
•
역사적 배경
◦
•
에이전트가 수행하는 일의 단계에 따라
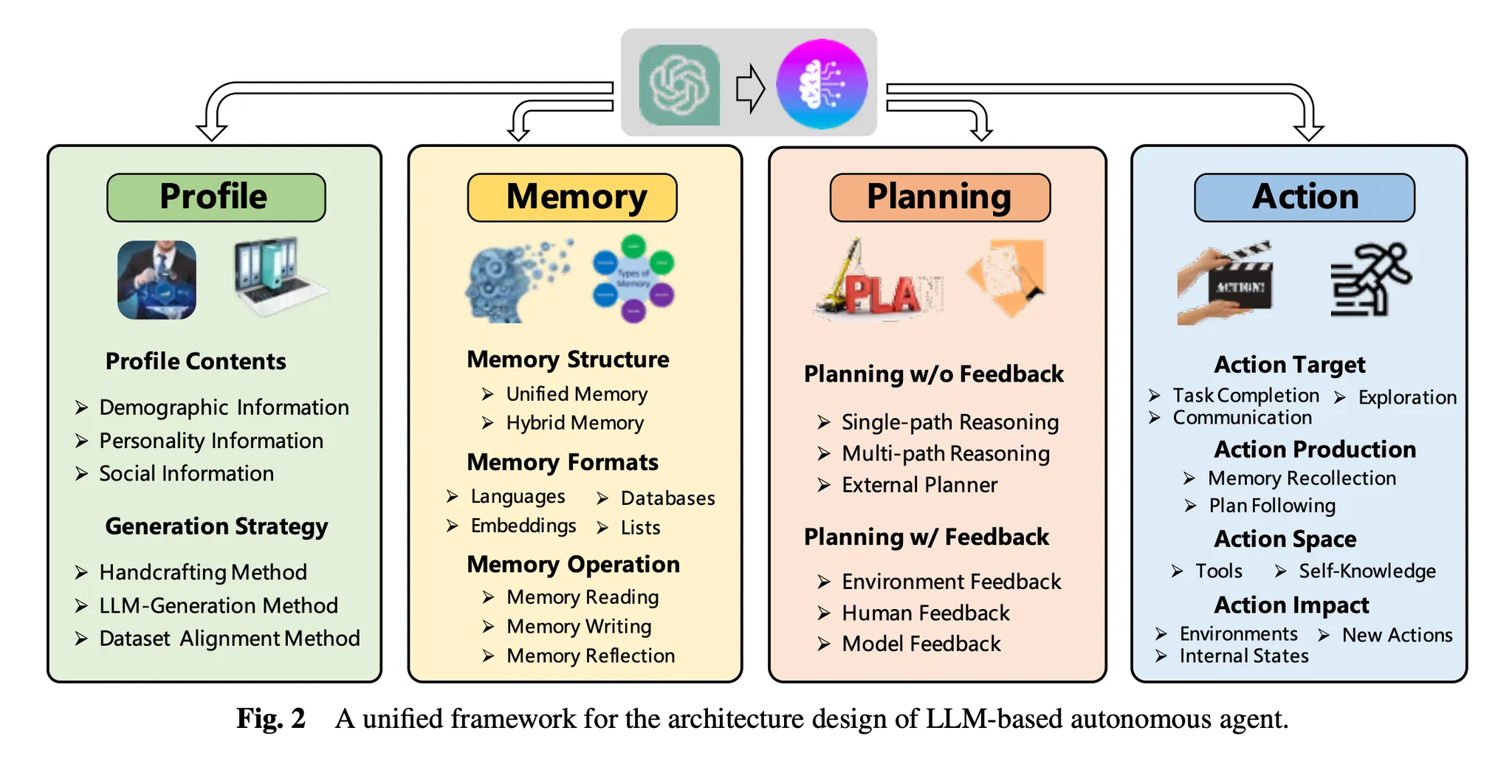
◦
역할(Profile)
▪
역할을 부여받는 방법(Profile Generation)에 따라
•
너는 프로그래머야, 너는 최고의 마케터야 할당(Handcrafting Method)
•
역할을 생성하는 작업조차도 LLM을 통해(LLM-Generation Method)
•
실제 사람의 페르소나 데이터를 입력(Dataset Alignment Method)
•
이것들을 적절히 결합한 방법(Hybrid Method)
◦
기억(Memory)
▪
기억을 구조화하는 방법
•
In-context-learning 과 같은 단기기억을 적극적으로 사용(Unified Memory). 장점은 쉽고 직관적이라는 것, 단점은 너무나 당연히 단기기억 한계(context-window)라는 제약이 있다는 것.
•
단점이 너무 치명적이기 때문에 단기기억과 장기기억을 같이 사용(Hybrid Memory).
▪
장기기억이 저장되는 형식
•
자연어(Natural Languages).
•
벡터 등으로 압축된 형태(Embeddings). e.g. MemoryBank, ChatDev
•
심지어는 프로그래밍 소스코드로 만들어 버리기도 함. e.g. Voyager
•
이것들을 적절히 연결한 방법
◦
예를 들어 키-값 형태인데 키는 임베딩, 값은 자연어 e.g. GITM
▪
장기기억으로부터 값을 가져오는 논리
•
: 최신 정보를 가져온다. e.g. LSH, ANNOY, HNSW, FAISS
•
: 관련도 높은 정보를 가져온다.
•
: 중요도 높은 정보를 가져온다. 아직 쿼리는 잘 반영하지 않는 편이다.
•
이것들을 적절히 가중치로 더한 방법
◦
▪
장기기억에 값을 쓰는 방식
•
주요 문제에 따라
◦
비슷한 정보를 어떻게 관리할래? (Memory Duplicated)
▪
일정 기준에 의해 괜찮은 기억으로 기존 기억을 지워버리고 덮어써버리는 방법
◦
얼마나 많은 정보를 관리할래? (Memory Overflow)
▪
사용자에게 책임 전가 e.g. ChatDB
▪
고정 크기 버퍼 두고 FIFO e.g. RET-LLM
◦
어떻게 더 추상적이고 고차원적인 기억을 만들래? (Memory Reflection)
▪
버퍼가 찰때마다 버퍼 속 내용을 취합해서 추상화된 형태로 정리 e.g. GITM
◦
계획(Planning)
▪
피드백 유무에 따라
•
피드백 없이 계획 세우기(Planning without Feedback)
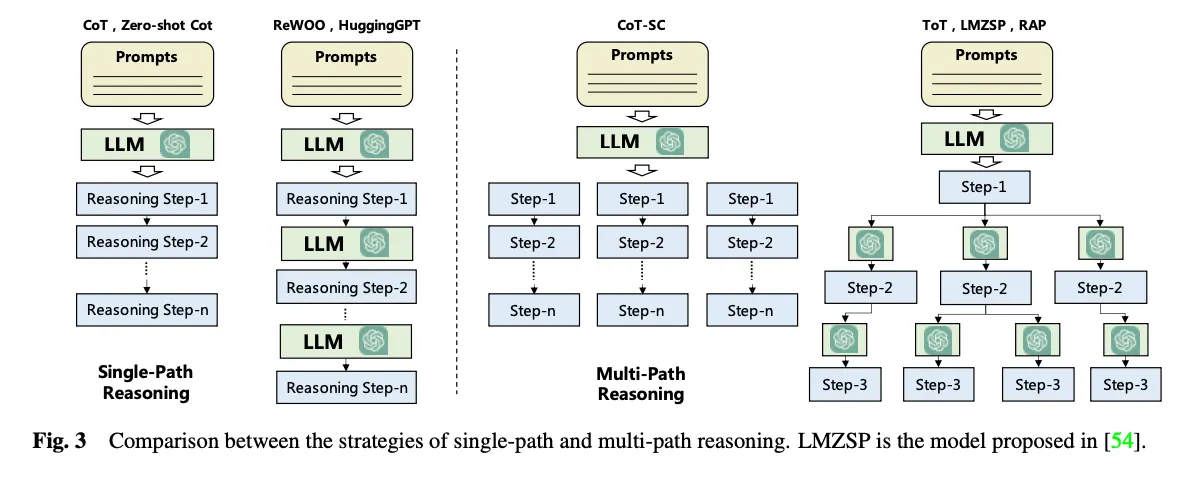
◦
하나의 목표가 여러 개의 단계적 목표로 나누어지는 워터폴 방식(Cascading manner)의 계획 세우기(Single-path Reasoning): e.g. CoT(Chain of Thought) - 예시를 제공함, Zero Shot CoT - 예시를 제공하지 않고 ‘차례차례 생각해봐’ 정도만을 추가함, Re-Prompting - 요구조건과 안맞을 시 그냥 다시 실행
◦
여러 단계적 목표로 나누어질 수 있을 뿐 아니라 하나의 목표를 달성하기 위해 갈 수 있는 길이 다양하다고 바라봄(Multi-path Reasoning): e.g. CoT-SC(Self-consistent CoT) - 단계적 목표를 통해 목표로 가는 길에 대한 계획을 N가지 방식으로 한방에 세움. ToT(Tree of Thought) - 각 단계적 목표마다 여러번 LLM을 호출해서 트리처럼 만들고 각각의 계획을 평가해서 BFS.
◦
외부 플래너(External Planner): LLM+P - PDDL 사용, CO-LLM - LLM이 어려워하는 저수준 계획은 룰베이스 알고리즘이나 휴리스틱하게 해소.
•
실제 세상은 그렇게 호락호락하지 않으므로 피드백과 함께 계획 수정하기(Planning with Feedback)
◦
가상 또는 상호작용하는 환경으로부터 받는 피드백(Environmental Feedback): e.g. ReAct - 검색엔진 검색같은 행동의 결과물로부터 받음, Voyager - 프로그램 실행 오류로부터 받음, Inner Monologue - 작업 성패 여부와 액션에 따라 변화한 환경에 대한 설명을 받음
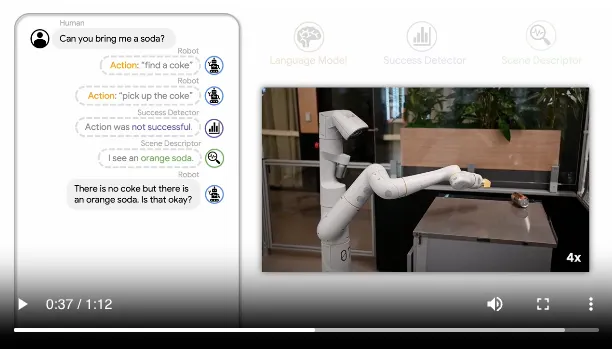
Inner Monologue: 마치 나의 내면에서 대화가 일어나는 듯하다.
◦
사람으로부터 받는 피드백(Human Feedback): e.g. Inner Monologue - 사람이 중간에 개입 가능
◦
다른 LLM 모델이나 파인튜닝된 LLM 모델로부터 받는 피드백(Model Feedback): e.g. SelfCheck, ChatCoT, InterAct - 다른 LLM들로부터 피드백, Reflexion - 자신이 행동했던 기록들까지 모아서 자기회고.
◦
행동(Action)
▪
행동하기 전(before-action)
•
행동을 통해 무엇을 하고자 하는가? (Action goal)
◦
작업 완수(Task Completion) e.g. 프로그래밍, 소프트웨어 개발
◦
소통(Communication) e.g. Inner Monologue - 토론, ChatDev - 협업
◦
탐사(Environment Exploration) e.g. Voyager - 소스코드 자체 강화
•
어떻게 행동에 이르게 하는가? (Action production)
▪
행동하는 중(in-action)
•
할 수 있는 행동은 무엇인가? (Action space)
◦
내부 지식 활용
◦
외부 도구 활용
▪
데이터베이스나 지식 창고(Knowledge Bases): ChatDB - SQL, OpenAGI - 도메인 특화 지식 창고 활용. 이때
▪
API나 다른 모델의 출력: e.g. HuggingGPT - Huggingface 모델 API, TPTU - LaTex 컴파일러
▪
행동한 이후(after-action)
•
행동으로 어떤 일이 일어나는가? (Action impact)
◦
환경을 바꾼다. e.g. GITM, Voyager
◦
에이전트 내부 상태를 바꾼다. e.g. SayCan - 환경을 이해하는 에이전트의 상태 갱신
◦
새로운 액션을 호출한다.
•
에이전트의 수에 따라
◦
단일 에이전트(Single-Agent): e.g. ReAct, Reflexion
◦
다중 에이전트(Multi-Agent): e.g. DyLAN, AgentVerse, MetaGPT
▪
수직형(Vertical): 하나의 리드 에이전트가 다른 에이전트를 관리
▪
수평형(Horizontal): 모든 에이전트가 동등한 지위를 가지고 그룹 토론을 수행
•
애플리케이션 도메인에 따라
◦
범용작업: e.g. AutoGPT
◦
심리학: e.g. TE
◦
경제학, 사회과학: e.g. Horton, Social Simulacra, Generative Agents, AgentSims,
◦
법학: e.g. ChatLaw
◦
자연과학: e.g. ChemCrow
◦
교육: e.g. CodeHelp, MathAgent
◦
산업 자동화: e.g. GPT4IA, IELLM, TaskMatrix
◦
소프트웨어 엔지니어링: e.g. ChatDev, MetaGPT
◦
로보틱스: e.g. ProAgent, SayCan, SayPlan
•
에이전트에 있어 일반적으로 거론되는 문제점
◦
엔지니어링으로 해결되고 있는 문제들
1.
자체 검증 메커니즘: 에이전트가 자체적으로 출력을 평가하고 검증할 수 있는 능력이 필요.
2.
설명 가능성: 에이전트의 의사결정 과정과 출력에 대한 설명이 필요하여 사용자 신뢰 확보가 중요.
◦
효율성: LLM을 N번 재호출하기 때문에 너무 느림.
◦
신뢰성: LLM 에이전트의 신뢰성과 일관성 있는 성능이 부족.
◦
과도한 반복 루프: 에이전트가 진전 없이 반복 작업을 하는 문제.
•
실제로 Agentic Workflow 를 만들면서 발생했던 문제점과 시행착오는 아래 엔트리에 정리한다.
◦