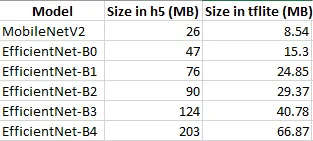
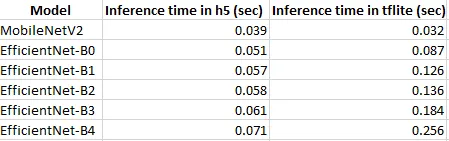
The inference time for MobileNet dropped for the Tensorflow Lite model as expected but it increased for the EfficientNet models. Tensorflow Lite should make the models smaller and decrease inference time! So why is this happening? This is cleared up in EfficientNet Lite which has the following changes. (1) Removed squeeze-and-excitation networks since they are not well supported (2) Replaced all swish activations with RELU6, which significantly improved the quality of post-training quantization (3) Fixed the stem and head while scaling models up to reduce the size and computations of scaled models (표)