
처음에 사람들은 소켓에 값을 쓰거나 읽을 때, 사람이 읽기 편한 XML이나 JSON을 직렬화/역직렬화했다. 하지만 XML과 JSON을 직렬화/역직렬화하는 일은 느리다. 이를 보완하기 위해 구글에서 만든 직렬화/역직렬화 방법론과 이를 위해 요구되는 데이터 표현 방식을 통틀어 프로토콜 버퍼라고 한다(ref1).
그림(ref3)
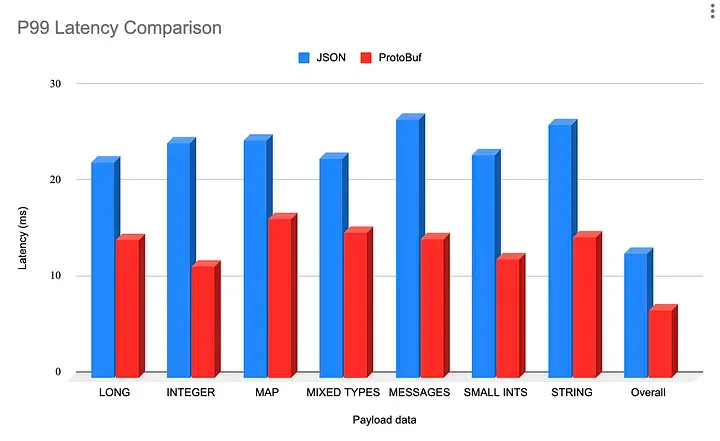
이 글에서는 XML과 JSON을 직렬화하거나 역직렬화하는 일이 프로토콜 버퍼에 비해 왜 느린지에 대해서는 깊이 다루지 않는다(ref3:보다 구체적인 이유들). 하지만 본질적인 이유는 동적 타입 언어가 정적 타입 언어보다 메모리를 많이 사용하고 느린 이유와 비슷할 것이라고 짐작해볼 수 있다(ref2). 직렬화를 위해 기계에게 제공되는 힌트가 많이 없기 때문이다.
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료을 보관해 두는 영역입니다.
1.
None
from : 과거의 어떤 원자적 생각이 이 생각을 만들었는지 연결하고 설명합니다.
1.
•
소켓에 값을 쓰거나 소켓에서 값을 읽을 때에는 파일에 값을 쓰거나 읽는 것처럼 여긴다. 파일에 값을 쓰고 읽는다는 것은 직렬화와 역직렬화가 요구된다는 것과도 같다고 볼 수 있다.
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는지 연결합니다.
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는지 연결합니다.
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되거나 이어지는지를 작성하는 영역입니다.
1.
ref : 생각에 참고한 자료입니다.