
Prefect에는 병렬 작업을 처리하는 다양한 계층의 방법이 있다. 기억할 만한 것은 대충 세 가지다.
1.
Global concurrency
2.
task-level concurrency
3.
work pools level (work queues level, flow level) concurrency
global concurrency
•
비즈니스 코드 (사용자가 직접 작성한 소스코드) 조각의 동시실행을 제한한다.
•
사용이 직관적이고 단순하지만(ref1) 동시접근 제한을 활성화하려면(Active limits) web UI 를 반드시 거쳐야 하는 등 아주 기초적인 락(lock)으로 설계되었다는 인상을 준다.
•
코드나 cli 레벨에서 동시성 제한량을 수정할 수가 없다는 문제가 꽤 귀찮게 느껴진다. 최근에는 python api 를 뚫어 이것을 수정할 수 있도록 이런저런 기능 개발이 되고 있지만, 아직 와 같은 이슈들이 보이는 등 기능이 성숙하지 못하다. 언젠가 고쳐지겠지. 관심 있다면 아예 PR을 넣는 것이 어떨까.
•
with 구문을 기반으로 특정 코드로 접근을 막는 방식을 채택하기 때문에, 따라서 비즈니스 로직 핵심부에 prefect 에 강한 의존성이 생긴다는 치명적인 문제가 있다.
사용하는 방법
1.
web ui 또는 에서 제안된 python api 를 사용해 concurrency limit 을 만든다.
2.
코드에 concurrency 블록을 심는다.
@prefect.flow
def heavy_computation():
with concurrency(
"heavy-computation", occupy=1
): # Special characters, such as /, %, &, >, <, are not allowed.
print("Now running heavy computational process ... ")
time.sleep(5)
Python
복사
3.
web ui 를 이용해 concurrency limit 을 활성화한다.
사용 주의사항
•
python API: with 구문에서 기존에 만들어진 concurrency limit 이 없다면 inactive state 로 생성한다. @1/23/2024 기준 이것을 활성화할 방법은 web ui 밖에 없다.
•
Slot decay: 다시 사용가능하게 되기까지의 지연시간을 제어한다. 사용하기 전에는 이 값이 동작하는 로직을 확인하자. 확인하지 않으면 예상하지도 못한 이상한 동작을 발견하게 될지도 모른다.
task-level (task run) concurrency
•
작업(task)의 동시실행을 제한한다.
•
사용이 단순하다.
•
하지만 이 작업이 어떤 작업에 의해 중단되어 있는지 확인이 불가능하고 플로우(flow)보다 유연성이 적은 작업(task)에 태그를 일일히 붙여 주어야 한다는 문제가 있다.
사용하는 방법
1.
다양한 api 를 통해 concurrency limit 을 생성한다.
•
API
◦
cli: prefect concurrency-limit
◦
python api
◦
prefect web UI: concurrency → task run
2.
task 데코레이터에 태그를 추가한다(ref2).
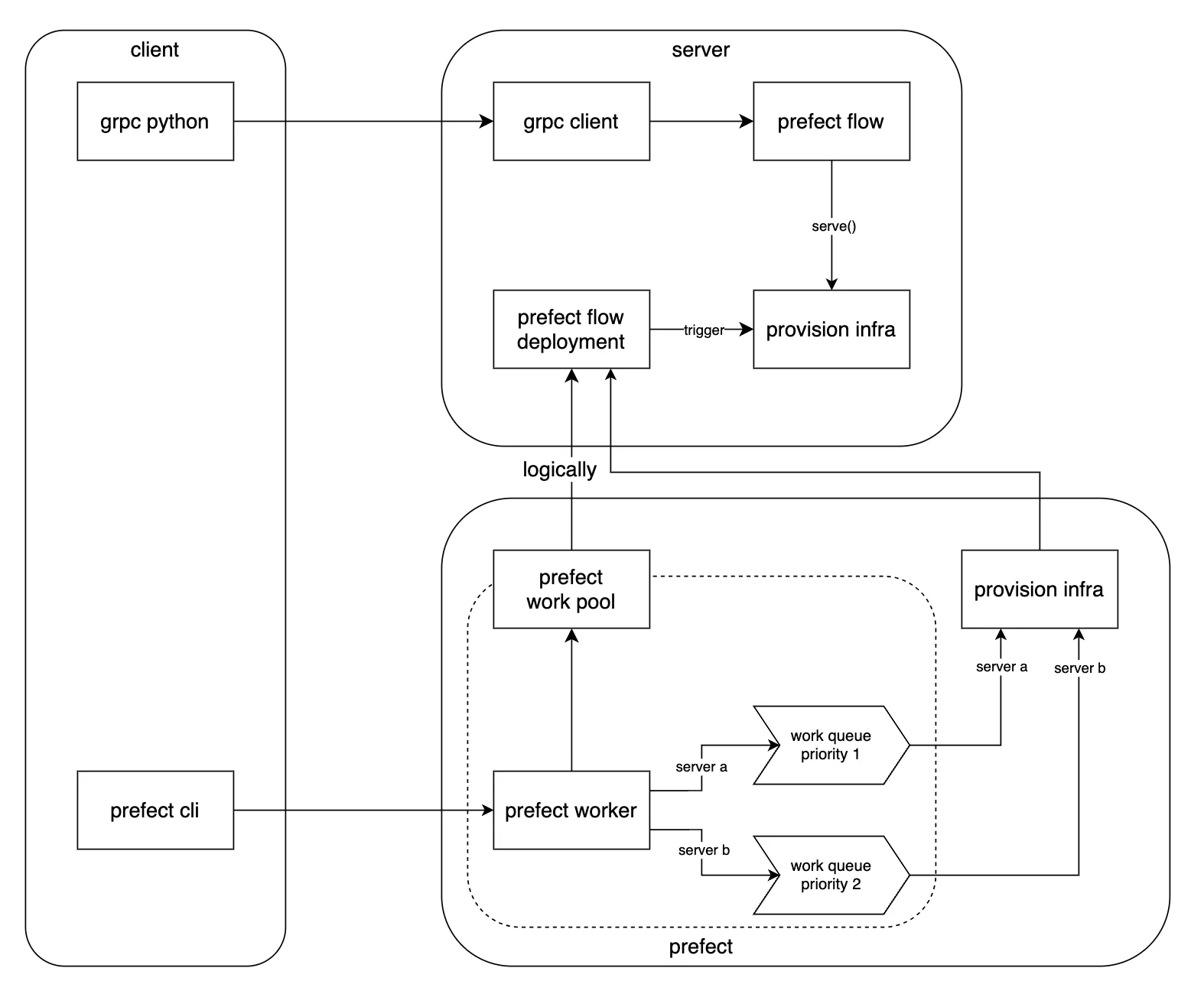
work pools level (work queues level, flow level) concurrency
•
추상적으로 바라보면 플로우의 동시실행이나 실행 순서를 일정한 정책에 따라 제한하는 기능이다.
•
해결되어야 하는 거대한 작업들이 쭉 나열되어 있고, 나열된 이러한 작업들에 FIFO를 적용하고, 나열된 작업들을 묶어 우선순위를 지정할 수 있다는 점에서 작업 풀 단위의 동시성 제어가 가장 이상적이고 범용적이다(ref3,ref5).
•
단점은, 작업 풀을 만들고 작업을 등록하는 일(ref4)이 디버깅이 어렵고 꽤나 복잡하다.
◦
조금 미시적인 이야기: 작업 풀을 만드는 방법은 다양하다. 작업을 도커로도 실행할 수 있고, 서버리스 환경에서 실행할수도 있고, 로컬 환경의 서브프로세스로도 실행할 수도 있다. 개중에서도 local subprocess 타입 작업 풀을 제공하는 이유는 prefect는 작업 풀을 처음 만들어볼 때 복잡성을 줄이고 디버깅을 편하게 하기 위함이다.
▪
근데 이게 잘 동작하지 않는다. 그래서 여기저기 수소문을 하며 찾아다녀 보니 이건 뭐… 그 기능을 자기는 잘 안써서… 그런 케이스가 있을 수 있다는 것을 잊고 깜빡했다고 미안하다고 한다. 얼탱이… 이 이슈( 11597)를 참고하자.
11597)를 참고하자.
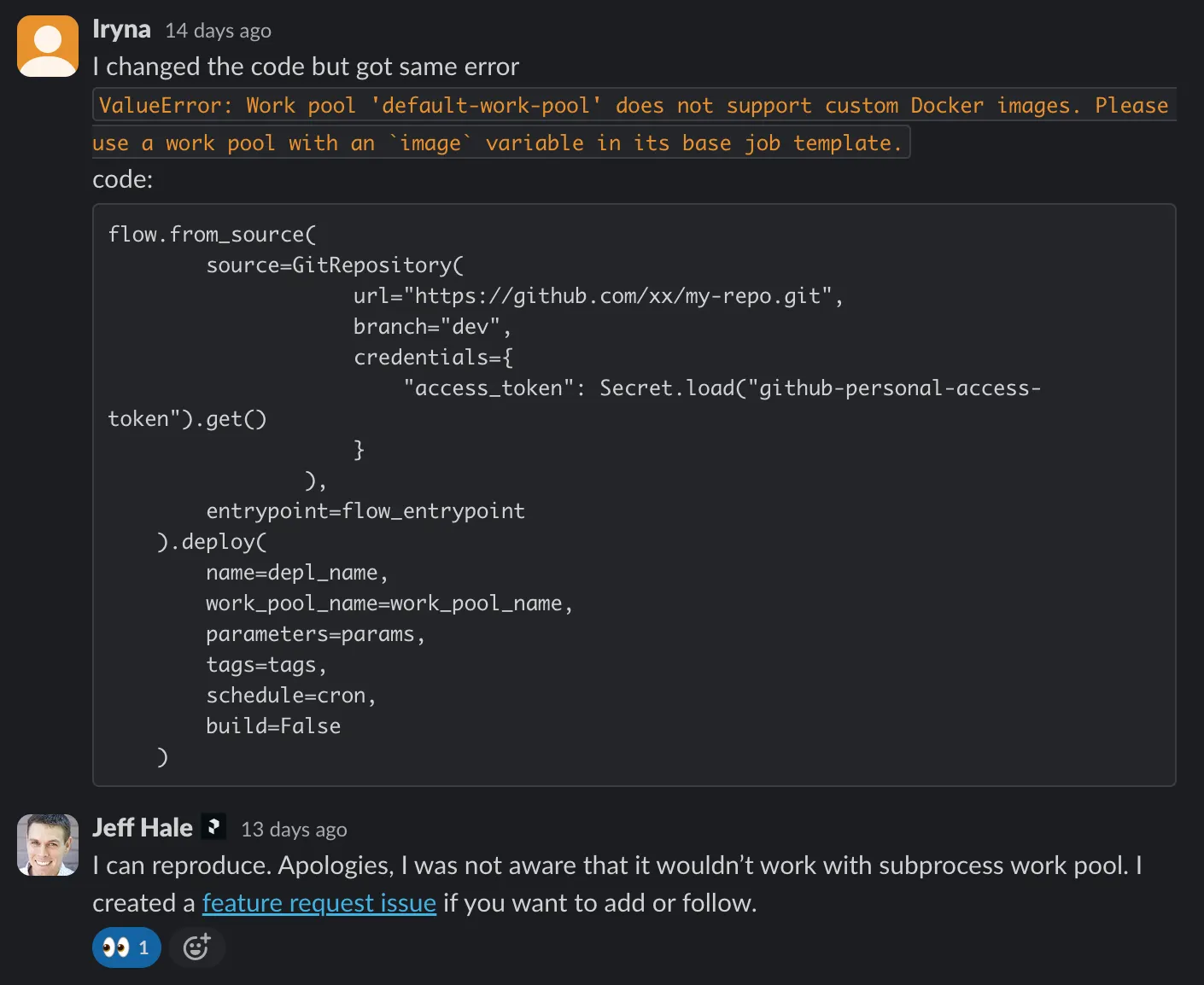
▪
그래서 그 전까지는 그냥 도커의 복잡성을 추가하지 않고 .serve() 만 사용하거나(공식 문서에서도 Process 타입은 ‘runs flow in a subprocess’ 기능을 하지만, ‘In most cases, you're better off using .serve.’ 이라고 되도록 쓰지 말라고 되어 있다), 도커타입 작업 풀을 사용하는 방법밖에 없다. Docker pool 을 사용하는 경우 이 글을 반드시 참고하자. 도커 이미지 - serve - deploy 의 연관성이 잘 나타나 있다.
•
물론 복잡하긴 하더라도 한번 사용법을 익혀 두면 매우 큰 유연성과 수평적 확장가능성을 얻게 된다. 제공하는 기능을 이용해 도커, 쿠버네티스, 서버리스 시스템으로 쉽게 이전이 가능하다. 한번 구성하는 것이 조금 까다로워서 그렇지 만들고 보니 그렇게 어렵지만은 않다.
도커 작업 풀 사용 방법
1.
작업 풀을 생성한다. (CLI(밑줄은 추천하는 방법), python api)
2.
작업 풀에 우선순위가 부여된 큐를 붙인다. (CLI, 웹 콘솔, python api)
3.
작업 풀에서 일하는 노동자(worker)을 만들어 실행한다. (CLI, 웹 콘솔, python api)
4.
플로우를 .serve 하는 엔트리포인트를 만든다. 이 엔트리포인트는 컨테이너에서 실행된다.
5.
도커파일을 만든다. 도커파일은 플로우의 .serve 실행 환경을 구축해야 한다. prefect 은 물론 런타임에 필요한 모든 의존성들이 이미지에 설치되어 있어야 한다.
6.
플로우를 .deploy 하여 작업 풀의 우선순위 큐에 연결한다. 커스텀 도커파일을 사용하려면 DeploymentImage 클래스를 이용한다. 이 클래스에서 도커 이미지를 빌드할 때 필요한 것들을 python API로 전달하고, .deploy 에는 도커 이미지를 실행할 때(docker run) 필요한 것들을 python API로 정의한다. 이것이 실행되면 컨테이너 이미지가 빌드된다(ref6).
7.
deploy 된 플로우를 prefect deploy run 명령어로 실행한다. 그러면 prefect 서버가 정의해 두었던 컨테이너 실행 명령을 쭉 실행하면서 플로우를 실행하기 시작한다.
사용 주의사항
•
submit() 과 to_deployment() 에도 work_pool 과 work_queue 옵션이 있다. run_deployment 에도 work_queue_name 을 지정할 수 있다. 하지만 serve 로 배포되는 경우, 이들 옵션들이 동시성에는 관여하지 않는다. 그냥 web ui 에 보이는 모습만 달라진다.
•
deploy 를 사용하는 경우 가장 먼저 시도하게 되는 것은 local subprocess 타입 일거리 풀 또는 도커 타입 일거리 풀을 먼저 사용해보게 될 것이다. 이때 nvidia gpu 등을 컨테이너에서 사용하기 위해 docker run 에 추가적인 옵션을 주고 싶을 수 있다. deploy 메서드에 job_variables 이라는 옵션이 있지만, 이것은 docker run 명령어에 붙는 추가 인자가 아니라 어느 타입의 일거리 풀이든 일관된 형태로 다루기 위한 일거리 템플릿(job template)을 수정하는 인자다. 따라서 이를 수정하기 위해서는 일거리 템플릿을 알아야 한다.
prefect work-pool get-default-base-job-template --type docker 을 통해 확인할 수 있는 도커타입 일거리 템플릿. 여기에 device_request 같은 것이 없다는 점이 가장 큰 문제다. 그래서 2.16까지도 지원이 안 되는 중이다.
◦
이 문제를 해결하기 위해 이런 방법들을 선택할 수 있다.
1.
request 프록시 서버를 둔다. (깔끔하지 못하다)
2.
docker run 을 항상 nvidia 런타임으로 실행하도록 /etc/docker/daemon.json 파일을 수정한다.
•
work queue 는 worker 가 어떤 일거리 요청을 먼저 ‘접수(submit)’ 하는지를 결정할 뿐, 높은 우선순위의 큐에 있는 작업이 실행 중일 때 낮은 우선순위에 있는 작업이 실행되어서는 안 된다고 강제하는 것이 아니다. (단, 먼저 ‘실행’ 상태로 만드는 것도 이 녀석의 역할인지는 확인해 보아야 한다) 일반적으로 이런 상황이 필요해서 priority queue 를 찾게 되었을텐데(ref), 동작 방식은 약간 다르다. 그 이유는 prefect 이 하나의 머신을 잘 사용하는 일을 최적화하는 목적으로 개발된 것은 아니기 때문이다. 기본적으로 수평적 확장이라는 철학 위에 올려졌다(ref).
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료을 보관해 두는 영역입니다.
1.
None
from : 과거의 어떤 원자적 생각이 이 생각을 만들었는지 연결하고 설명합니다.
1.
•
앞의 글은 prefect가 전체적인 맥락에서 무엇을 하는 도구인지 설명되어 있다.
2.
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는지 연결합니다.
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는지 연결합니다.
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되거나 이어지는지를 작성하는 영역입니다.
1.
None
ref : 생각에 참고한 자료입니다.