
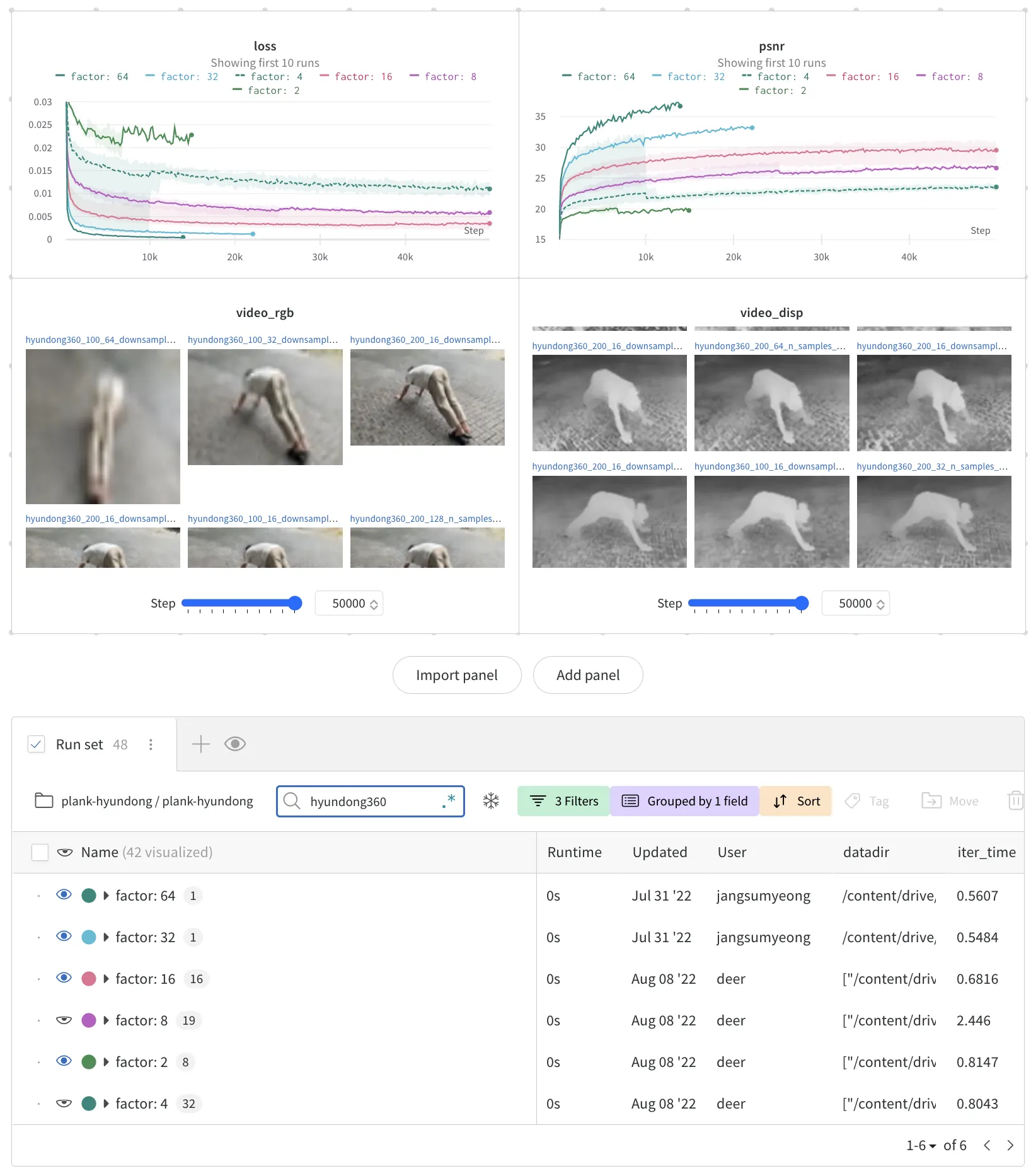
wandb 의 굉장히 유용한 기능들 중 하나는 실험 그룹(group)이다. 그룹은 아래 그림과 같이 연관성 있는 실험들을 일정한 기준으로 묶어 최대값, 최소값, 중간값, 평균값 등을 한번에 시각화할 수 있는 기능이라고 생각하면 된다.
그런데 이 필터로 사용할 수 있는 내용이 굉장히 제한적이기 때문에 다음 원칙을 지켜야 한다.
1.
데이터셋의 디렉터리 경로를 run.config 에 등록할 때에는 전체 경로뿐 아니라 최종 경로만을 함께 저장해두면 좋다. 그 이유를 이해하기 위해 다음 경우를 생각해 보자. 데이터셋 A 와 데이터셋 B 가 있다고 하자. 사람 a, z 가 데이터셋 A 로 실험을 진행했고 사람 b 가 데이터셋 B 로 실험을 진행했다. 사람 b 는 (a, z) 의 실험과 동일한 파라미터가 데이터셋 B 에도 잘 적용될 수 있는지 실험해보려고 한다. 그런데 사람 c 가 데이터셋 A 이 수정될 필요가 있음을 알고 데이터셋 A:v2 를 만들었다. 그리고 c 는 A:v2 로 (a, z) 의 학습 결과물과 비교하고 싶다. 사람 a, b, c 가 각각의 로컬 컴퓨터에서 데이터셋을 저장한 환경은 모두 다르다. 이러면 어떻게 될까?
실험하는 사람 | 데이터셋 | 데이터셋이 저장된 디렉터리 경로 | 사용하는 데이터셋 아티팩트 |
a | A | … a_local/A | A |
z | A | … a_local/A | A |
b | B | … b_local/B | B |
c:v2 | A:v2 | … c_local/A | A:v2 |
가장 훌륭한 문제 해결 방법은, 사용하는 데이터셋 아티팩트 이름과 버전을 기준으로 그룹을 만들어주는 것이다. 하지만 아직 wandb 에는 해당 기능을 지원하고 있지 않다(@8/8/2022, 3:12:00 PM). 그러므로, 아직 (a, z) 의 실험과 c 의 실험을 분리하여 그룹할 수는 없다. 따라서 가장 나은 방법은 데이터셋이 저장된 디렉터리 경로의 마지막 부분(basename)을 분리하여 run.config 에 등록해 주는 것이다.
2.
run 이름은 일정 포맷을 따라야 한다. run 이름을 필터링할 때 sql regex 을 사용할 수 있다. 하지만 run 이름을 기준으로 그룹화할수는 없다. 이 점을 분명히 인지하자. 또한 run 이름에 이런저런 것들을 넣지 말자. 차라리 해당 내용들을 run 의 config 으로 넣어라.
3.
태그를 사용하지 말라. 태그를 이용해서 그룹을 지을 수 없기 때문이다. 태그를 맹신하다가는 나중에 실험을 적절히 묶어서 시각화하지 못할 수 있다. 이것은 리포트 생성 자동화 측면(from1)에서 굉장히 좋은 방법이 아니다.
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료들.
1.
None
from : 과거의 어떤 생각이 이 생각을 만들었는가?
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는가?
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는가?
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되고 이어지는가?
1.
None
참고 : 레퍼런스
1.
None