
관련 소스는 COLAB Notebook 을 참고하자 (참고3).
새로운 클래스를 만들고 다음 함수를 재정의했다 (참고1).
def train_step(self, data):
im, ma = data
im, ma = self.augmentation_model((im, ma))
with tf.GradientTape() as tape:
ma_pred = self(im, training=True) # Forward pass
# Compute the loss value
# (the loss function is configured in `compile()`)
loss = self.compiled_loss(ma, ma_pred, regularization_losses=self.losses)
# Compute gradients
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update metrics (includes the metric that tracks the loss)
self.compiled_metrics.update_state(ma, ma_pred)
# Return a dict mapping metric names to current value
return {m.name: m.result() for m in self.metrics}
Python
복사
self.augmentation_model 이 담고 있는 객체는 keras.sequence 모델을 Model 클래스로 한번 감싸준 모델 객체이다.
...
seq = tf.keras.Sequential(
[
tf.keras.layers.RandomFlip("horizontal"),
tf.keras.layers.RandomRotation(0.02),
]
)
image_input_shape = list(image_input_hw) + [_default_channel_n]
mask_input_shape = list(image_input_hw) + [class_n]
x_im = tf.keras.Input(shape=image_input_shape)
x_ma = tf.keras.Input(shape=mask_input_shape)
return tf.keras.Model(
inputs=[x_im, x_ma],
outputs=[seq(x_im), seq(x_ma)],
name='sequential_augmentation_model'
)
Python
복사
gpu 에서는 잘 동작했다.
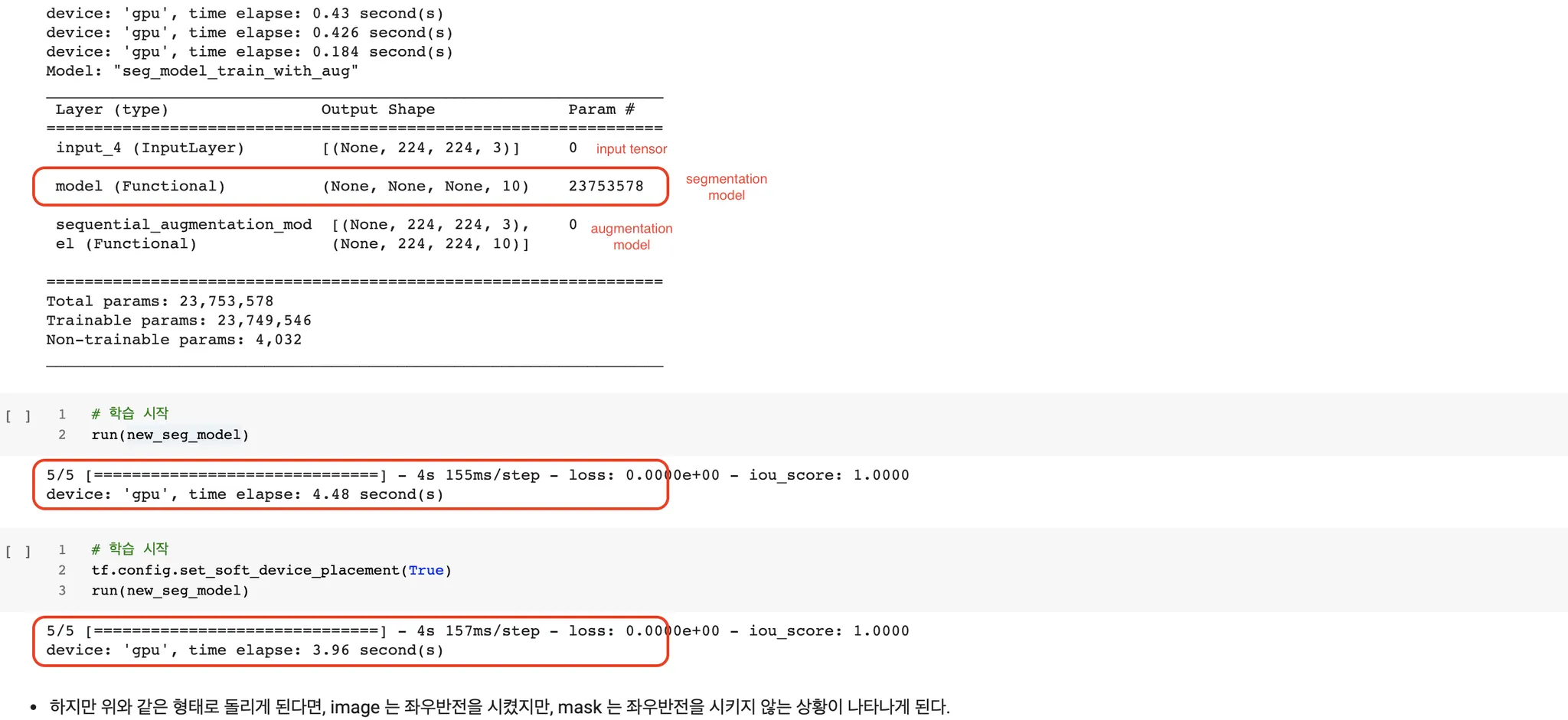
하지만 TPU 에서는 다음과 같은 오류와 함께 동작하지 않았다.
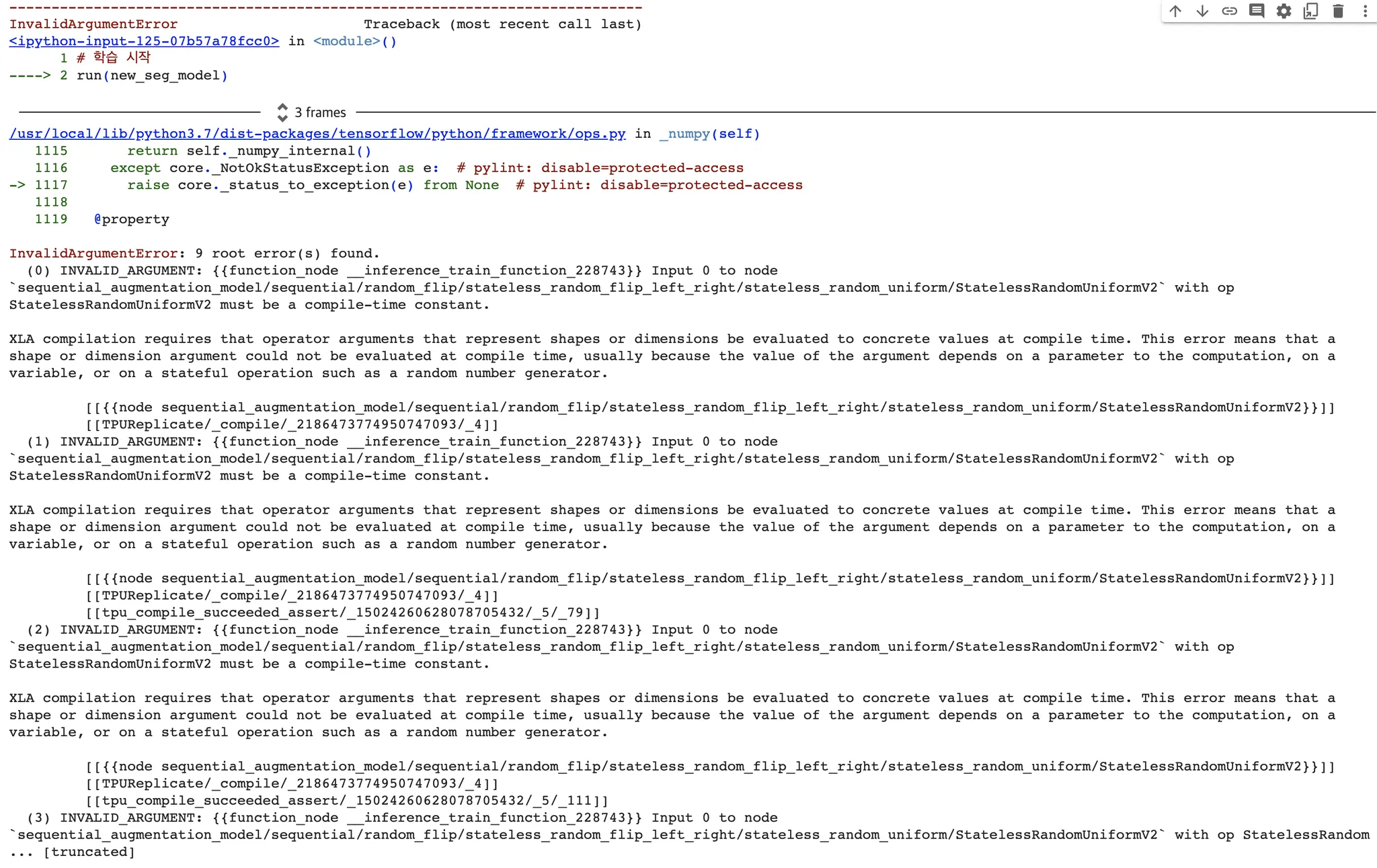
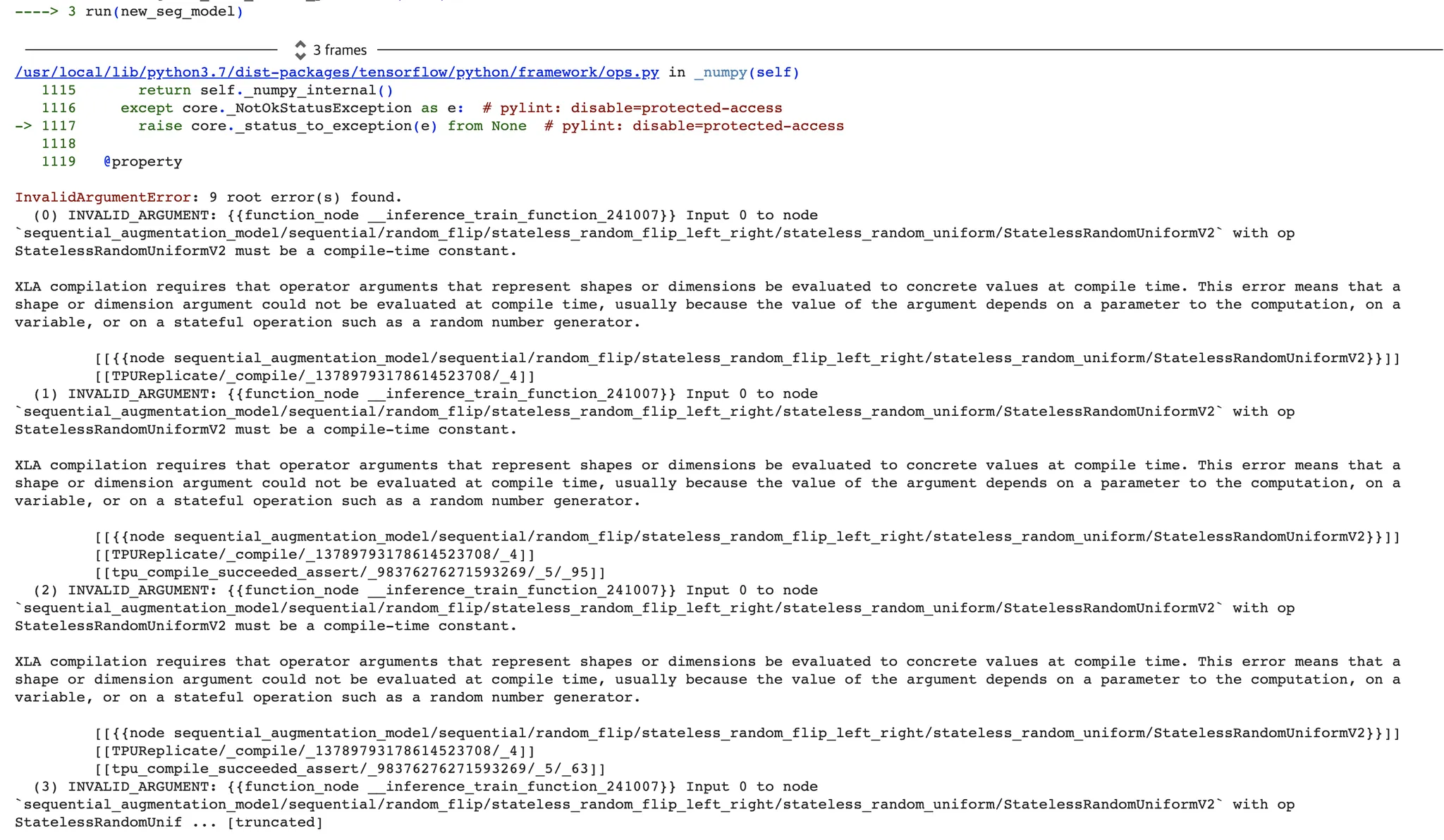
짐작하건데 무작위(Random) 기반의 augmentation 이기 때문에, 이렇게 train_step() 과 같은 구성에서 TPU 에서 올바르게 작동시킬 수 없다. 즉석 환경 에서 call 하는 것이 불가능한 것이라고 생각한다. 내용을 대충 보면, 랜덤 숫자를 생성하는 과정에서 문제가 생겼고, 이를 해결하기 위해서는 "compile-time constant" 가 되어야 한다고 하는데, 관련 이슈를 겪고 있는 사람을 많이 찾을 수 없었다.
이 가설에 대해서 팩트를 확인하기 위해 augmentation layer 에 random 한 요소가 들어가는 것들만 쏙 빼고, channel 만 맞춰준 뒤 다시 시도해 보았다.
...
# 내가 추가하고 싶은 runtime augmentation pipeline
im_seq = tf.keras.Sequential(
[
tf.keras.layers.Conv2D(_default_channel_n, (3,3), padding='same'),
tf.keras.layers.Conv2D(_default_channel_n, (3,3), padding='same'),
],
name='sequential_image_augmentation_layers_debug'
)
ma_seq = tf.keras.Sequential(
[
tf.keras.layers.Conv2D(class_n, (3,3), padding='same'),
tf.keras.layers.Conv2D(class_n, (3,3), padding='same'),
],
name='sequential_mask_augmentation_layers_debug'
)
image_input_shape = list(image_input_hw) + [_default_channel_n]
mask_input_shape = list(image_input_hw) + [class_n]
x_im = tf.keras.Input(shape=image_input_shape)
x_ma = tf.keras.Input(shape=mask_input_shape)
return tf.keras.Model(
inputs=[x_im, x_ma],
outputs=[im_seq(x_im), ma_seq(x_ma)],
name='sequential_augmentation_model_debug'
)
Python
복사
Conv2D 는 trainable 한 variable 이 들어있는 커널이지만 이에 대해서 loss 를 설정해 주지 않아 그래디언트가 흐르지 않을 수 있다는 사실을 경고할 뿐, 별다른 오류 없이 잘 동작한다.

이슈와 관련해 비슷한 표현들은 찾을 수 있어서, TPU 를 사용할 때 지켜야 하는 것이 아닐까 싶긴 했지만(참고2) 레퍼런스를 많이 찾을 수 없어서 공식 레포에 이슈를 남기게 되었다. 결론은, 이것은 TPU 와 관련된 버그의 일종이었다.
참고