
그림 (참고1)
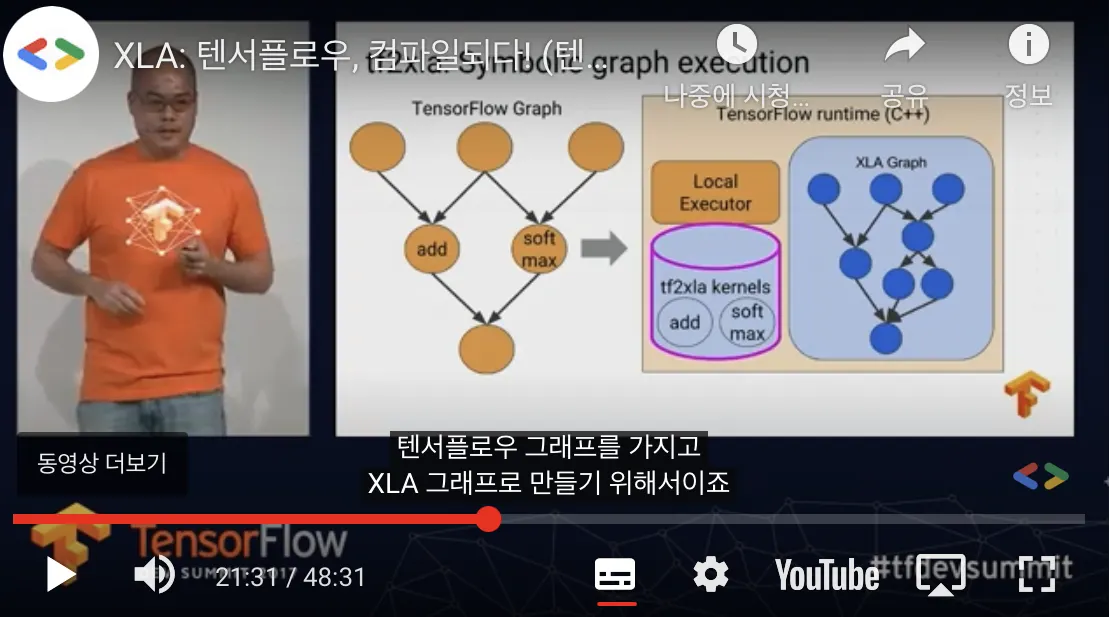
TensorFlow runtime 내의 원기둥은 tensorflow graph → XLA graph 가 가능하도록 준비된 연산들이다. 그림에서 add 는 1:1 대응되는 커널이고, softmax 는 1:3 대응되는 커널이라고 생각할 수 있다.
파이프라인을 정리하면 다음과 같다.
Python 등 API 로 TensorFlow Graph 생성 → 그래프의 일부 또는 전체를 clustering (clustering 된 부분을 하나의 노드라고 여김) → 런타임에 클러스터링된 노드를 마주치는 경우 클러스터를 JIT 컴파일하여 실행하고 캐싱
모든 TensorFlow ops 에 대해서 컴파일이 불가능하기 때문에 XLA 가 고민해야 하는 양이 많아진다. 그래프의 크기가 크고 복잡해질수록 이 문제는 더욱 복잡해질 것 같다 (참고4). 게다가 클러스터를 잘못 잡으면 자칫 사이클 그래프를 만들어 데드락이 걸릴수도 있다 (참고3).
참고
4.