
데이터셋 일부를 랜덤 추출해서 픽셀 수를 비교했을 때 굉장히 클래스 균형이 맞지 않는다는 것이 문제가 된다. 모든 영상들을 모아놓고 클래스별로 픽셀수를 하나하나 세어 보았을 때, 전체적으로 굉장히 적은 양만 존재하는 클래스들이 존재했다. 이들은 맥락정보가 굉장히 적을 가능성이 높으며(참고3), 과적합될 가능성이 있다. 따라서 너무 국소적인 부분을 다루고 있는 클래스에 대해서는 others 로 분리했다.
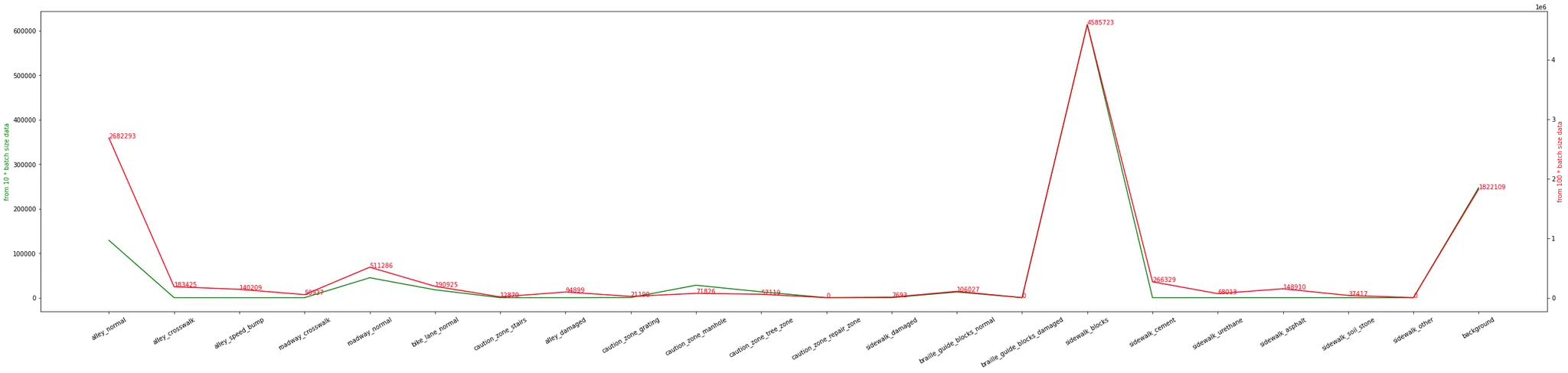
위 그래프에서 초록 선은 전체 데이터셋 중 샘플 10개, 빨강 선은 샘플 100개를 랜덤 추출해서 각 픽셀 갯수를 측정한 것이다.
뭐, 클래스 임밸런스가 존재하지 않기를 바라는 것은 말이 안 된다. 진짜 문제는 영상의 정보만으로 추측하기 어렵다는 점이다. 어떤 사람의 눈과 귀를 막고, 바닥만 보도록 만든 뒤 검정색 우레탄 재질의 자전거도로 위에 던져놓은 뒤 눈만 뜨게 했다고 해 보자. 자신이 서 있는 공간이 인도인지 자전거도로인지 자동차도로인지는 알 방법이 없다. 우레탄 재질의 인도도 있고, 우레탄 재질의 자전거도로도 있고, 우레탄 재질의 자동차도로도 있다.
데이터 제작사측에 문의해본 결과, 크라우드소싱으로 데이터 제작이 이루어졌으며, 이와 관련한 그 어떤 메타데이터도 활용할 수 없다는 사실을 알게 되었다. 영상 이외의 맥락은 활용할 수 없다는 말이 된다 (참고2,3:나는 이것을 'semantic information loss' 라고 부르기로 했다).
@11/19/2021
모델 입장에서도 도로같이 생긴 인도인지, 인도같이 생긴 자전거도로인지, 자전거도로같이 생긴 도로인지 구분해내지 못해 답답할 것이다. 이런 형태의 데이터 분포는 Andrej Ng 교수님이 강조하는 'consistent dataset' 이라고 할 수 없다 (참고1). 사람이 봐도 헷갈릴 만한 부분에 대해서 동일한 클래스로 묶어 학습시켜야 한다. 위와 같은 문제들로 최종적인 클래스는 다음과 같이 분류했다.
1.
"background"
2.
"sidewalk_block"
3.
"sidewalk_other"
4.
"crosswalk"
5.
"carroad"
6.
"tree"
7.
"manhole"
8.
"guideblock"
9.
"dangerous"
'보도블럭' 과 '점자블럭', '횡단보도' 정도의 마스킹은 단일 프레임 이상의 정보가 존재하지 않아도 되기 때문에 살려 둘 수 있어서 다행이다.
카메라의 FOV(Field Of View) 가 넓을수록 - 영상 전체에 담기는 시맨틱 정보량이 더 많다. 동일한 FOV 일 때, 동일한 픽셀이 담을 수 있는 실제 공간이 더 넓어지기 때문에, 더욱 먼 거리를 바라보고 있는 영상일수록 시맨틱 정보량이 더 많을 가능성이 높다.
참고