
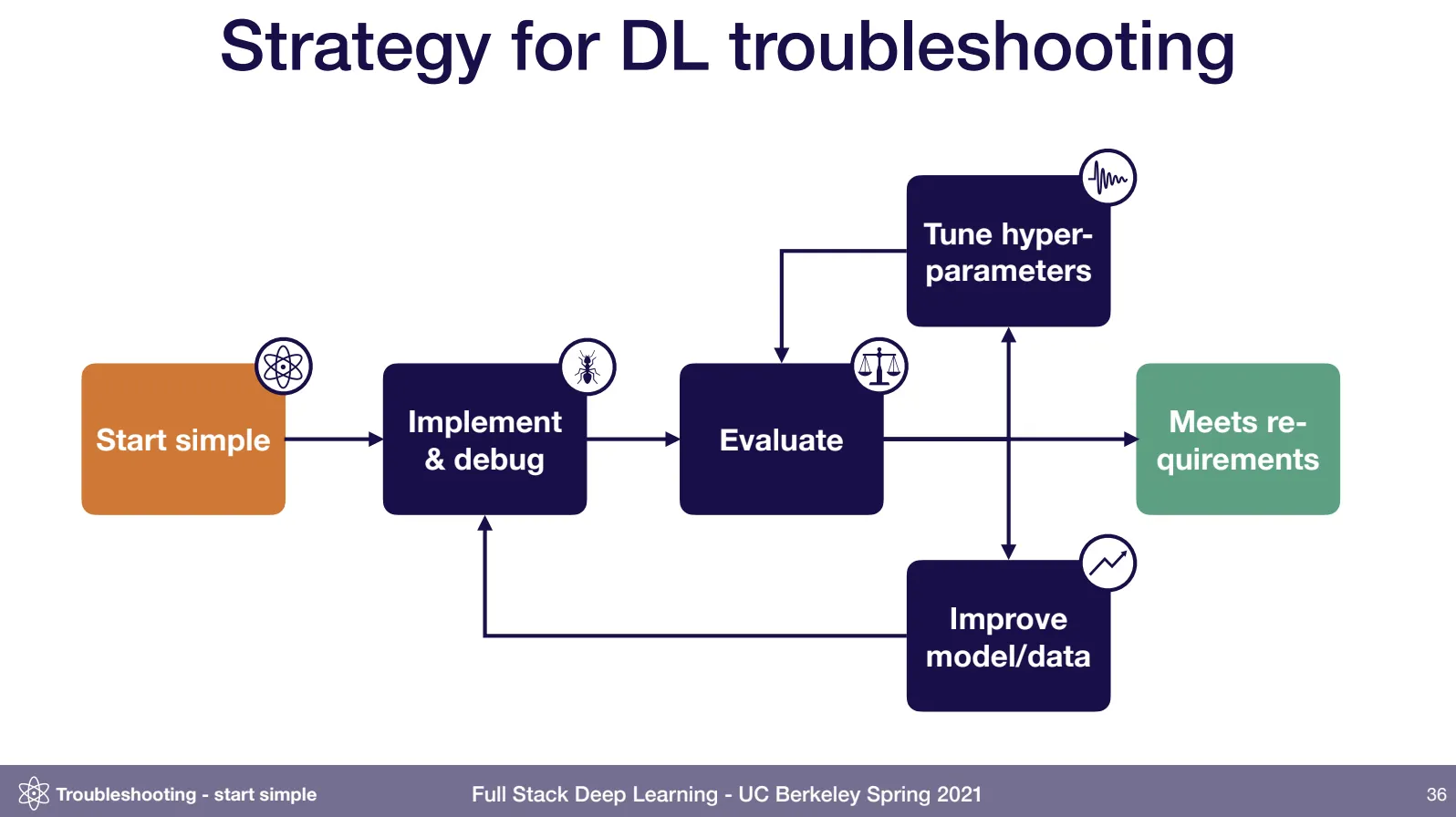
Start simple, 간단하게 시작하고 완성하라. 최대한 작은 모델, 작은 테크닉, 최대한 적은 데이터, 최대한 적은 코드만 이용해서 조금씩 검증해 나가며(from2) 동작하는 시스템을 확장해 나가라.
1.
첫째, 최대한 작은 모델과 작은 데이터셋만 써라.
a.
직접 구현하는 경우, 첫 버전은 200줄 이상 새로운 코드를 쓰지 마라 제발.
b.
이미 구현되어 잘 마련되어 있는 컴포넌트들(프레임워크 포함)을 잘 가져다 써라.
c.
데이터 파이프라인도 빼기 위해, 메모리에 올라갈 만큼만 데이터를 준비해라.
d.
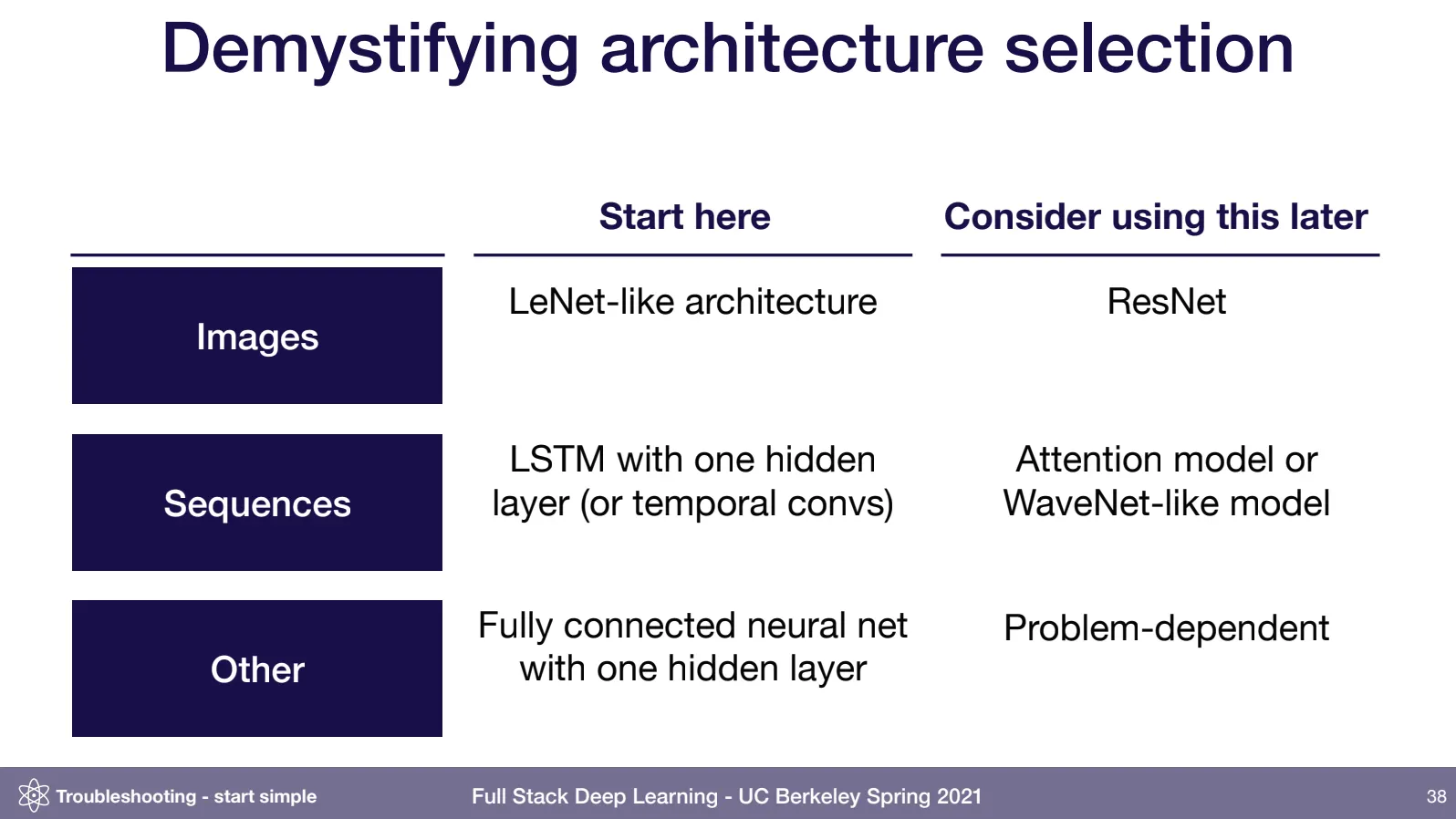
시작선은 이미지 LeNet, 시퀀스 LSTM, 이외에는 MLP 이다.
2.
둘째, 기본 옵션만 써라.
a.
배치 정규화나 데이터 정규화, 혹은 L1, L2 규제들도 다 빼라.
b.
이것들은 굉장히 많은 디버깅 요소들을 만든다.
3.
셋째, 학습이 될 만큼만, 최대한 적은 정규화만 넣어준다.
4.
넷째, 복잡한 문제를 잘개 쪼개, 가장 쉬운 문제를 풀어본다.
5.
다섯째, 한 단계를 지날 때마다 다른 디바이스에서 테스트를 해 보면 좋다. 특히, TensorFlow 와 TPU 를 사용하는 경우 COLAB 에서 테스트해 보자(from1).
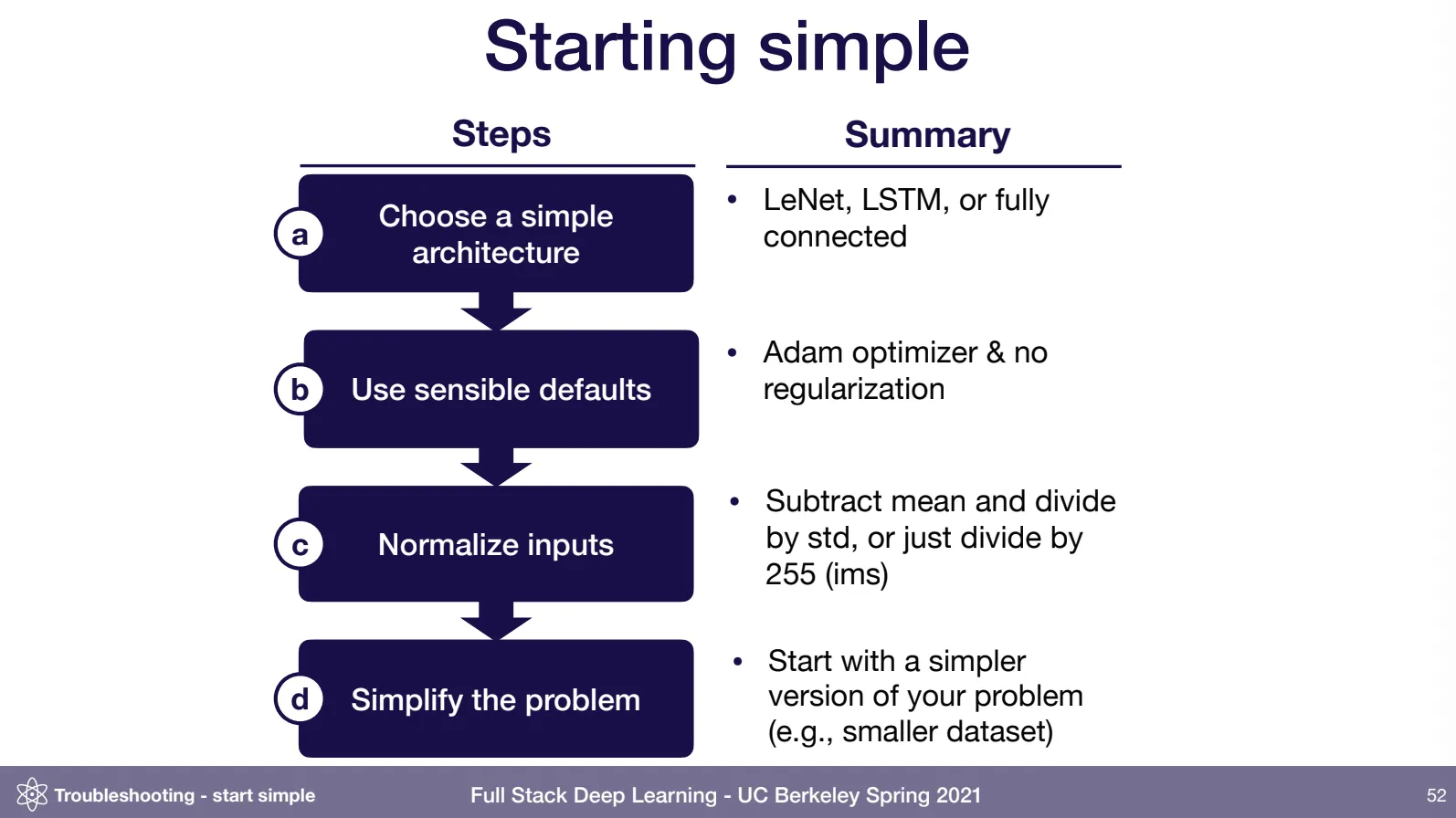
그냥 일단 이것만 써서 단순 classification 모델만이라도 만들어본다음 진행해라!

다 빼라! 학습율은 그냥 저것만 써라!

적은 데이터, 간단한 모델, 기본 세팅, 간단한 문제.

parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료들.
1.
None
from : 과거의 어떤 생각이 이 생각을 만들었는가?
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는가?
1.
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는가?
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되고 이어지는가?
2.
참고 : 레퍼런스
