
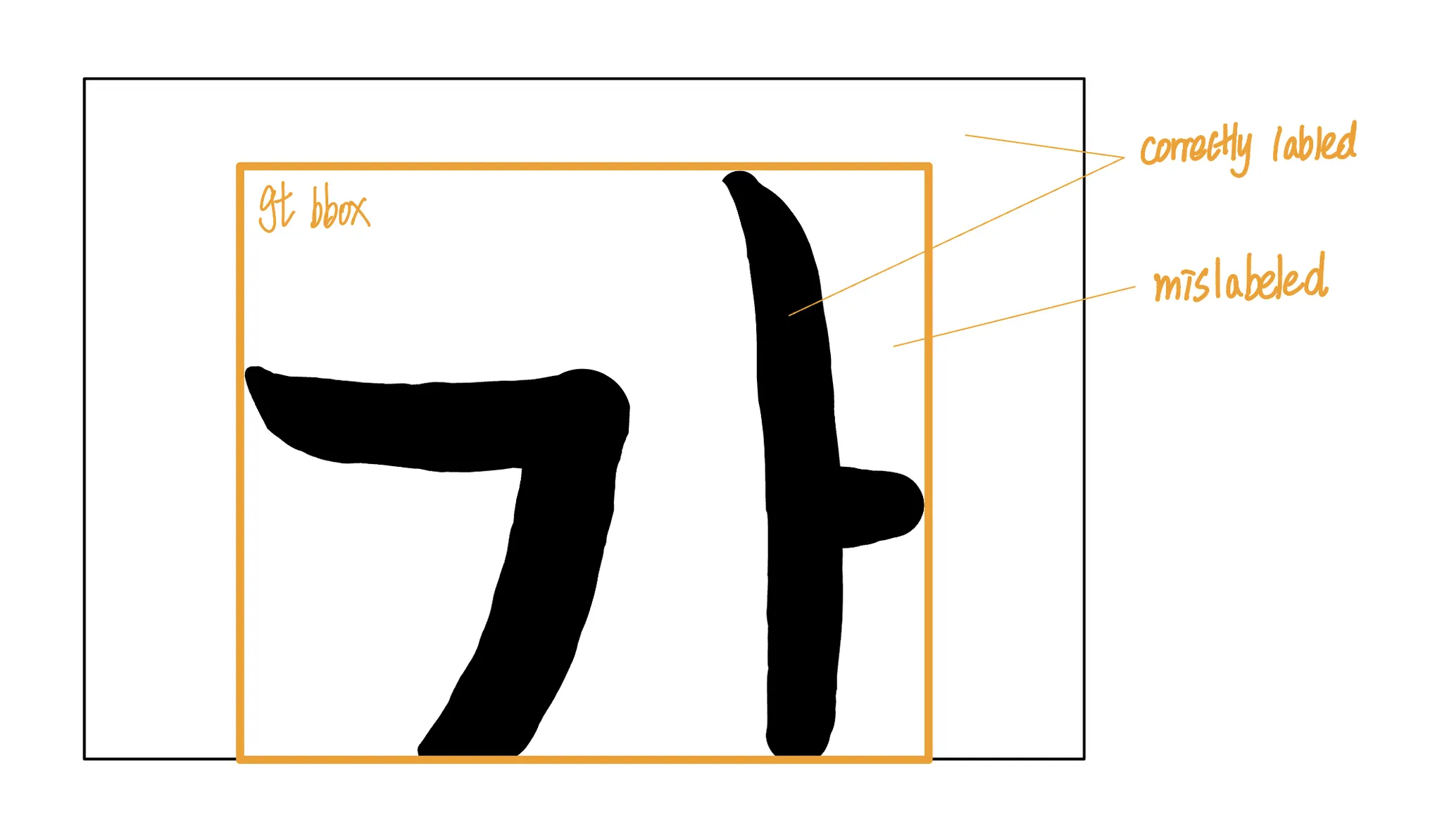
특히 OCR 도메인에서는 text detection 을 위한 정답(GT) bounding box 내부에 실제로 문자가 존재하는 영역이 극히 일부 픽셀에 불과한 경우가 대부분이다. Bounding box 내부라고 하더라도 패턴이 두드러지게 나타나는 지역이 있을 수도 있고, 패턴이 두드러지지 않는 지역이 있을 수도 있다. 하지만 이들을 하나의 bounding box 로 표현하면, bounding box 내부에서도 어떤 부분이 해당 bounding box 를 text 라고 판단하는 데 많이 기여했는지에 대한 정보가 전부 사라진다. 이는 classification 데이터밖에 없으므로 사물의 위치 정보를 얻을 수 없다는 생각과 다를 것이 없다(from1).
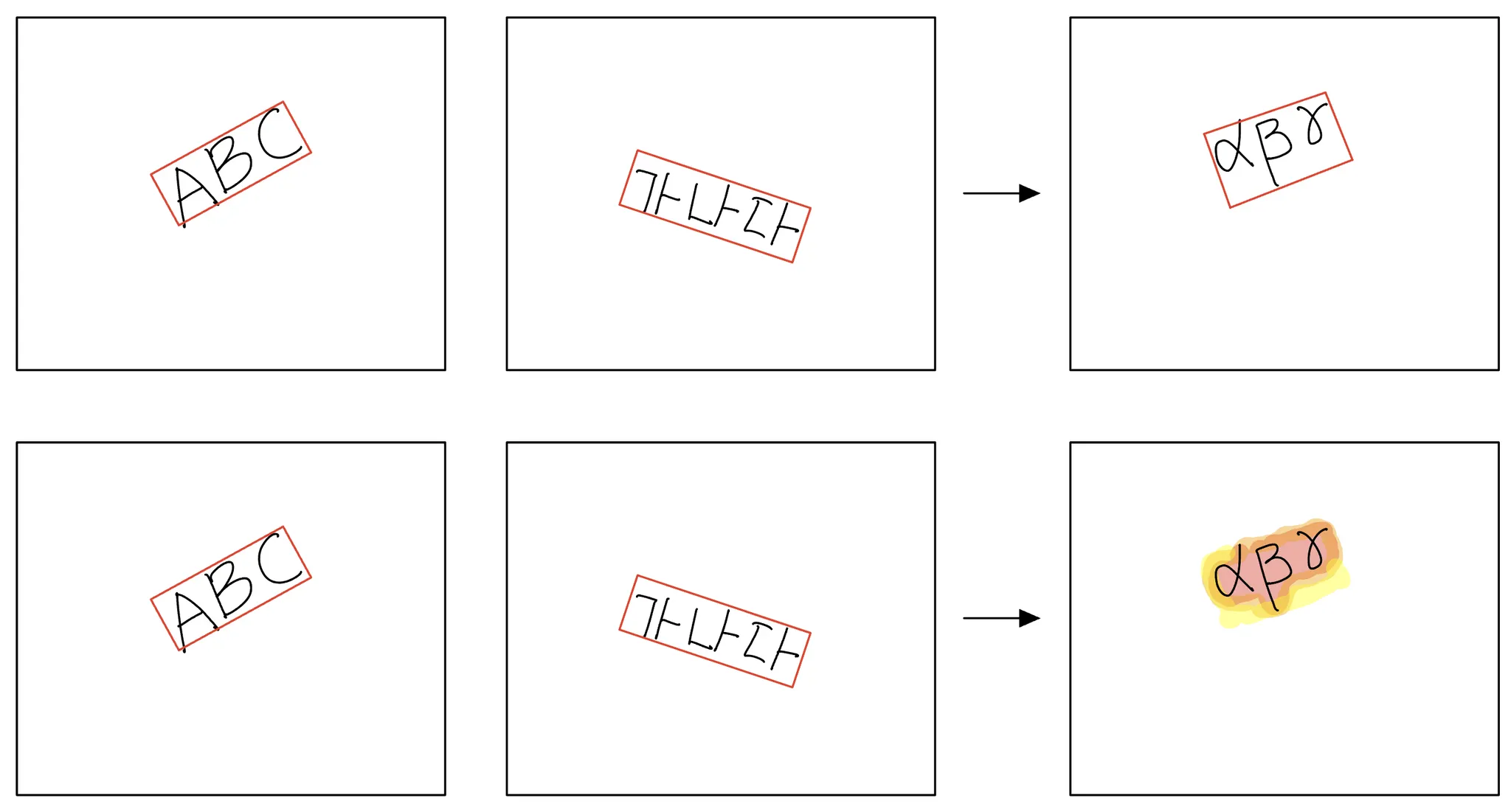
정리하면, OCR의 문자 존재 영역 검출(text detection)문제와 같이 bounding box 내부의 패턴이 sparse 하지만 bounding box 보다 정밀한 데이터 취득이 어려운 경우 binary segmentation 문제로 bounding box 내부와 외부를 구분하도록 학습시키면 bounding box 내부 픽셀 각각에 패턴이 존재할 확신도(confidence score)를 얻어낼(from3) 수 있어서 패턴의 위치를 조금 더 정밀하게 파악할 수 있다. 이것이 일부 OCR 연구들이 detection 모델 대신 segmentation 모델을 사용(from2)하는 이유이다.
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료들.
1.
None
from : 과거의 어떤 생각이 이 생각을 만들었는가?
2.
3.
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는가?
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는가?
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되고 이어지는가?
1.
참고 : 레퍼런스
1.
None