•
OCR = Detection + Recognition 파이프라인에 대한 궁금증 → @11/14/2022 질문 완료
◦
MMOCR 프레임워크는 E2E 학습이 불가능하고, detecion 모델과 recognition 모델을 별도로 학습시켜야 합니다. 그런데 MMOCR 프레임워크를 이용해 recognition 모델을 학습시키기 위해서는 특수한 형태의 레이블이 요구되는 것 같습니다. 텍스트 영역이 crop 된 이미지와 레이블이 1:1 대응을 이루도록 전처리되어야 합니다. 그런데 이 구조가 일반적인지 의문이 들었습니다.
Detector feature 의 recognition 모델 전달: 예를 들어 PMTD 같은 경우에는 soft mask 를 만들기 위해 다양한 피처들을 생성했을텐데 quadrilateral 를 제외한 나머지 정보들은 전부 버려지게 됩니다.
Detector 의 annotation 형태: 데이터셋의 문자 영역 Annotation 방식이 직사각형 형태의 bbox 이 아니라 조금 더 일반적인 형태의 quadrilateral 으로 제공되는 경우가 일반적입니다. 텍스트 영역이 직사각형 bbox 형태라면 상관이 없겠지만, quadrilateral 이라면 원본 이미지를 텍스트 영역에 맞게 오려내면서 여백이 생길 수밖에 없습니다. 이렇게 recognition 모델이 학습되면 위험한 것이 아닌지 궁금합니다. 성능 손실 위험을 감수하면서까지 원본 이미지에서 런타임에 크롭해 쓰지 않고 먼저 크롭해서 캐싱해 두는 것인지 궁금합니다.
•
모델의 capacity 관련 문제 → @11/14/2022 질문 완료
◦
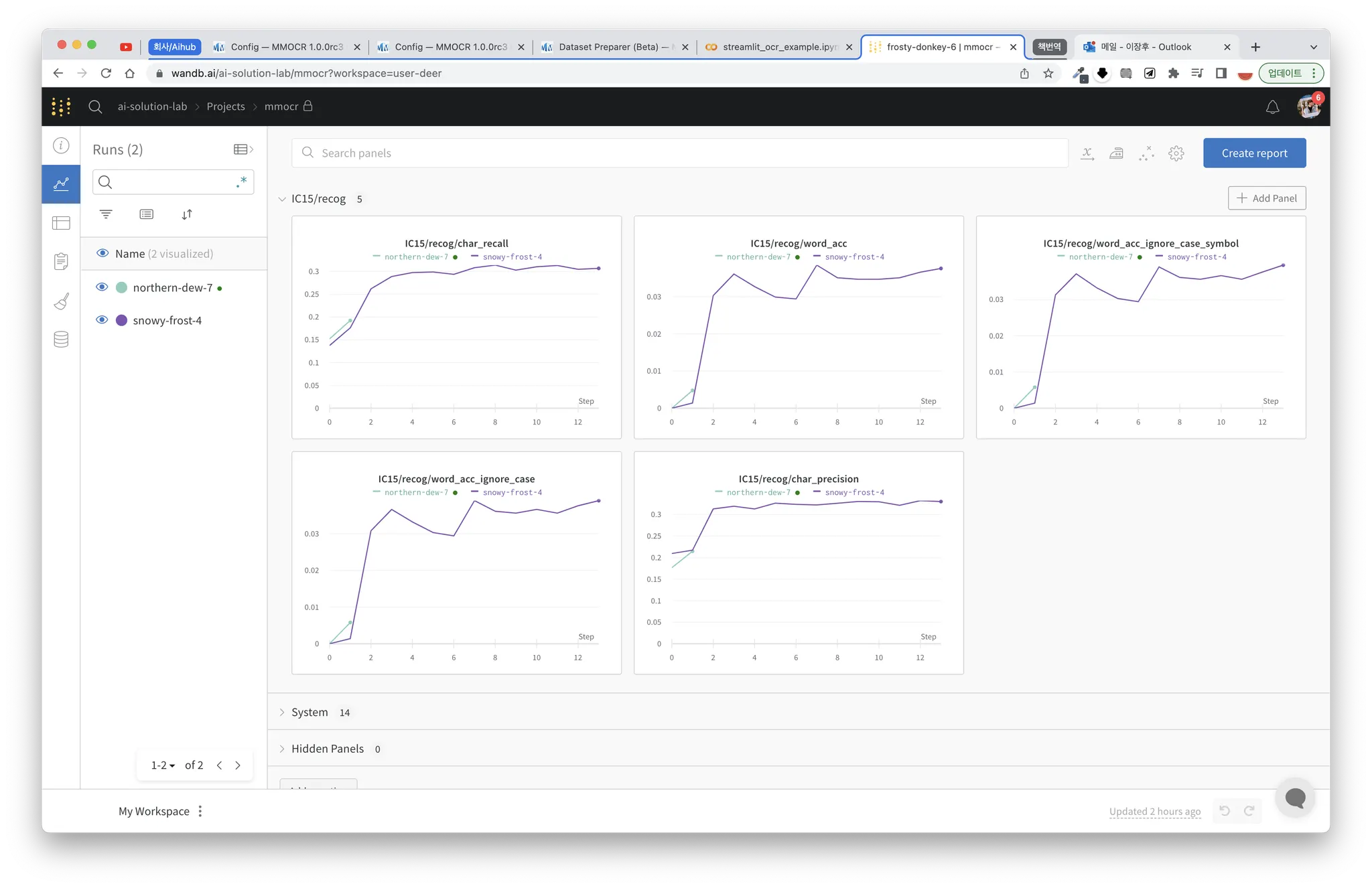
모델이 정상적으로 동작하는지 확인해보기 위해 AIhub 물류 데이터셋이나 Aihub 금융 데이터셋을 학습시키기 전에 ICDAR 2015 데이터셋으로 recognition 모델을 학습시켜보고 있습니다. 하지만 모델이 적절히 수렴이 안되는 중입니다(최근 돌린 결과 char precision recall 0.3 수준).
◦
현재 실험은 다음과 같이 진행되고 있는데, model capacity 가 작다는 문제로 이렇게 score 가 낮은 문제가 발생할 수 있는지 궁금합니다.
◦
ICDAR 데이터인만큼 데이터 품질은 보장된다고 생각해서 모델의 문제라고 생각을 했습니다. MMOCR 프레임워크 내에서 소스코드에 최대한 손을 대지 않고, config 파일만을 이용해 모델의 capacity 를 변경하는 방법이 있는 것인지 궁금합니다. 그리고 적절한 capacity 를 어떻게 탐색할 수 있는지 궁금합니다.
◦
최대한 MMOCR 프레임워크 내에서 해결을 하려고 하는데, 어떻게 하면 적절한 capacity 를 찾을 수 있는지, Config 하나로 capacity 를 바꾸려면 어떤 값을 건드려야 좋을지 모르겠습니다.

질문드린 내용들은 전반적으로 조금 더 시간을 가지고 실험을 해보아도 알 수 있는 내용들이라고 생각하는데, 시간이 너무 부족해서 이렇게 질문을 드립니다. 자세히 답변 주시면 감사하겠습니다!
•
End2end loss 에 대한 문제
◦
MMOCR 프레임워크도 결국 E2E 1 score 을 산출해지지 않는다는 문제가 있다.