
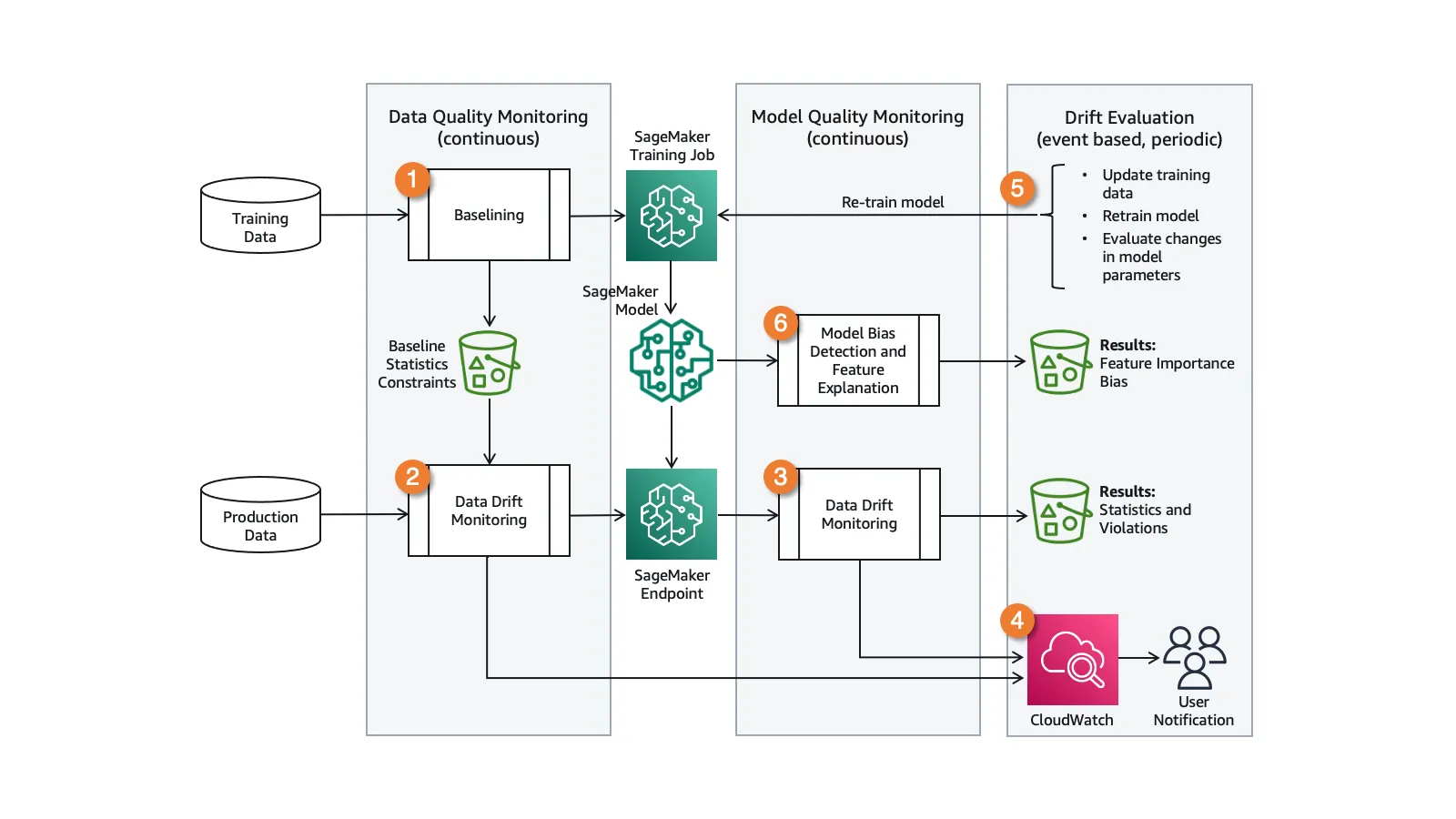
모델링 과정(from1)이나 모델 성능 모니터링(from3) 과정에서 베이스라인은 모델이 최소한으로 확보해야 하는 성능에 대한 기준선을 의미(참고7)하기도 하지만, 데이터 드리프트와 관련해서는 모델이 학습되었던 당시의 상황과 비교(from2)하여 받아들일 수 있는 데이터의 통계적 특성 차이의 기준선을 의미하기도 한다(참고2,8).
그림(참고4): 아래 그림은 AWS Sagemaker 모델 드리프트 모니터링 시스템 다이어그램이다. 좌측에 보면 Training Data 가 있는데, 이 데이터가 Baselining 태스크의 입력으로 들어가고 있음을 알 수 있다.
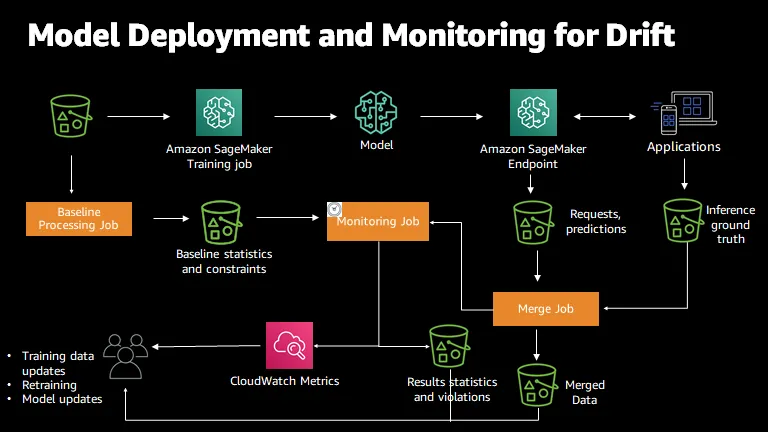
또다른 그림을 보자. 아래 그림은 AWS Sagemaker 공식 예제 문서에서 제공하는 모델 드리프트 시스템 다이어그램이다. Sagemaker Training job 으로 입력되는 데이터와 동일한 데이터가 Baseline Processing Job 에 입력된다. 처리 결과물은 베이스라인 데이터셋의 통계량과 제약조건임을 알 수 있다.
그림(참고5)
실제로 AWS Sagemaker Python SDK 를 이용해 아래와 같은 코드를 실행하면, S3에 constraints.json 파일과 statistics.json 파일이 저장된다.
코드(참고6)
from sagemaker.model_monitor.dataset_format import DatasetFormat
from sagemaker import get_execution_role
s3_path = "s3://monitoring/xgb-churn-data"
monitor.suggest_baseline(
baseline_dataset=s3_path + "/training-dataset.csv",
dataset_format=DatasetFormat.csv(header=True),
output_s3_uri=s3_path + "/baseline/",
wait=True)
Python
복사
위 AWS 예제 스크립트의 경우 데이터 특징들의 통계량이나 타입 등을 기반으로 기본적인 베이스라인을 자동으로 생성하지만 모델의 성능과 관련된 베이스라인은 생성할 수 없다.
모델의 성능까지 모니터링하기 위해서는 현재 모델에 대한 성능 정보를 모니터에 제공할 수 있어야 하고, 성능 정보를 모니터에 제공하려면 ModelQualityMonitor 클래스를 사용해야 한다. 이 클래스의 인스턴스에서 suggest_baseline() 메서드를 호출하면 모델의 예측값과 정답값에 대한 정보를 인자로 전달할 수 있어 현재 모델의 성능 베이스라인을 만들 수 있게 된다.
코드(참고7)
probability,prediction,label
0.01516005303710699,0,0
0.1684480607509613,0,0
0.21427156031131744,0,0
0.06330718100070953,0,0
0.02791607193648815,0,0
0.014169521629810333,0,0
0.00571369007229805,0,0
0.10534518957138062,0,0
0.025899196043610573,0,0
Python
복사
test_data/validation_with_predictions.csv
model_quality_monitor = ModelQualityMonitor(
...
)
job = model_quality_monitor.suggest_baseline(
job_name=baseline_job_name,
baseline_dataset=baseline_dataset_uri, # test_data/validation_with_predictions.csv
dataset_format=DatasetFormat.csv(header=True),
output_s3_uri = baseline_results_uri,
problem_type='BinaryClassification',
inference_attribute= "prediction",
probability_attribute= "probability",
ground_truth_attribute= "label"
)
job.wait(logs=False)
Python
복사
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료들.
1.
None
from : 과거의 어떤 생각이 이 생각을 만들었는가?
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는가?
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는가?
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되고 이어지는가?
1.
None
참고 : 레퍼런스