문제 1
다음 중 틀린 것을 모두 고르시오.
1. | KNN: 게으른 학습 또는 사례중심 학습이라고 한다. | O |
2. | KNN: 데이터의 차원이 증가하면 차원의 저주 문제가 발생한다. | O |
3. | KNN: 탐색할 이웃의 수(K)가 클 수록 과적합이 발생한다. | X |
4. | KNN: 학습데이터 내에 끼어있는 노이즈의 영향을 크게 받지 않는다. | O |
5. | KNN: 최적 이웃의 수(K)와 거리 척도(distance metric)는 연구자가 실험 결과에 따라 임의로 선정한다. | O |
6. | 의사 결정 나무(DT): 모든 샘플이 한 클래스에 속한다면 지니 불순도는 0이다. | O |
7. | DT: 의사 결정 나무는 지니 불순도를 최대화하도록 학습한다. | X |
8. | DT: 샘플들의 클래스가 균등하게 분포되어 있다면 지니 불순도는 최대가 된다. | X |
9. | DT: 지니 불순도를 통해 의사 결정 나무가 변수 공간을 잘 나누었는지 평가할 수 있다. | O |
10. | DT: 전역 최적을 달성할 수 있는 모델이다. | X |
11. | DT: 나무의 깊이가 깊어질 수록 더욱 복잡한 관계를 표현 가능하다. | O |
12. | 새로운 관측 데이터에 대해 모델이 얼마나 잘 동작하는지를 의미하는 용어를 generalizability라고 한다. | O |
13. | regression 모델은 classification을 수행할 수 없다. | X |
14. | Training data는 feature vector를 포함한다. | X |
15. | precision과 recall을 더하면 항상 1이 된다. | X |
16. | precision과 recall을 산술평균한 값을 F1 score라고 부른다. | X |
17. | 모든 케이스를 positive로 예측하면 recall을 1로 만들 수 있다. | O |
18. | 모델이 랜덤으로 결과를 낸다면 ROC AUC는 0.5가 된다. | X |
19. | ROC AUC의 값이 클수록 일반적으로 더 좋은 분류 모델이다. | O |
20. | 서로 다른 분류 모델을 하나의 수치로 비교하기 위해 ROC AUC가 쓰일 수 있다. | O |
오차 +- 1개까지 정답으로 인정
•
14: 출제 의도가 궁금함.
문제 2+3
문제 2
아래 이미지에 대해 성능 지표 수치를 작성하라.
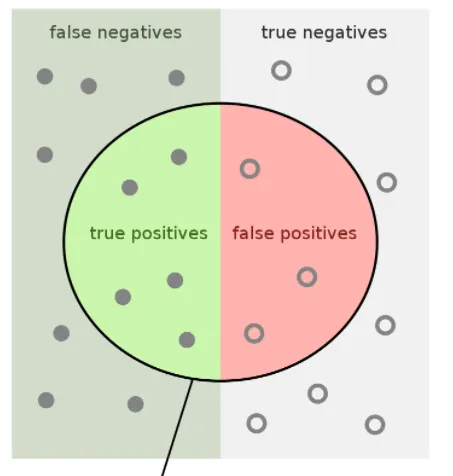
(1) sensitivity: 5/12
(2) specificity: 3/10
(3) negative predictive value: 7/14
(4) precision: 5/8
(5) F1 score:
= 2*(5/8 * 5/12) / (15/24 + 10/24)
= 2(5/8*5/12) / (25/24)
=
= 1/2
(recall: 5/12)
각 0.2점
문제 3
문제 2의 문항에서 등장한 용어들의 의미와 용도를 코로나 관련 논문을 참조하여 서술하시오.
•
sensitivity :
각 0.2점
보너스 문제 
•
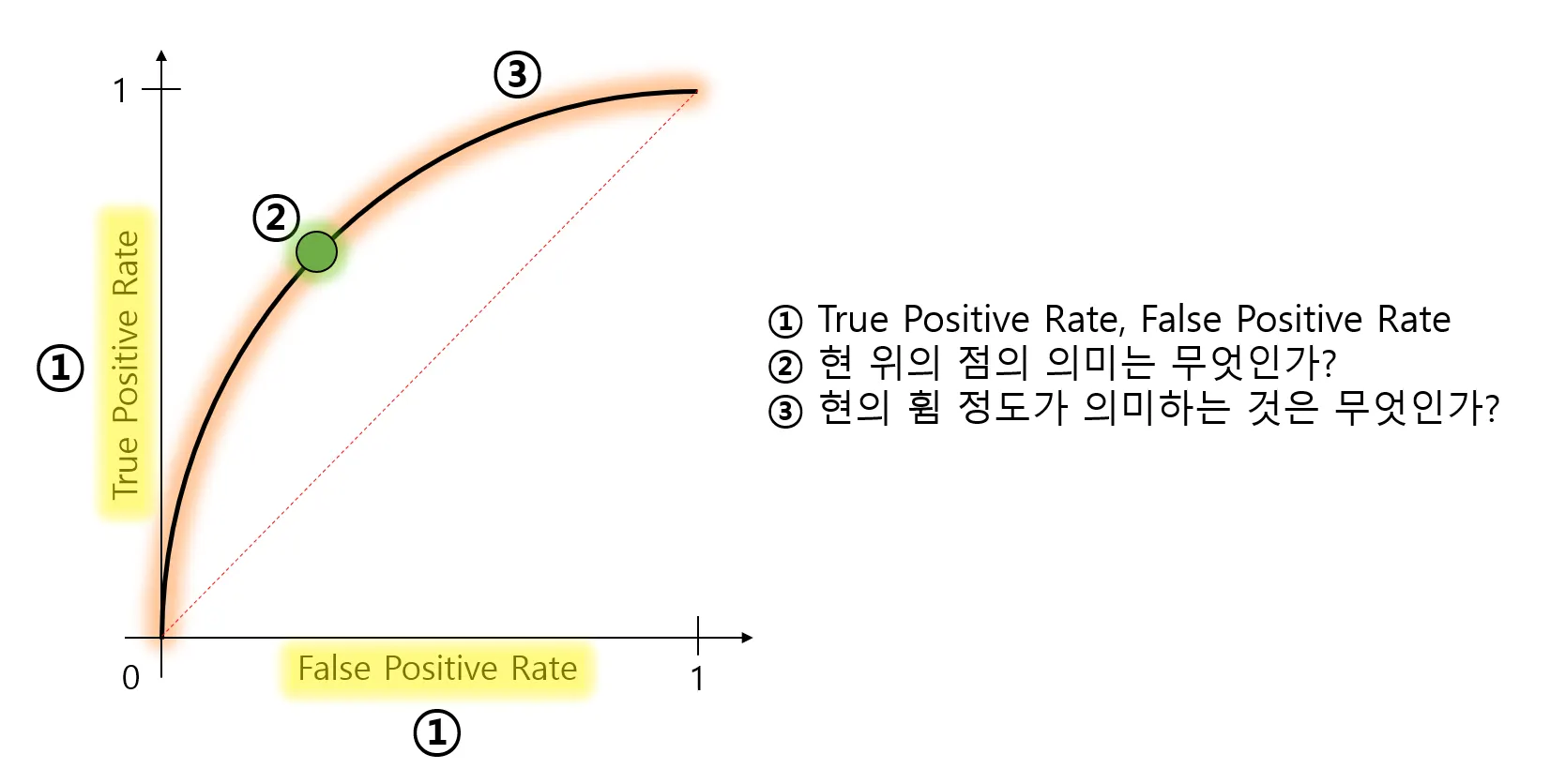
ROC curve의 현 위의 점의 의미는 무엇인가?
◦
어떤 모델의 threshold 를 설정했을 때 특정 FP 를 만족한다면, 해당 모델은 특정 TP 를 만족한다는 뜻.
•
현의 휨 정도가 의미하는 것은 무엇인가?
◦
어떤 모델의 현이 많이 휘었다는 것은 모델의 성능이 현이 덜 휜 모델에 비해 전반적으로 좋다는 것을 의미합니다.
.
찾은 논문에 적용해서 해석해보세요!
문제 4+5
KD-Tree
다차원 데이터 포인터를 공간 분할하는 자료구조
•
Nearest neighbors search
◦
KNN
◦
descriptor matching
•
Recursive partitioning
◦
statistical decision tree
문제 4, 5
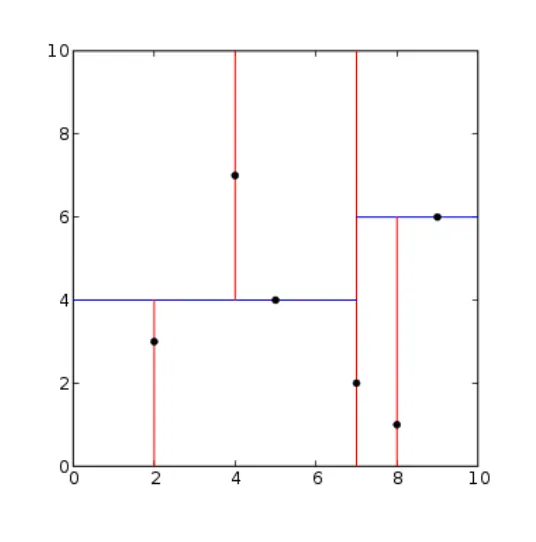
nearest neighbor search, 최근접 이웃 탐색은 주어진 점 세트 내에서 새로운 점과 가장 가까운 점을 찾는 최적화 문제이다. 이 ‘점’은 다양한 형태로 응용될 수 있다. 데이터 문제에서 각 점은 데이터가 된다. 또한 데이터는 다차원 특징으로 구성된다. 새로운 데이터는 가장 가까운 특징에 기반해서 클래스가 결정된다.
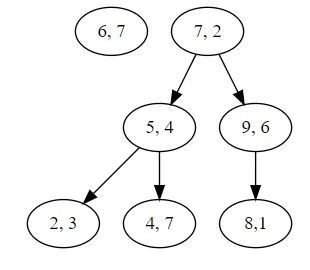
아래의 트리를 통해 탐색 과정을 최적화 해보자.
새로운 데이터: (6, 7)
k-d tree root: (7, 2)
문제 4
다음의 거리 측정 방법을 참고해 새로운 데이터와 기존 데이터와의 거리를 측정하라.
4,7
1.
Euclidean distance
•
아래 표 참고
2.
Manhattan distance
•
아래 표 참고
3.
Minkowski distance
•
p 를 주셔야 하는 것 아닌가요?
6,7 | Euclidean | Manhattan | ? |
7,2 | sqrt(26) | 6 | |
5,4 | sqrt(10) | 4 | |
9,6 | sqrt(10) | 4 | |
2,3 | sqrt(32) | 8 | |
4,7 | 2 | 2 | |
8,1 | sqrt(40) | 8 |
문제 5
새로운 데이터 (6, 7)과 기존 데이터의 k-d tree를 바탕으로 다음을 구하라.
1.
가장 가까운 데이터와의 거리(L2)
a.
2
2.
1번을 탐색하는 순서와 결정 트리의 분기 조건들
a.
(7,2) → (5,4) → (4,7)
3.
결정 경계의 시각화
그 외 생각해볼 문제들
•
(나이, 연봉) 과 같이 스케일의 차이가 큰 특성에 대해서는 L2 거리가 적절한 측정 방식인가? descriptor matcher의 거리 측정 방식은 무엇이 있는가?
•
kd tree는 최근접 이웃을 반드시 찾을 수 있는가?
•
kd tree에서 데이터의 차원이 크면 어떤 일이 발생하는가?
•
트리의 분할 기준은 무엇이 적절한가?
•
최적화를 위한 가지치기는 어떻게 진행되는가?
k-d tree...
피드백 : 재미있는 이야기이고, 이것때문에 문제출제가 오래 걸린 것 아닐까 하는 생각이 들었어. 다만 문제를 결국 출제하지 못해서 너가 생각한만큼 우리가 깊은 뜻을 알아가지는 못한 것 같아. 만약 이걸 문제가 아니라 칼럼으로 재밌게 써봤으면 어땠을까 하는 아쉬움이 있어! 고생했어~
문제 6+7
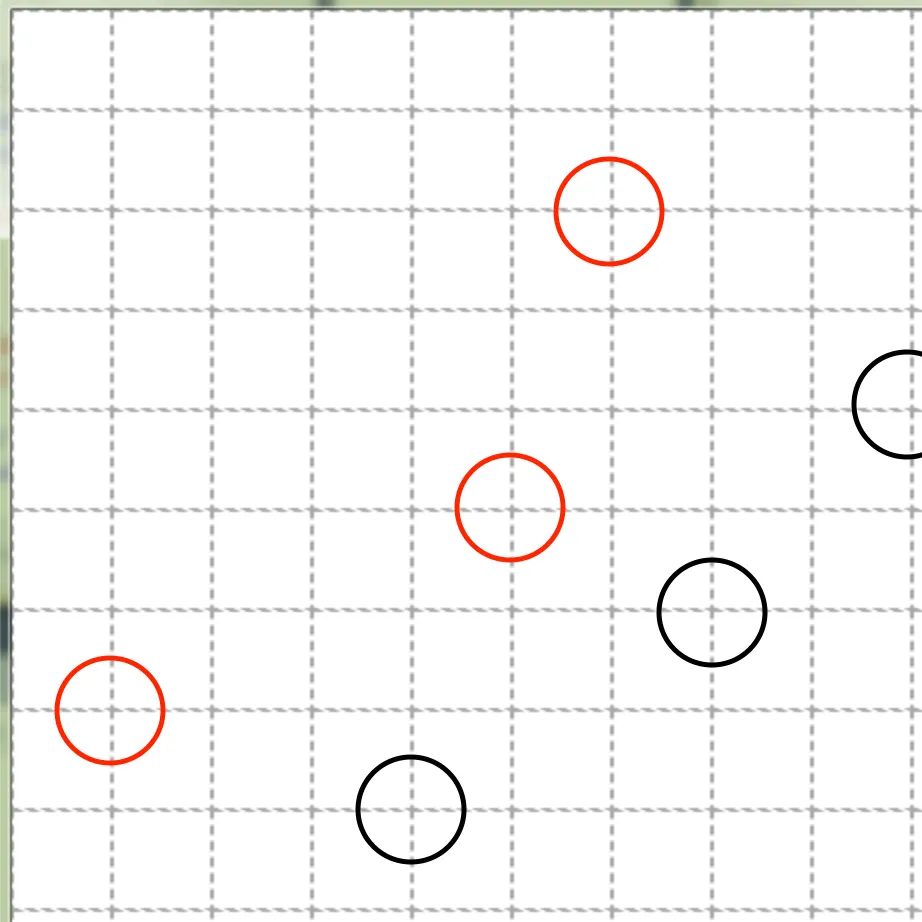
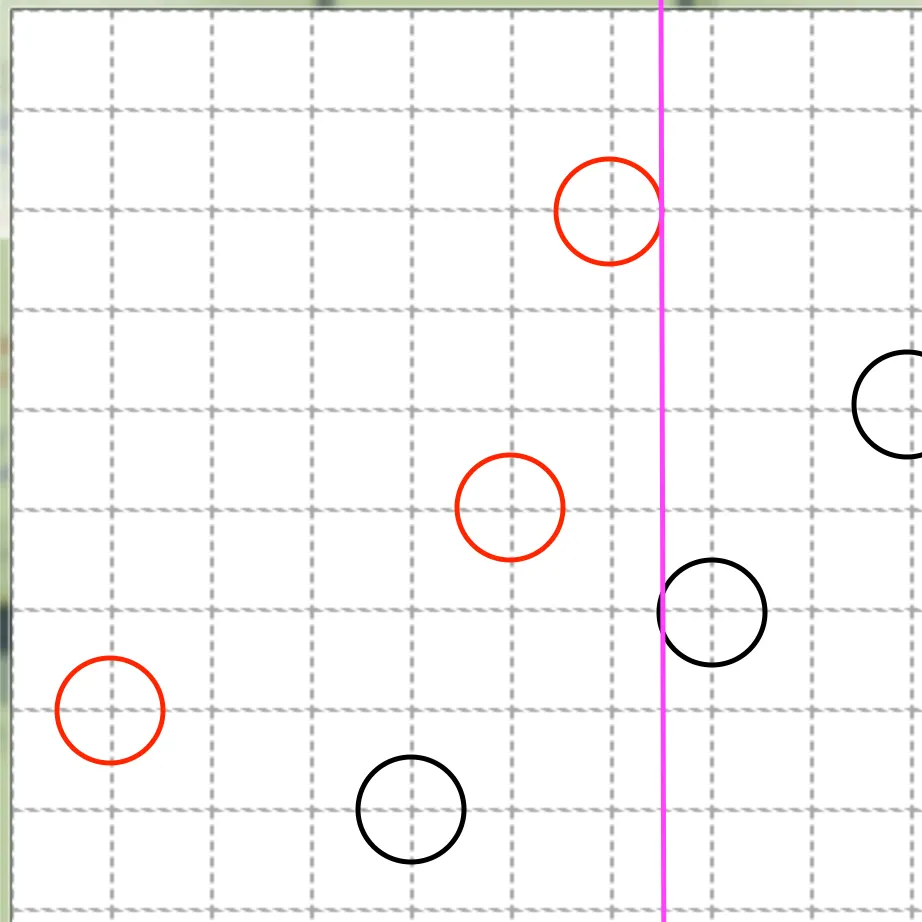
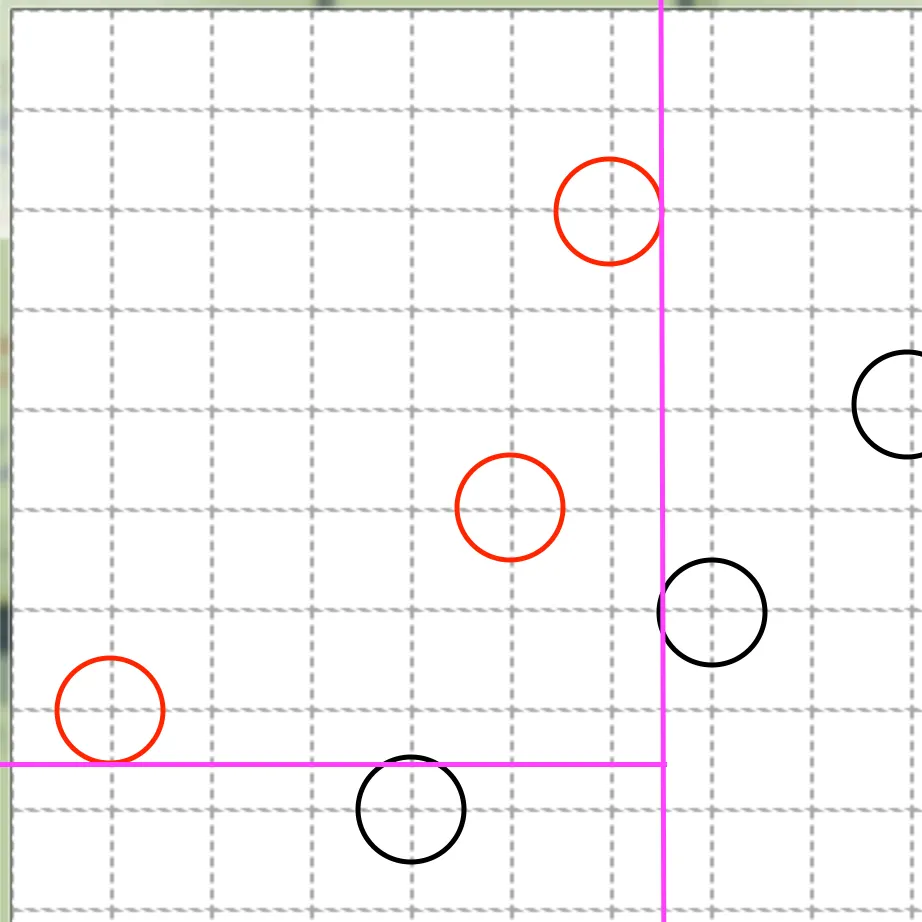
1.
x ≤ 6
a.
if true:
i.
y ≤ 1
1.
if true:
a.
class 0
2.
else:
a.
class 1
b.
else:
i.
class 0
문제 8
문제 9
ㅠㅠ → 이 문제는 꼭 여유되는대로 다시 풀어볼 계획문제 10
ㅠㅠ → 이 문제는 꼭 여유되는대로 다시 풀어볼 계획parse me
1.
None
from
1.
None
supplementary
1.
None
opposite
1.
None
to
1.
None
참고
1.
None