 있어요. 현업 에게서 데이터의 '모든 부분'을 캐 내야 합니다.
•
이 부분이 제대로 되어야 데이터 분석을 '추상적으로' 하지 않을 수 있어요.
3. 데이터를 수집한다...
•
이 과정에서 거버넌스적인 측면을 고려하게 돼요. '데이터'는 '돈' 이예요. 데이터 안에 고객에 대한 모든 정보가 들어 있고, 데이터 안에 현업 분들의 모든 실적 정보도 들어가 있어요. 그렇기 때문에 데이터를 수집하는 과정에서 현업 분들은 데이터를 주기 싫어 할 수도 있어요. 이 과정에서 팀장님들께서 굉장히 열일 하십니다. 여기 저기 다니면서 현업 분들을 충분히 설득하고, 회사 내부의 정책을 고려하고, 보고하고, 그런 과정을 통해서 데이터에 대한 접근 권한을 얻을 수 있어요.
4. 데이터를 수집한다...
•
데이터에 대한 접근 권한을 얻은 이후에는 분석을 위한 판을 만들기 위해 정말 열심히 쿼리를 날리게 돼요. 접근 권한을 가진 DB의 모든 테이블에 접근해서 스키마, 컬럼, 데이터 타입, min, max, 설명을 정의하고, 몇 주간 쿼리를 날리며 데이터를 탐색하고, 판을 구성하게 돼요.
5. 데이터를 저장한다.
•
레거시에 존재하는 데이터를 퍼블릭 클라우드로 마이그레이션 합니다.
•
이 과정에서 절.대.로 데이터가 유실 되거나, 밖으로 세어 나가거나, 정합성이 맞지 않거나 그런 사태는 절.대.로 일어나면 안됩니다!! (철컹철컹)
6. 현업과 정의한 문제를 해결하기 위한 작업을 합니다.
•
모델이 될 수도 있고,
•
시각화가 될 수도 있고,
•
지표가 될 수도 있고,
•
테이블 형태의 결과를 보여줘야 할 수도 있고,
•
웹을 만들어야 할 수도 있어요.
•
(한 프로젝트에서 이 모든 것을 해야 할 수도 있습니다!)
7. 현업에게 결과를 납득 시킵니다.
8. 운영을 하거나 프로젝트를 중단 시킵니다.
MLOps 를 공부하다 보면, 가장 많이 등장하는 단어는 "파이프라인" 이 아닐까 싶습니다. 이 "파이프라인" 에 대해서 있는 내공껏 알기 쉽게 설명해 주신다면, 어떻게 설명하는 것이 좋을까요? 이것이 무엇을 하는 과정이고, 구체적으로 무엇을 의미하는지 알려주세요!
업무를 진행 하면서,
이 세상 모든 것이 파이프라인이라는 생각을 하게 되었어요.
무언가를 계속 생각 하다 보면 이 세상 모든게 그것과 연관 되어 보이잖아요,
저는 예전에는 아, 이 세상 모든 것은 데이터구나 이런 생각을 하다가
요새는 아, 이 세상 모든 것은 파이프라인 이구나 라는 생각을 하고 있어요.
(그렇다는 것은 아니고, 그만큼 파이프라인을 많이 생각 하게 된다는 뜻입니당)
'파이프라인'이라는 단어도 추상적으로 들릴 수 있지만,
이 세상 모든 것은 파이프라인이예요.
예를 들어서, 제가 회사에 가는 과정 까지는 이러한 파이프라인을 거쳐요.
1.
핸드폰 알람을 확인 합니다.
2.
6시 50분쯤 일어나서 씻습니다.
3.
준비를 다 하고 나와서 초록 버스를 탑니다.
4.
빨간 버스로 갈아 탑니다.
5.
회사에 도착 합니다.
정말 이 세상 모든게 파이프라인이지 않은가요...? (설득 당해 주세요)
데이터에서도 모든 것이 파이프라인이예요.
'파이프라인'을 무언가 정형화 된 것이라거나, 추상적이라거나, 혹은 어려운 개념이라고 생각하지 않으셨으면 좋겠어요!
프로젝트마다
데이터를 준비하는데 필요한 과정들이 있을 것이고, 그 것은 데이터를 준비 하는 파이프라인이 됩니다.
데이터를 엔지니어링 하는 데 필요한 과정들이 있을 것이고, 그 것은 데이터를 엔지니어링 하는 파이프라인이 됩니다.
모델링 하는 데 필요한 과정들이 있을 것이고, 그 것은 모델링 하는 파이프라인이 됩니다.
모델을 배포 하는 데 필요한 과정들이 있을 것이고, 그 것은 데이터를 배포 하는 파이프라인이 됩니다.
이러한 파이프라인들이 모여서 파이프라인들을 엮는 파이프라인이 만들어 집니다...
(모든 것은 파이프라인 맞죠..? 설득 당해 주세요)
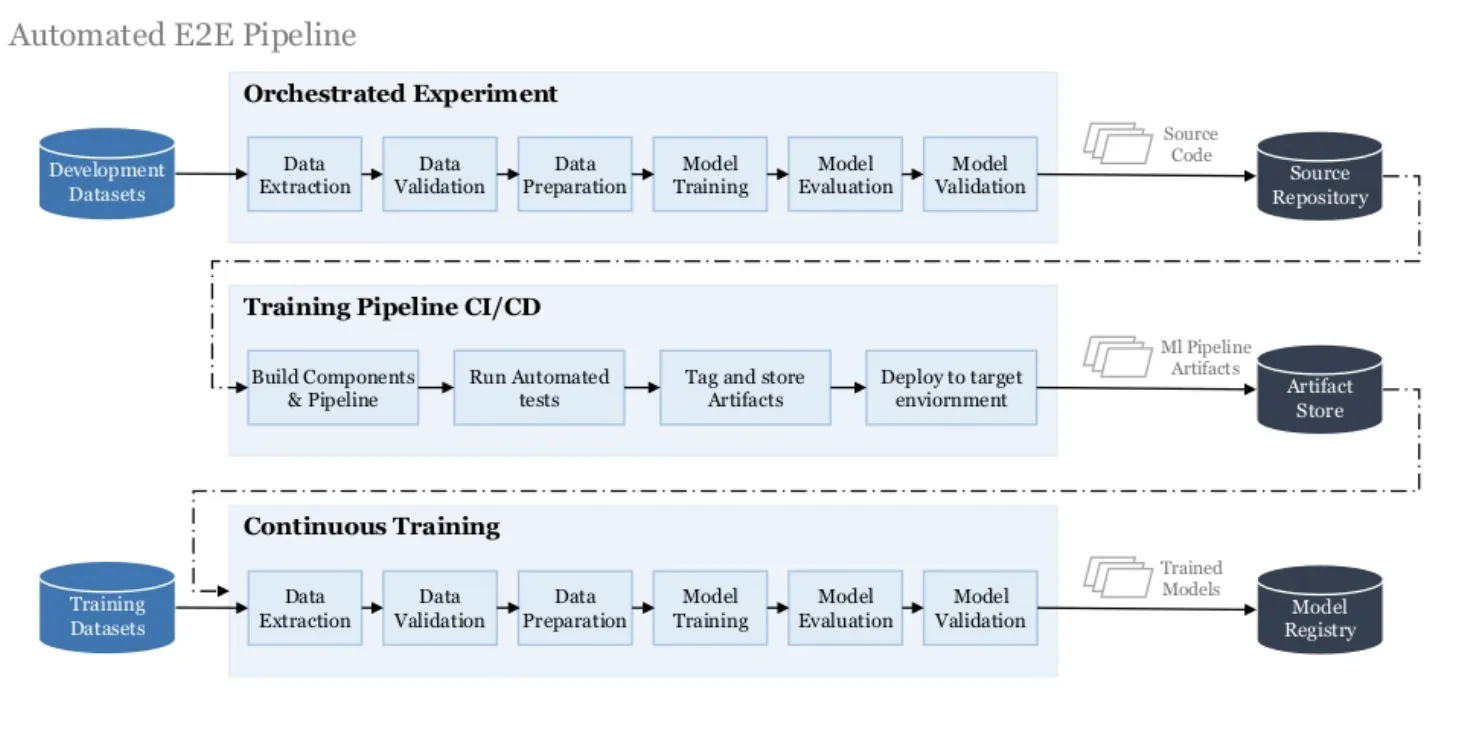
아래 그림에서, Source Repository 는 무엇을 의미하고, Artifact Store 은 무엇을 의미하나요? 조금 더 실질적인 예를 들어 주시면 이해하는 데 더 좋을 것 같다는 생각이 듭니다.

•
소스 레포지토리는 쉽게 생각하면 Git이예요!
회사의 정책, 규칙 혹은 팀 내부의 규칙에 따라 소스 레포지토리로 Git, AWS CodeCommit, 회사 내부 공유 폴더 등 다양한 방법을 이용합니다.
•
Artifact Store는 Artifact들을 저장하는 곳인데,
Artifact는 모델 그 자체가 될 수도 있고,
모델/데이터를 저장하는 경로가 될 수도 있고,
모델에 대한 info 정보가 될 수도 있고,
파이프라인에 대한 info 정보가 될 수도 있어요!
아래 표의 내용도 상당히 어려운 터미놀로지들이 많이 들어 있습니다. 예를 들어, "파이프라인" 이라던가, "패키지, 실행 파일" 이라던가, 잘 와닿지 않는 용어들인데요, 이것에 대해서 더 설명해주고 싶은 부분이 있으신가요? 너무 방대하다 싶으면 하나만을 딱 잡고 그림을 그려 주셔도 좋고, 간단한 소스코드로 보여주셔도 좋습니다.

MLOps Stage를 이론적으로 공부 하면
단어들이 조금은 추상적으로 느껴질 수 있어서 조심스럽게 되는데,
저희 팀에서 현재 진행하는 프로젝트의 MLOps Stage를 소개 해 드릴게요.
1. 매개변수들을 설정 합니다.
•
전반적으로 사용 할 인스턴스, 인스턴스 갯수 등 여러 세팅 값들을 설정 해요.
2. 전처리 파이프라인을 구성 합니다.
•
저희가 현재 진행 중인 프로젝트는 정형 데이터 이기 때문에, numeric 컬럼과 categorical 컬럼을 각각 전처리 하고, 컬럼 특성 및 분석 목적에 따라서 전처리 해요.
3. 모델 학습 파이프라인을 구성 합니다.
•
베이스라인 모델 및 코드를 구성하고, 모델을 디벨롭 하거나 여러 모델로 실험적인 결과를 도출 해요.
•
베이스라인 모델의 경우 SageMaker의 AutoPilot을 이용해서 고려 하기도 합니다!
4. 모델 평가 파이프라인을 구성 합니다.
5. 컨디션 파이프라인을 구성 합니다.
•
모델 평가의 결과에 따라 모델을 저장하거나, 혹은 저장 하지 않습니다.
6. 모델을 배포 합니다.
7. 모델을 모니터링 합니다.
•
현업에는 계속 해서 새로운 데이터가 쌓이기 때문에 모델의 성능을 주기적으로 확인 할 필요가 있어요.
유명한 도메인의 예를 한번 가져와보고 싶은데요, 테슬라의 예를 한번 들어 봅시다.
테슬라도 당연히 처음에는 제한적인 데이터를 가지고 '라벨링' 을 한 뒤, 이 데이터를 바탕으로 모델을 학습시켰을 겁니다. (a) 그런데 이제는 차에 장착된 수많은 카메라들로부터 데이터를 직접 수집해서 처리하고 있지요.
정확히 말하면, 모든 데이터를 수집하는 것이 아니라, (b) '모델의 예측값' 과 '사람의 제어값' 이 다른 경우에만, 정말 많은 카메라로부터 수집된 이미지를 서버로 전송하는 방식으로 작동합니다. (c) 데이터는 테슬라의 서버에서 모델을 다시 훈련시킵니다.
이러한 과정 (a, b, c) 도 MLOps 에 포함되는 것이라고 볼 수 있을까요? 아래 그림들에 각 과정들을 대입하여 설명해 주시면 좋겠습니다. 추가적인 설명을 해주고 싶은 부분들이 있다면 얼마든지 해 주셔도 좋습니다.


tesla 의 data engine
는 판단을 함부로 할 수 없다고 생각하셨고, 답변을 유보해 주셨습니다! 나중에는 꼭 답변해 주실거죠? 위 테슬라의 이야기에서 MLOps 에 해당하지 않는 내용이 있다면 그것은 무엇일까요?
제가 다니는 회사는 물론 대부분의 회사가 MLOps 를 직접 구현해서 사용하기는 인적, 재정적, 자원적 인프라가 많이 부족합니다. 그리고, MLOps 기술이 아직 많이 성숙하지 않아 외부 대기업 솔루션은 물론 국내 벤처들이 개발하는 솔루션도 과연 믿고 사용할 수 있을지가 의문이에요.
조금만 더 실질적인 조언을 위해서 특정한 상황을 가정해 볼게요.
"머신러닝 라이프사이클 전반 (데이터과학, 머신러닝 엔지니어링 전반) 을 담당하는 엔지니어가 딱 두 명인 팀이 있습니다. 이 팀은 전국 100대의 CCTV 로부터 1분당 1장의 image 를 받아와서 전국 100대의 CCTV 에 50MB 정도가 되는 모델을 업데이트해야 합니다."
Q1. 과연 1단계 이상의 MLOps 가 효율적일까요? 아니면 Level 0 MLOps 라고 볼 수 있는 구글 스프레드시트를 통한 모델 실험과 간단한 스크립트를 통한 수동 배포가 더 효율적일까요?
Q2. 그리고 특정 MLOps 정도가 효율적이라고 생각한다면, 어떤 근거로 그것이 더 효율적이라고 생각하시나요?
SAI 친구들이 모델을 약 10개정도 만들었고, 웹 서비스를 만들어서 예측 시스템을 만들었습니다. 이 학생들이 MLOps 솔루션을 도입해 보고 싶어한다고 생각해 봅시다. 어떤 것을 먼저 건드려 보라고 조언하시겠어요?
MLOps 솔루션을 도입 하기 전에 MLOps의 필요성을 인지하고,
실제적인 서비스들을 이용 해 보며 이해 해 보는 것이 좋을 거라고 생각해요!
AWS SageMaker Autopilot이나 DataRobot 이런 서비스들을 경험 해 보면
조금 더 쉽게 방향성을 찾을 수 있지 않을 까 싶어요!
(과금이 발생 할 수 있습니다)
)SAI 친구들이 급기야 정신을 못 차리고 이제 MLOps 를 구현하려고 합니다. 이 친구들은 대단하게도 데이터베이스, 분산처리, 운영체제, 컴퓨터구조, 자료구조, 네트워크에 대해 아주 간단한 학부 수준의 선수지식이 어느 정도 갖추어진 상태입니다. 이 친구들에게 무엇을 해 보라고 조언하시겠어요? 몇개월정도 어떤 것을 해 보고, 이런 키워드로 서칭을 해 보아라 라는 식의 조언도 좋고, 입문하기 좋은 책을 추천해 주셔도 좋아요.
저는 기본적으로 데이터 엔지니어의 입장 이라서,
데이터를 수집, 저장 하는 단계 부터 시작 해 보는 게 좋은 것 같아요.
캐글 같은 대회에서 제공 받는 csv 데이터가 아닌
예를 들어서 웹을 만들었다고 하면, 웹에서 발생하는 로그성 데이터 일 수도 있을 것이고,
혹은 GA로 데이터를 저장 할 수도 있을 것이고,
혹은 크롤링으로 데이터를 얻을 수도 있고...
나만의 데이터를 수집 한 이후에 이 데이터를 어떻게 저장하고 관리 할지 고민 하고,
쿼리도 많이 날려 보고,
어떤 분석을 통해 어떤 결과를 배포 할지 고민 하고,
모델을 어떻게 모니터링 할지 고민 하고,
플랫폼에 반영하고 디벨롭 해 나가면
무언가 멋진 결과가 만들어져 있지 않을까 생각합니다! :)
감사합니다!
인터뷰를 끝마치며 한 마디만 더 하겠습니다!
모든 사람들에게 SAI의 의미가 다 다를 것이라고 생각 하지만,
저는 제가 지식이 너무나 부족하다고 생각 했을 때
제게 너무나도 필요 했던 커뮤니티가 SAI 였어요.
데이터를 다루는 '대학생'만이 가질 수 있는 생각, 걱정, 고민이 있을 거라고 생각합니다.
저도 그런 과정을 거쳐 왔구요.
여러분들에게도 SAI가 그런 생각, 걱정, 고민을 같이 할 수 있는 커뮤니티가 되길 기원합니다!
Reference





Additional study source




Reference : Chun MK
chunmk80@gmail.com

Interviewee : Kiwon Seo
Interviewer / Writer : Janghoo Lee
dlwkdgn1@naver.com
