
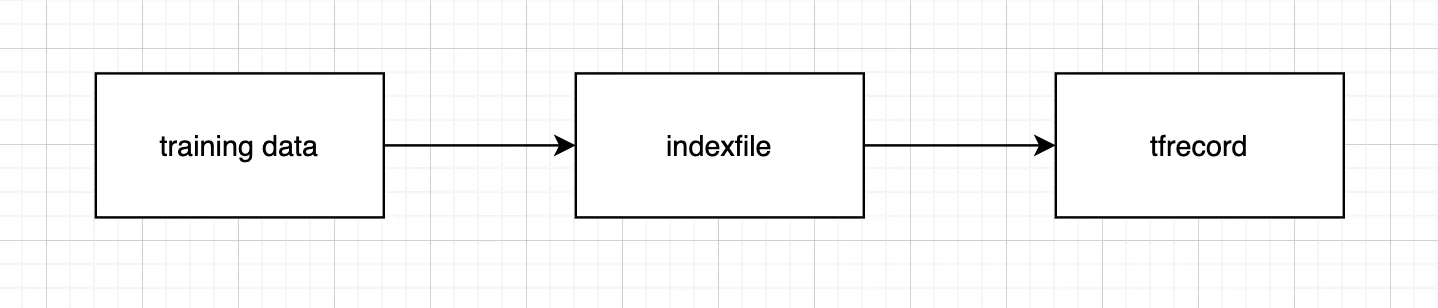
tfrecord 가 만들어지는 과정 (1)
대용량 데이터 처리에 특화된, 텐서플로의 직렬화된 데이터셋 파일 .tfrecord 는 위와 같은 과정을 거쳐 만들어진다. 첫째, N 개의 훈련 데이터파일이 어느 경로에 위치하는지에 대한 N 행의 인덱스파일을 m 개 만든다. 둘째, 인덱스파일에 작성된 내용으로 m 개의 tfrecord 파일을 생성한다. 이때, N 에 비해 m 은 매우 작다.
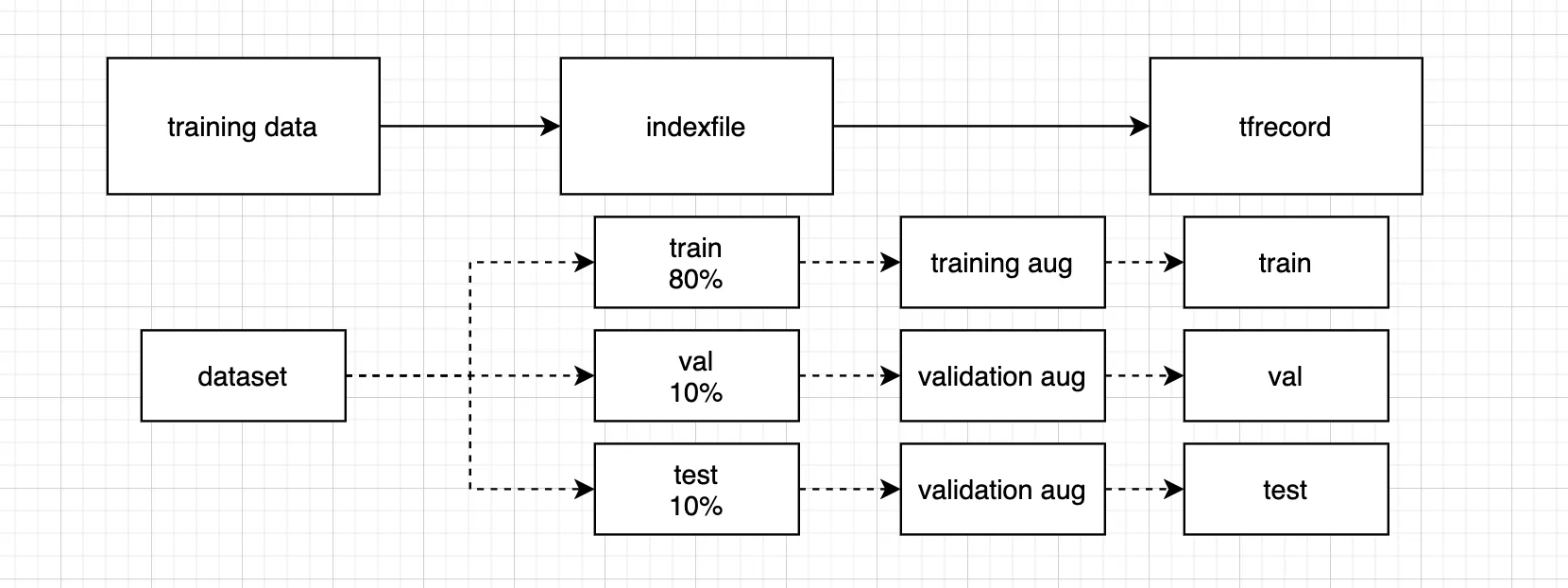
tfrecord 가 만들어지는 과정 (2)
나는 최종적으로 train 데이터셋을 1개의 .tfrecord 파일, val 데이터셋을 1개의 .tfrecord 파일, test 데이터셋을 1개의 .tfrecord 파일로 만드는 것이 목표이다. 인덱스파일 하나당 하나의 .tfrecord 파일을 생성할 수 있으므로, 인덱스파일을 train 데이터셋, val 데이터셋, test 데이터셋 각각에 대해서 만들었다. 총 세 개의 인덱스파일이 생성된 셈이다.
그런데 이때 전체 데이터셋의 80% 에 해당하는 train 데이터셋의 index 파일이 지목하는 이미지들에 대한 augmentation 결과물을 tfrecord 에 저장하는 일은 COBLAB 런타임 제한인 24시간 내에 처리되지 않았다. tfrecord 를 작성하던 도중 계속 런타임이 끊기는 문제가 발생했던 것이다(참고1). 런타임이 끊기기 전 마지막으로 진행 상황을 확인하면 train 데이터셋의 약 60% 정도가 진행되었던 것으로 기억한다.
나는 이 문제를 멀티코어 프로그래밍으로 풀어낼 수 있다고 보았다. 여기서 딱 두 배만 빨라져도, COLAB 자원을 두 배나 더 많이 사용할 수 있는 것이다. 하지만 이를 멀티코어 연산으로 만들 때 가장 걱정되는 것은 당연히 race condition 이다. 언어 차원에서도 race condition 을 방지하기 위해 자원에 락을 거는 등 꽤 많은 노력을 할 것으로 예상된다. 그럼 당연히 분산처리의 혜택을 온전히 얻어내지 못할 것이다. 예를 들어 하나의 인덱스 파일 자원에 여러 개의 코어가 동시에 읽기 작업을 수행하고, 하나의 .tfrecord 파일 자원에 여러 개의 코어가 동시에 쓰기 작업을 수행하는 경우를 생각해 보자. 이미지파일의 augmentation 결과물을 디스크에 쓰는 데 소요되는 시간이 길다면, .tfrecord 파일에 augmentation 결과물을 직렬화하여 쓰기 작업을 시작한 코어가 해당 자원을 놓아줄 때까지 다른 코어들은 새로운 augmentation 을 하지 못하고 한참을 대기해야 할 것이다. 이러한 문제를 방지하기 위해 각 프로세스가 독립적으로 파일 자원을 잡고 쓰기작업을 할 수 있도록 변경해 주어야 한다.
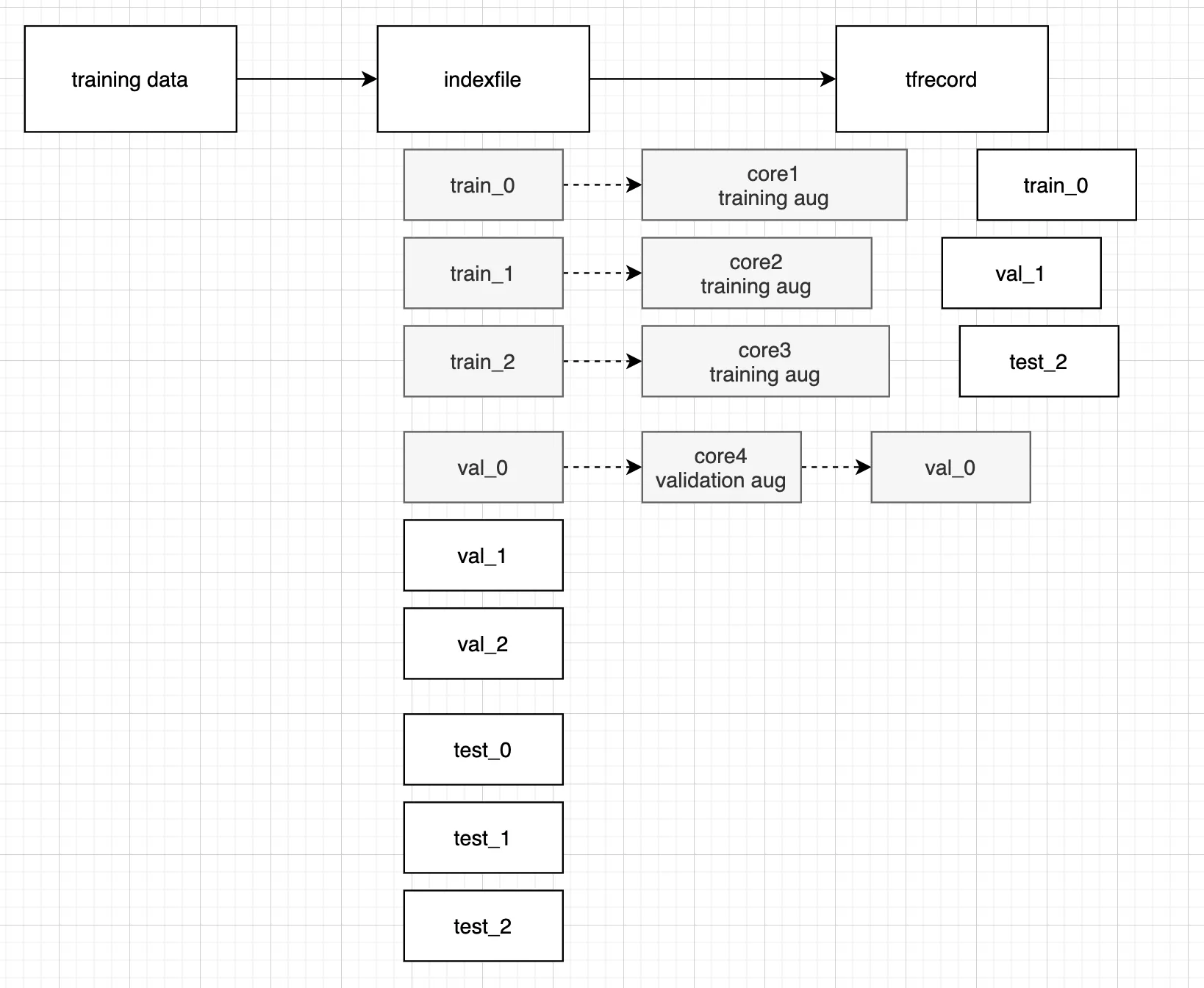
tfrecord 생성과정을 병렬처리한다면?
그래서 인덱스파일을 여러개로 쪼갰다. 이렇게 쪼개고 나면, 각 프로세스가 다른 파일에 읽기 작업을 수행하고 다른 .tfrecord 파일에 쓰기 작업을 수행할 수 있기 때문에 병렬처리를 하더라도 race condition 이 일어나지 않을 것이다. 하지만 이렇게 해도 문제가 있다.
1.
training set 은 validation set 이나 test set 보다 보통 더 크다.
2.
core 의 수보다 indexfile 의 수가 일반적으로 더 많다.
val 데이터나 test 데이터의 augmentation 과 .tfrecord 쓰기 작업을 완료한 프로세스와 코어들이 놀지 않고 다음 일을 할 수 있도록 만들어야 한다.
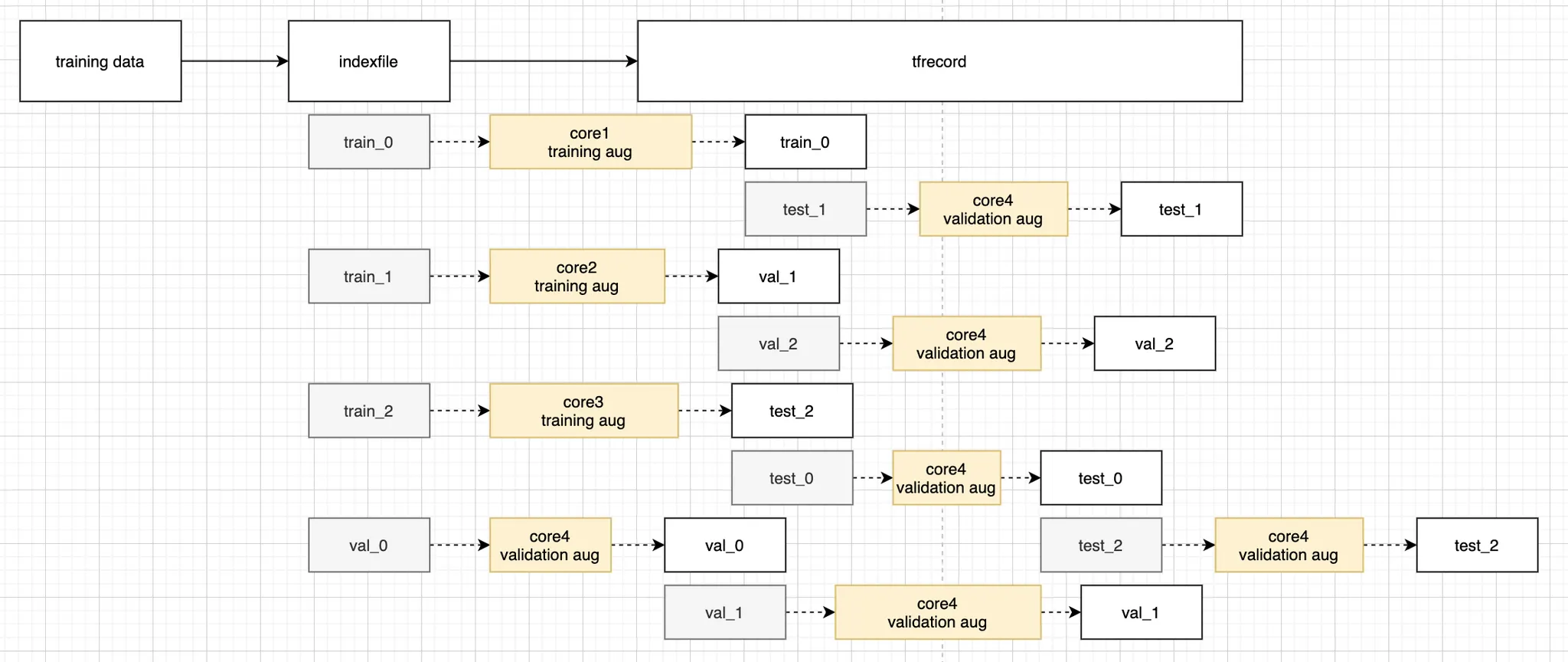
이것을 처리해줄 수 있는 방법으로 callback function 에서 전역 변수 컨테이너에 값을 읽고 쓰는 방법(참고2)을 생각했다. 하지만 이 방법은 옳지 못하다. Python 은 GIL 에 의해 Thread 를 사용할 수 없다(참고3). Process 는 Thread 와 다르게, 프로세스마다 프로그램 영역(program code) 과 전역변수 영역(data) 을 모두 따로 가지고 있기 때문이다.
저걸 고민하면서 어떻게하지 걱정하고 있었는데 p.starmap_async 같은 것들이 존재한다. 이것은 그냥 간단하다. p.starmap_async 는 p.map() 과 p.map_async() 에서 여러 개의 인자를 받을 수 있도록 확장된 버전일 뿐이다 (참고5). 그렇다면 p.map() 과 p.map_async() 가 무엇인가 알아보면 된다. 이들은 iterable 을 input 으로 받아, iterable 을 하나 꺼낼 때마다 pool 객체에 들어 있는 CPU 들 중 가용할 수 있는 자원들을 하나씩 차례로 꺼내 쓴다 (참고4). 따라서 우리가 위에서 복잡하게 코어별로 서로 시그널을 주고받을 수 있는 코드 가령 CPU1 : '헉헉... 좋아 나 이제 끝났으니까 다음 작업 줘!' 사용자 : '아.. 잠깐만, 기다려 음... 뭐였지? 너한테 줄 다음 작업...' CPU2 : '나도 끝났어...! 나 무슨...' 를 만들 필요조차 없다는 것을 의미한다.
p = Pool(os.cpu_count())
p.starmap_async(multiprocessing_fn, iterable_make_helper())
Python
복사
하지만 위 코드만으로 끝나면 pool 객체 내에 들어있는 CPU 들이 프로세스를 실행하고 있고, 아직 작업이 끝나지 않았음에도 python 이 다음 라인을 진행하게 된다. 이것은 우리가 의도하는 바가 아니다.
p.close()
p.join()
Python
복사
p.close() 는 프로세스에 더이상 다른 작업이 들어가지 않을 것임을 의미하고 (참고 7), p.join() 은 프로세스가 작업을 완전히 마치기를 기다린다는 의미로 쓰인다 (참고 6). 그런데... 이렇게 코드를 짜고 나서 알았던 사실이지만 google colab 의 core 수는 2개였다 아아 ㅋㅋㅋ
그래도... 두 배 빨라졌으니 좋은 것 아니겠나 하하! 썩을 (참고 8)

아래는 내 코드이다.
if DATASETNAME.lower() == 'camvid':
# 나는 데이터셋마다 다른 tfrecord 생성 규칙을 가지고 있다.
run_multicore_augmentation(generate_tfrecord_camvid_segmentation,
ignore_file_name_wildcard_patterns=[])
if DATASETNAME.lower() in ['pedestrian/surface_masking', 'pedestrian/pedestrian_sample']:
# 나는 데이터셋마다 다른 tfrecord 생성 규칙을 가지고 있다.
run_multicore_augmentation(generate_tfrecord_pedestrian_segmentation,
ignore_file_name_wildcard_patterns=[])
Python
복사
run_multicore_augmentation() 을 집중해서 보자.
index_file_name_li = [os.path.basename(fp) for fp in glob.glob(os.path.join(INDEX_FILE_DIR_FOR_TFRECORD, '*'))]
def get_next_task(
index_file_name_li,
ignore_index_file_name_wildcard_patterns
)->None:
# ingnore_file_name_wildcard_patterns 에 들어갈 input 을
# multithreading 에서 적절히 parsing 해주기 위해 사용하는 generator
_additional_ignore_index_file_names = []
for f_name in index_file_name_li:
for pattern in ignore_index_file_name_wildcard_patterns:
if re.match(pattern, f_name):
print(f'{repr(f_name)} Pre-ignored! Conversion passed.')
_additional_ignore_index_file_names.append(f_name)
for i in range(len(index_file_name_li)):
temp = index_file_name_li[:] # copy
temp.pop(i)
temp = list(set(temp + _additional_ignore_index_file_names))
yield temp
def iterable_creating_helper(
index_file_name_li,
ignore_index_file_name_wildcard_patterns=[]
):
generator = get_next_task(index_file_name_li, ignore_index_file_name_wildcard_patterns)
return [[INDEX_FILE_DIR_FOR_TFRECORD, TFRECORD_FILE_DIR, e] for e in generator]
def run_multicore_augmentation(
fn,
ignore_file_name_wildcard_patterns=[]
)->None:
global index_file_name_li
print(f'number of cpu core : {os.cpu_count()}')
p = Pool(os.cpu_count())
p.starmap_async(fn, iterable_creating_helper(index_file_name_li, ignore_file_name_wildcard_patterns))
p.close()
p.join()
Python
복사

run_multicore_augmentation(generate_tfrecord_pedestrian_segmentation,
ignore_index_file_name_wildcard_patterns=[
'train_0',
'train_1',
'train_2',
'train_3',
'train_4',
'train_5',
'train_6',
'train_7',
'train_8',
'train_9',
'test_*',
#'val_*',
])
Python
복사
참고
3.
8.