
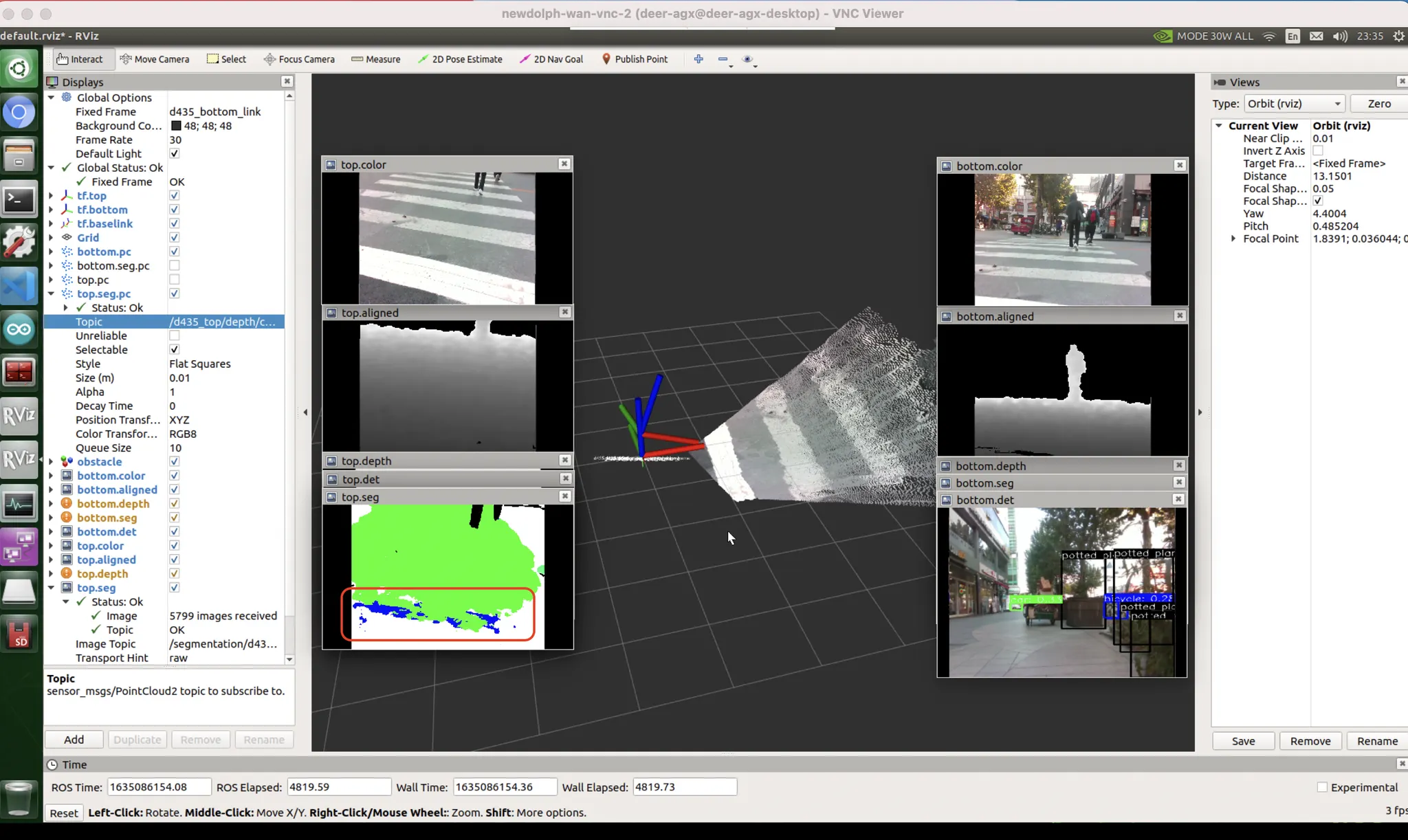
아래 화면의 좌측 세 개의 영상을 보자. 가장 위에는 rgb,중앙에는 depth, 가장 아래에는 rgb 영상에 대한 semantic segmentation 의 결과물이 나타나 있다. 이렇게 인간이 보기에도 애매해서 유추하기 어려워 보이는 영역들이 존재한다. 사람조차도 저 단일 프레임만 보고서는 저 부분이 횡단보도의 일부인지, 도로의 일부인지, 인도의 일부인지 파악하기 어렵다.
루돌프 작동 화면

성수동 소재의 횡단보도. 붉은 테두리로 둘러싸인 영역은 과연 ‘인도’ 일까? ‘횡단보도의 일부’ 일까? ‘차도’ 일까?
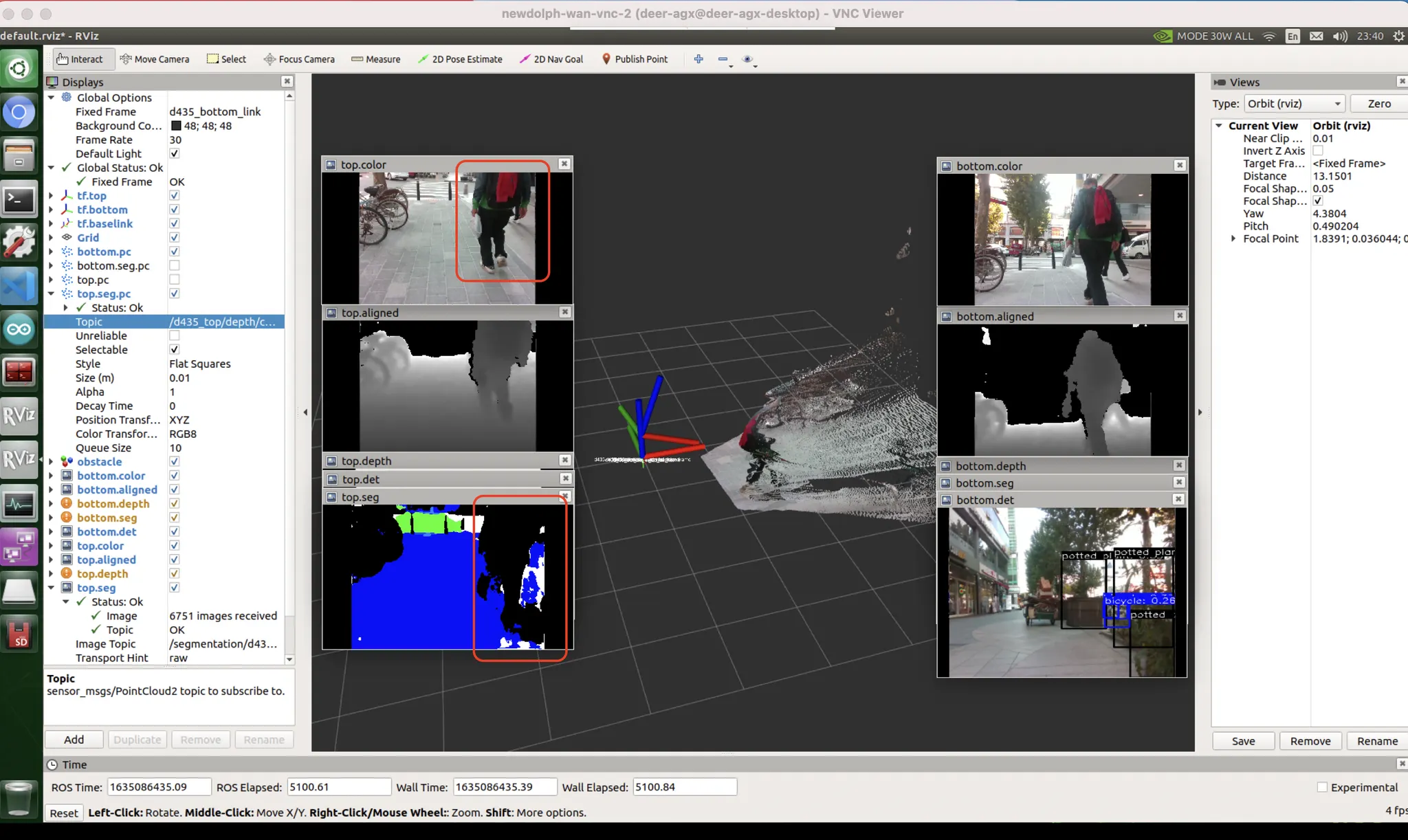
또 비슷한 사례이다. 인간도 아래 영상 속 사람이 가리고 있는 영역의 뒷부분의 구조가 어떻게 생겼는지 알기 어렵다. 사람이 가리고 있는 영역의 뒷부분을 올바르게 추론하려면 애초에 데이터셋이 가려진 부분을 ‘짐작’ 해서 처리할 수 있도록 레이블링되어있어야 하고 (참고1), 이전 프레임으로부터 정보를 얻어올 수 있도록 네트워크가 구성되어야 한다.
이게 real world 다 마!
비디오가 아니라 단일 영상을 바탕으로 추론하는 우리 시스템 특성상, 사람이 가려버리는 바람에 볼 수 없게 되는 이런 영역들은 "미지의 영역" 으로 처리하는 수밖에 없다 (참고:테슬라도 똑같은 문제를 지적했다. 이 문제는 2020년~2021년에 가서야 해결된 듯하다). 이런 것을 단일 영상 추론 모델이 아닌 비디오 기반 추론 모델을 통해 해결할 수 있을 것 같다는 생각이 든다. 저 사람이 가리지 않은 프레임들을 가지고 있고, ego vehicle 의 kinematics 정보를 가지고 있으니까 이 내용들을 적절히 조합할 수 있다면 많은 부분들이 해결되지 않을까? 하지만 현재 디어는 image by image 로 추론하고 있기 때문에 그렇게 하는 것이 불가능하다. 사람이 지나가면서 뒷 정보가 심하게 망가지게 된다. 이 부분을 개선할 필요가 있다. 현재 시점(t) 에서 약 0.5초만 돌아간 이전 시점(t-1) 의 영상을 기준으로 추론한다면 장애물이 잠깐 가리는 occlusion 문제가 발생하더라도 깔끔하게 처리할 수 있었을 것이다.
지금 우리가 사용하고 있는 모델도 이런 추론과정을 거쳤을 것이다.
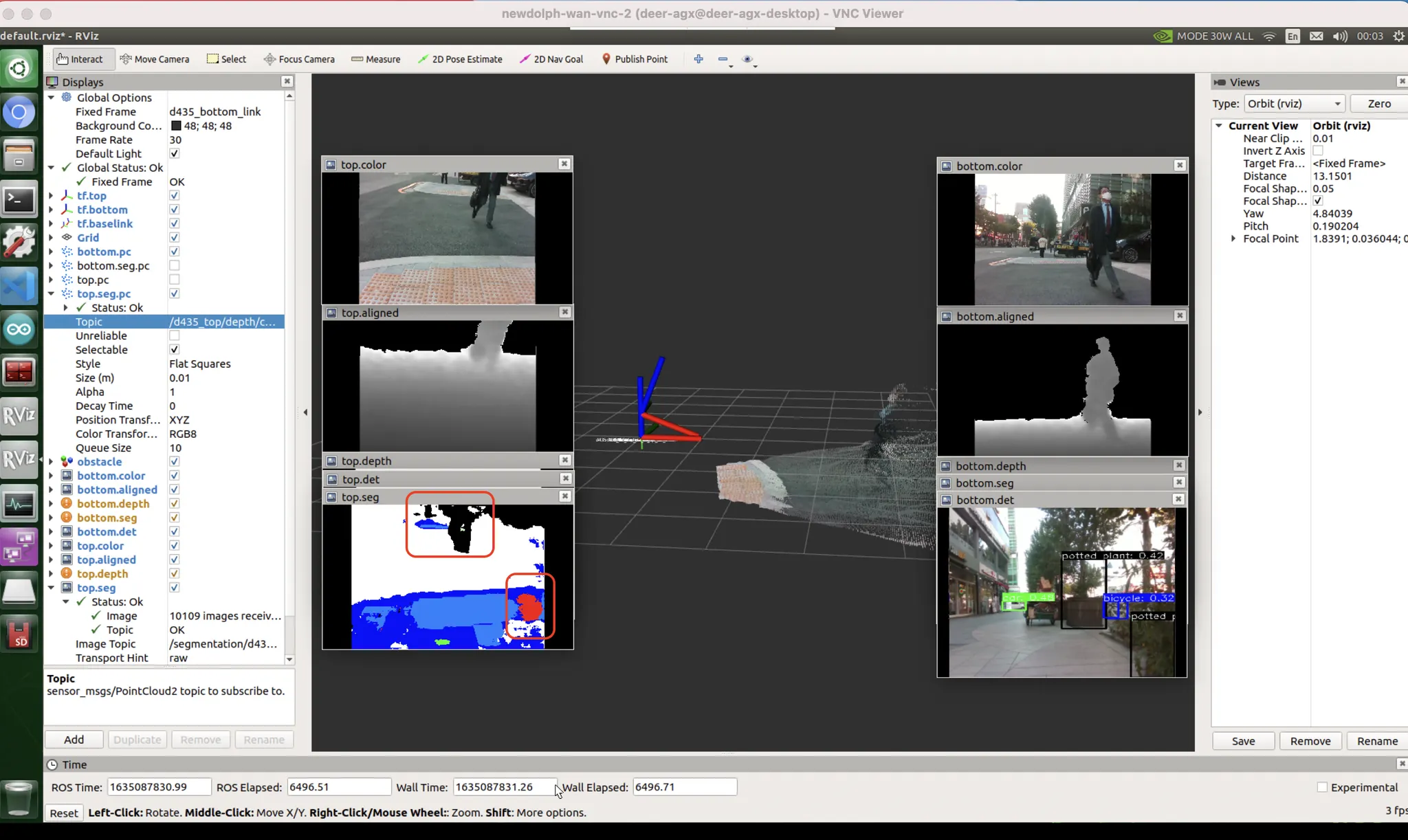
이게 위험지역 픽셀인인가 (51%) ? 흠... 아닌가? 점자블럭 픽셀인가 (49%) ? 에라 모르겠다 위험지역!
따라서, thresholding 으로 일부 해결될 수 있는 문제일지도 모른다 (참고2).
@12/9/2021, 2:41:00 PM 다음 방법을 통해 비디오 딥러닝에 한발짝 더 다가갈 수 있다.
참고