
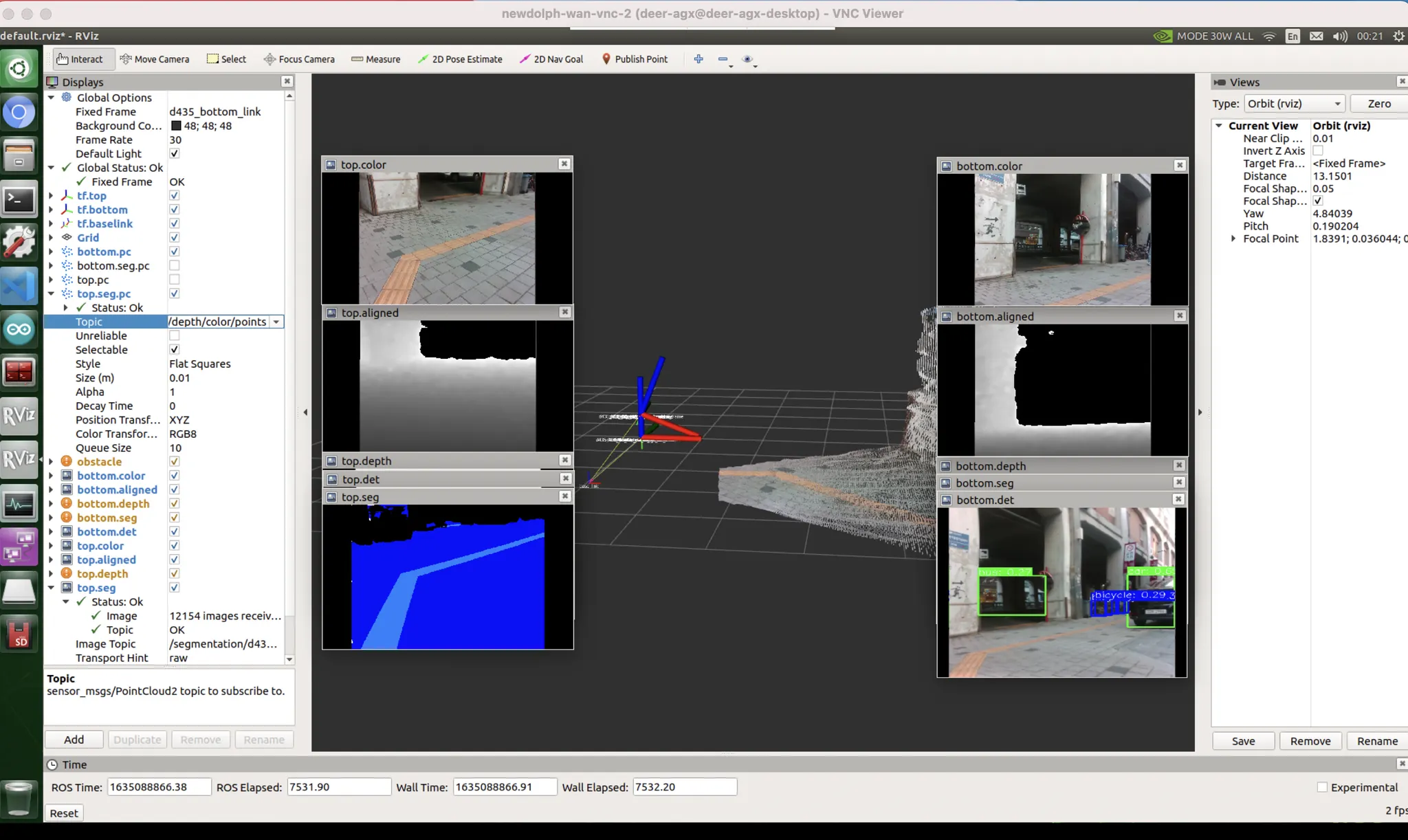
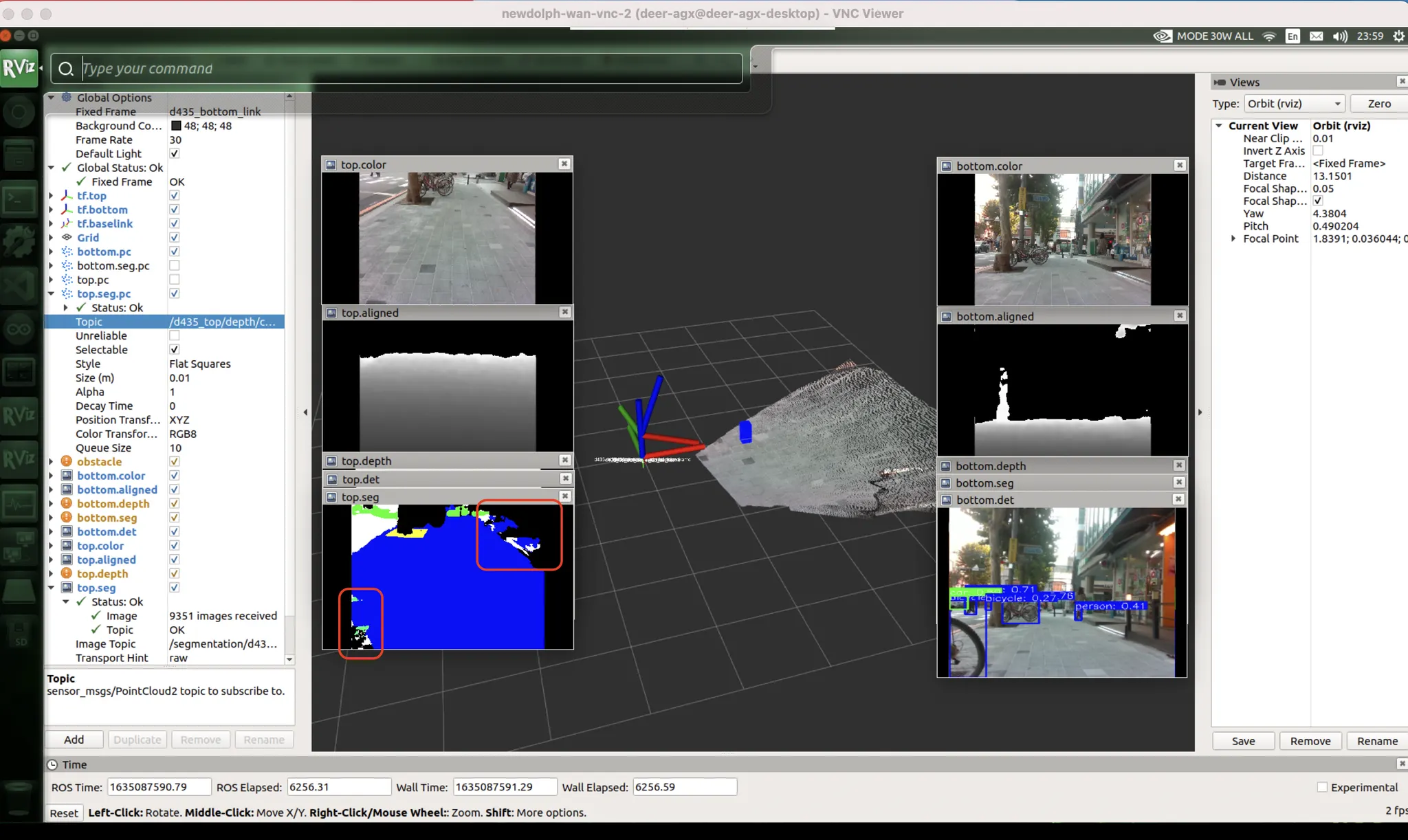
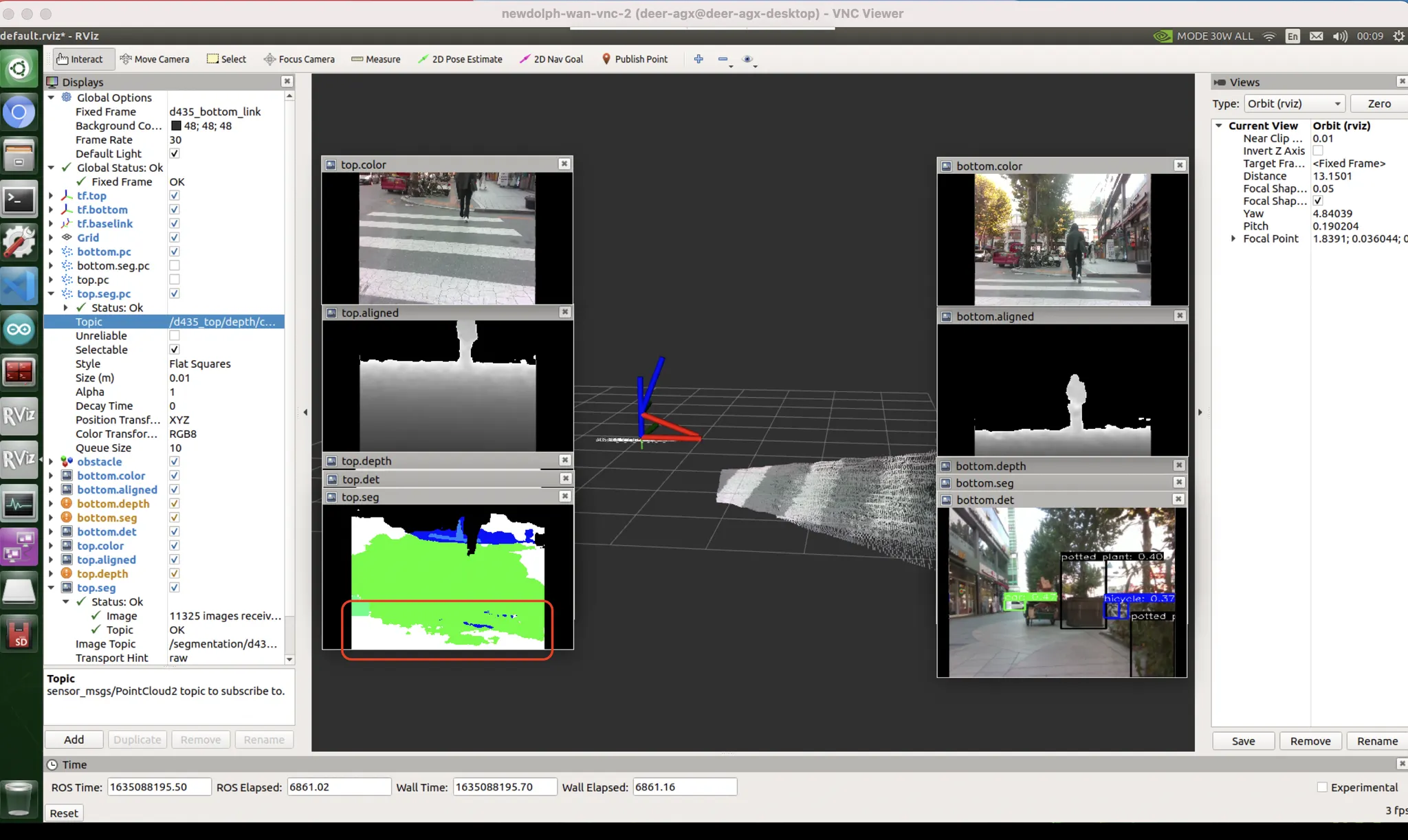
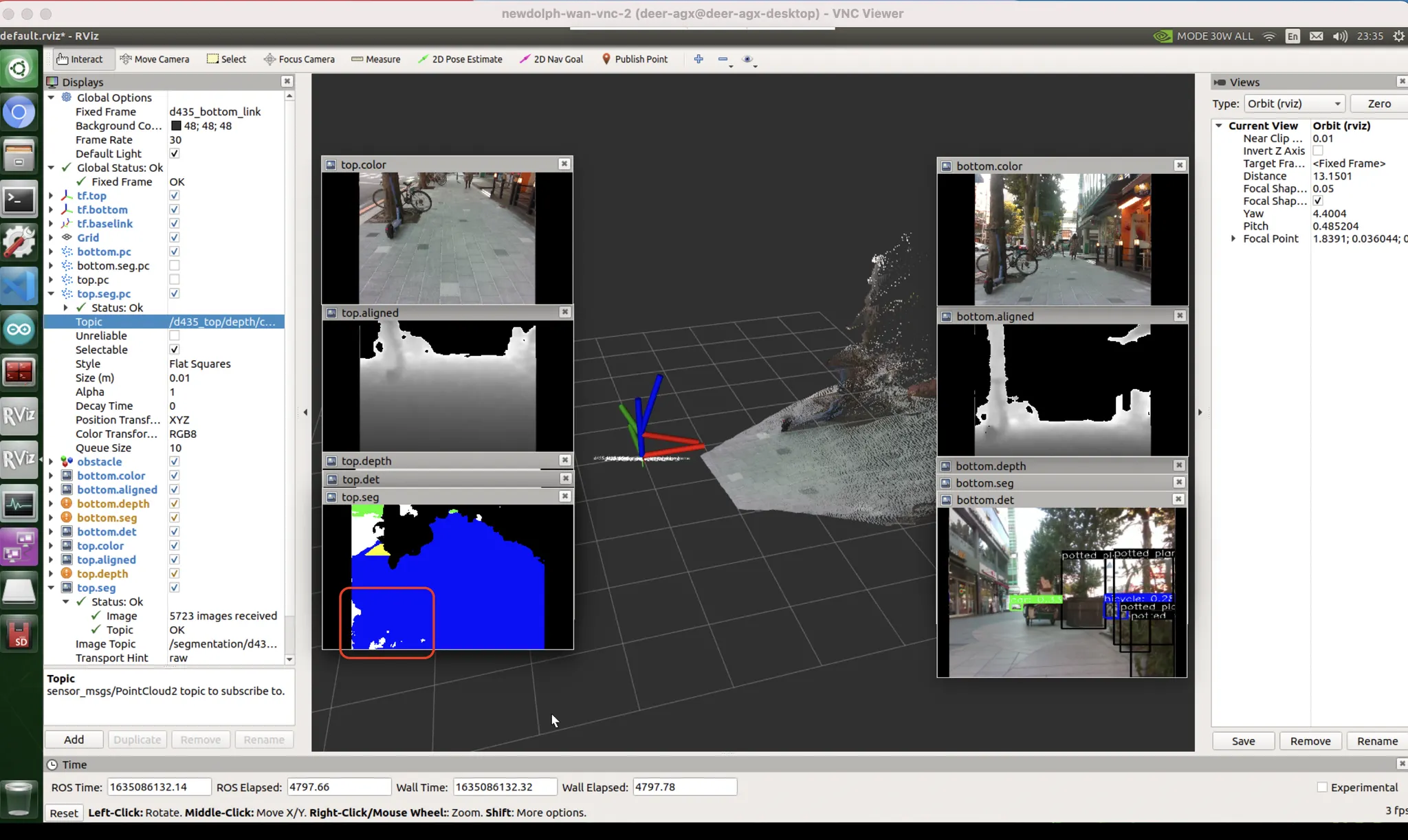
횡단보도 : 데이터 문제
가장 많이 흐물거리고 울렁거리는 케이스.
이건 데이터셋 특성상 어쩔 수 없다.
데이터셋 제작자가 하얗게 된 부분에만 surface masking 이 된게 아니라 횡단보도 노면 전체를 마스킹 해버렸음.
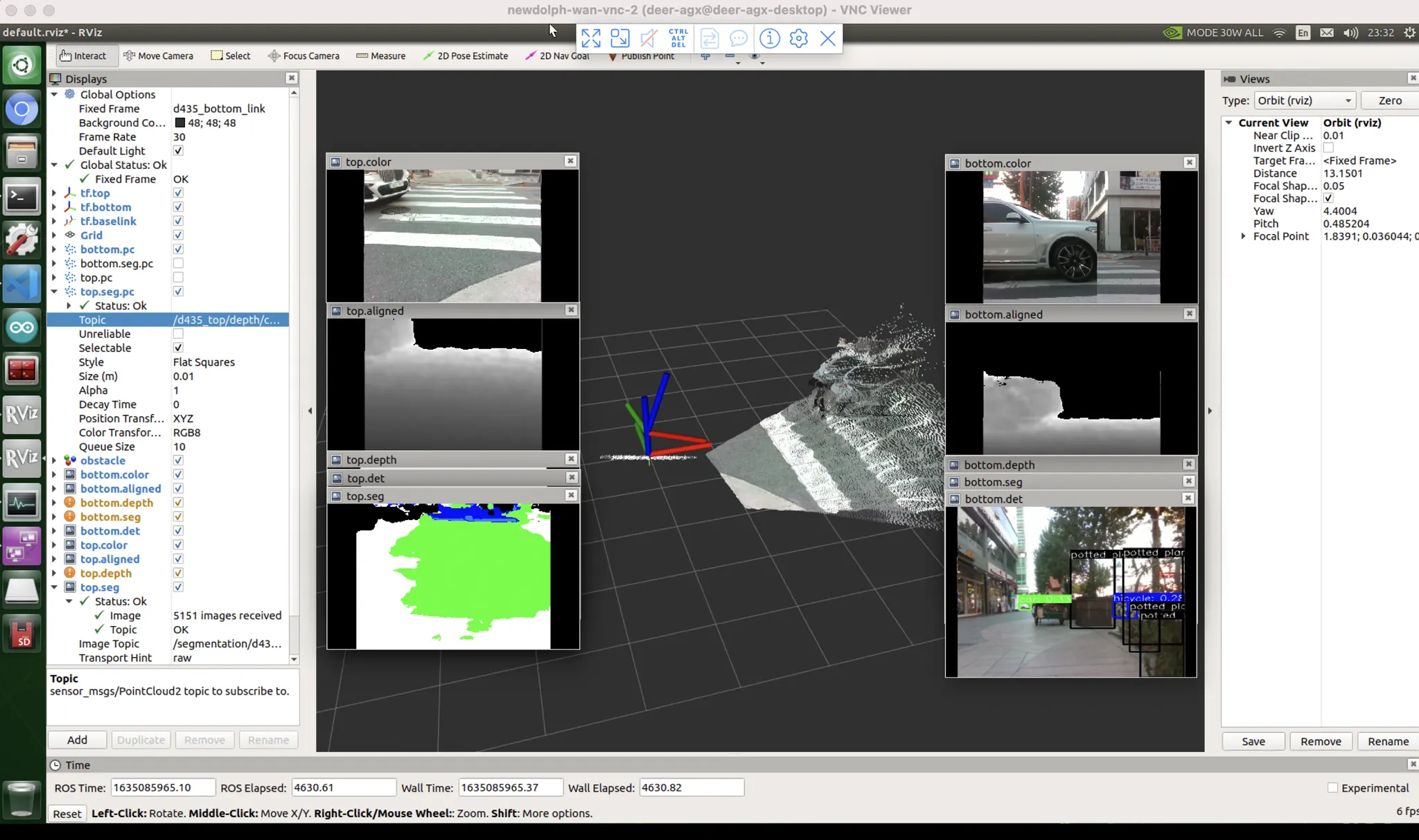
비슷한 색깔인데, 차도일수도 있고 인도일수도 있을것같은 곳을 어려워한다.
가설 : 차도에 대한 loss 를 더 추가. (차도를 틀렸을때 더 많이 혼내는것).
당연히 이건 궁극적인 해결 방법은 아님. tradeoff 라서.
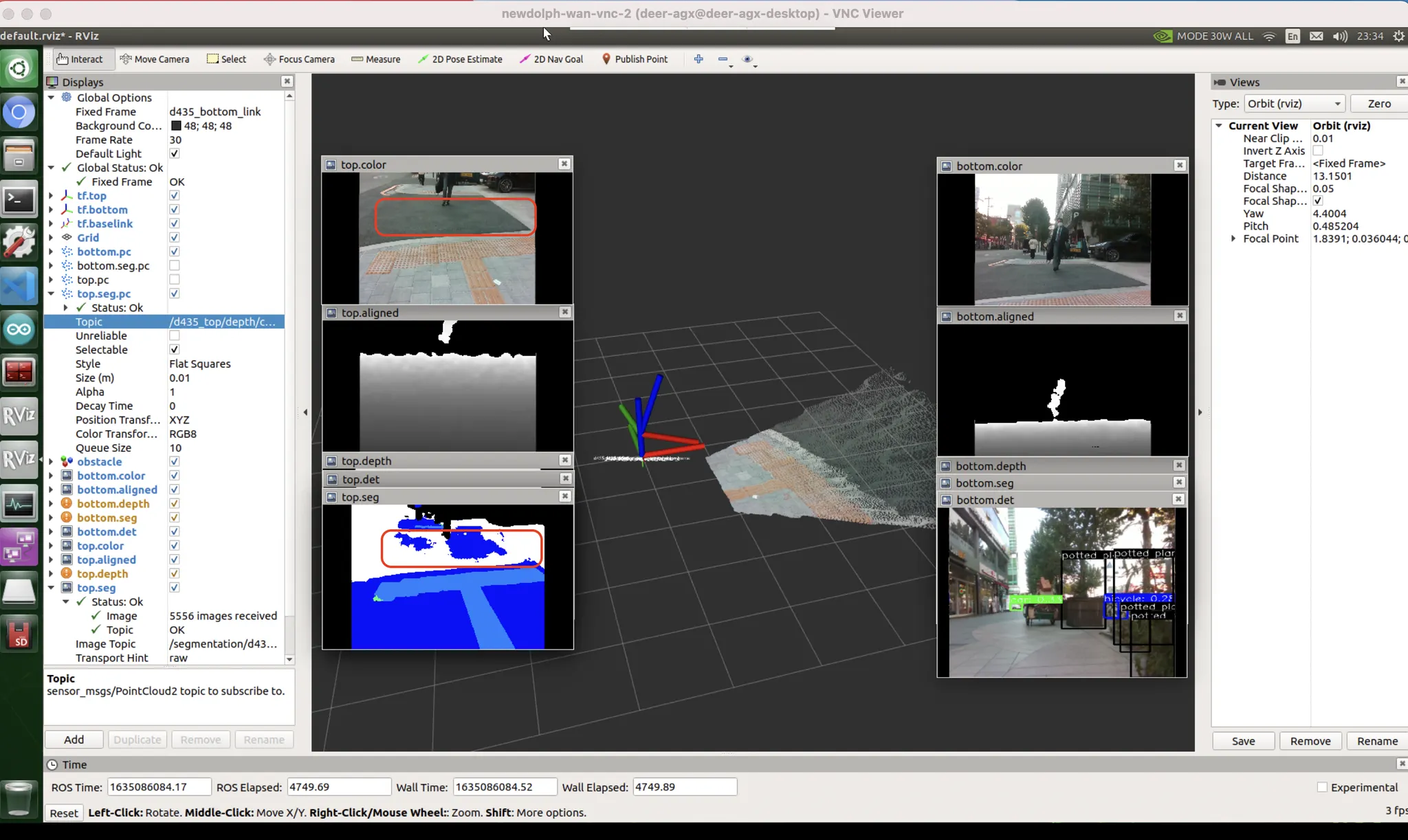
인사이트 : 경험적 판단
진짜 점자블럭은 진짜 잘 잡는다. 점자블럭이 정말 좋은 가이던스가 되어줄 수 있지 않을까?
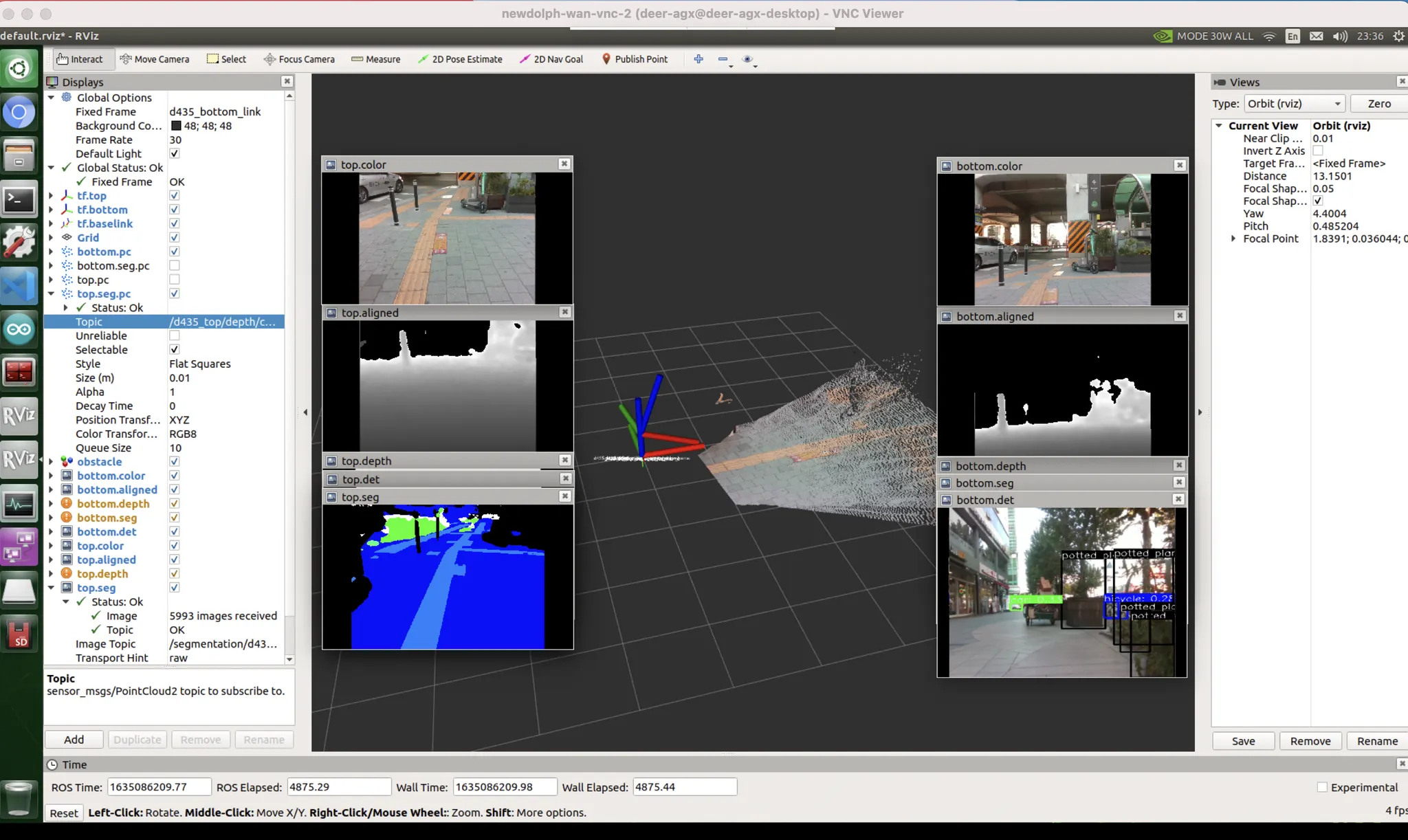
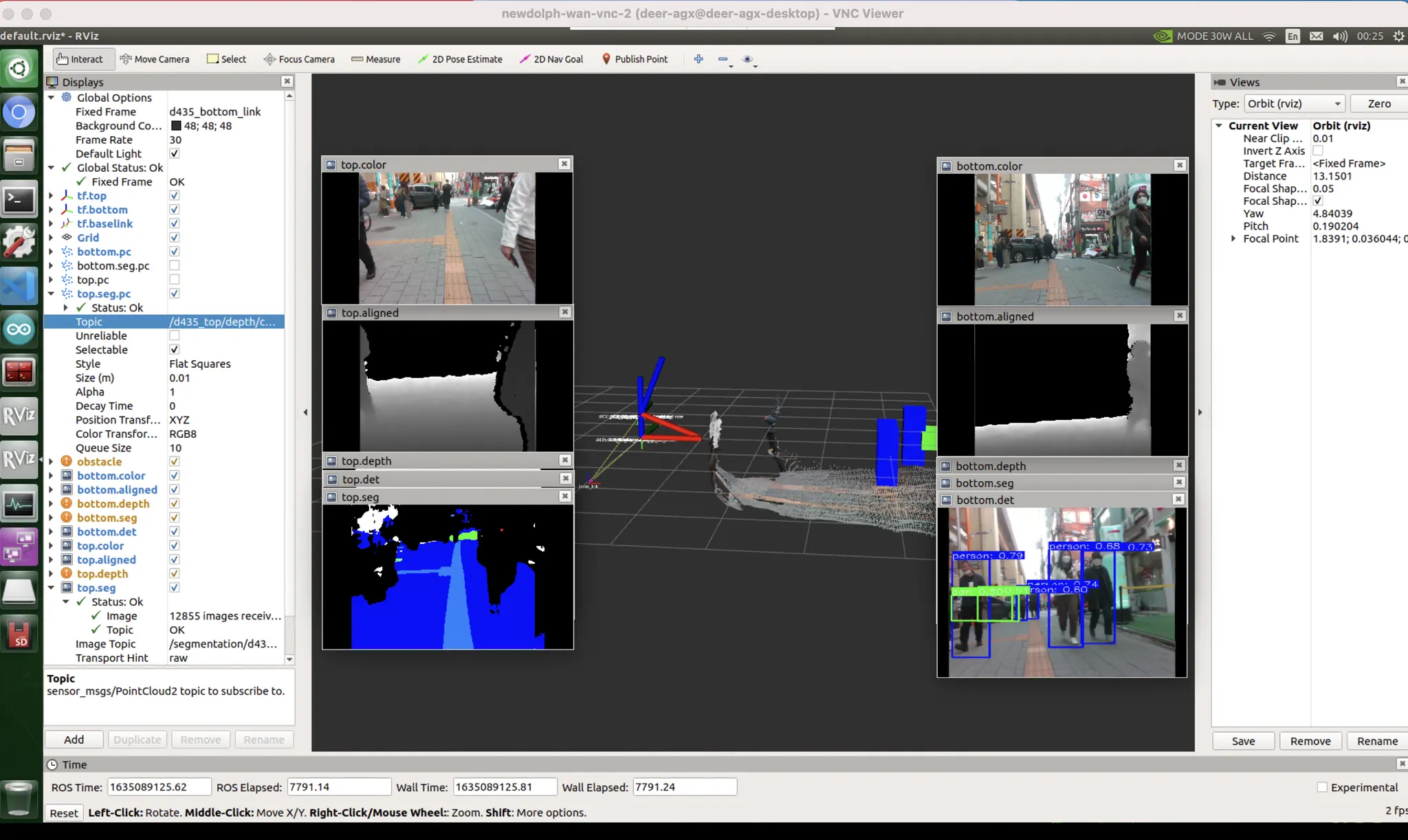
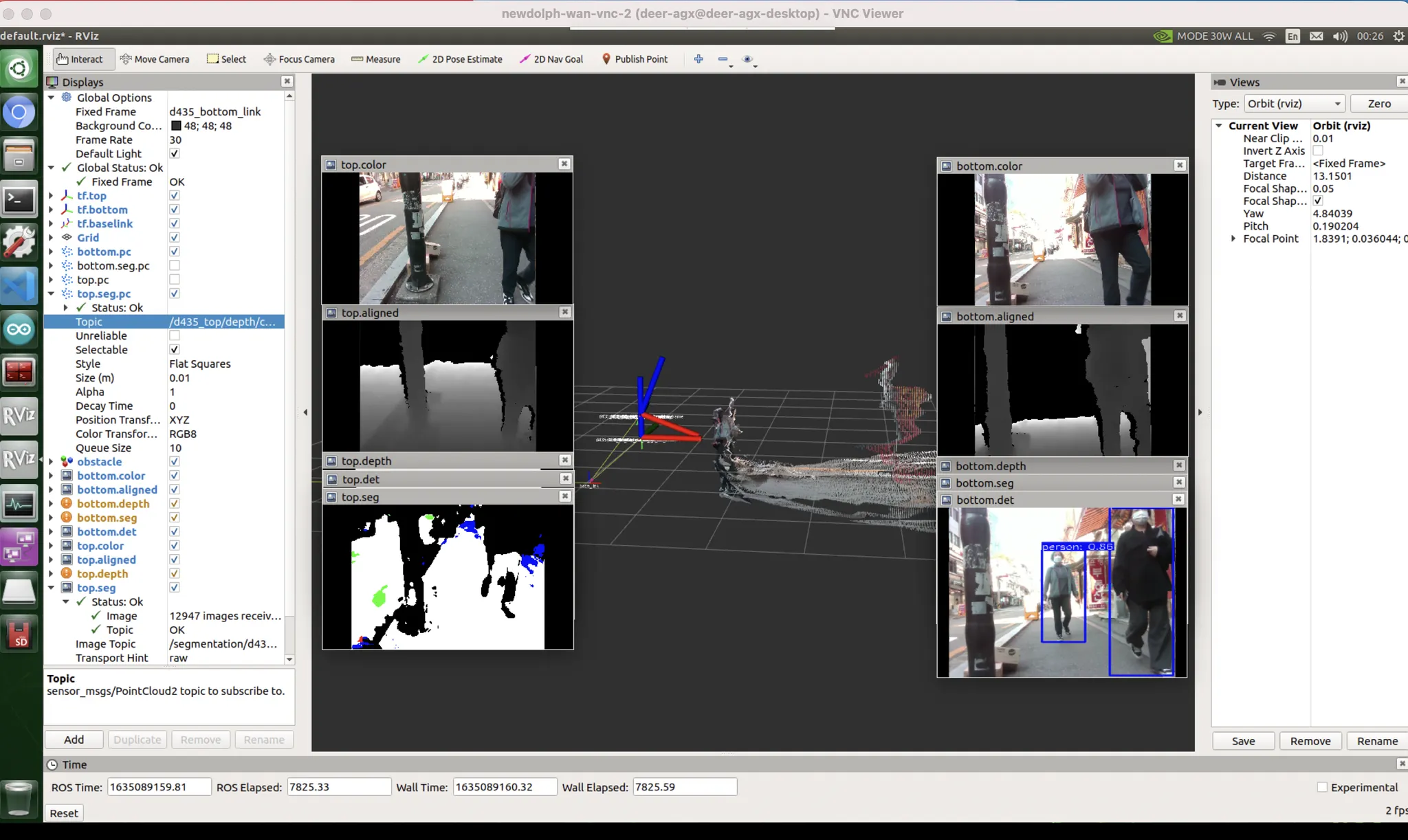
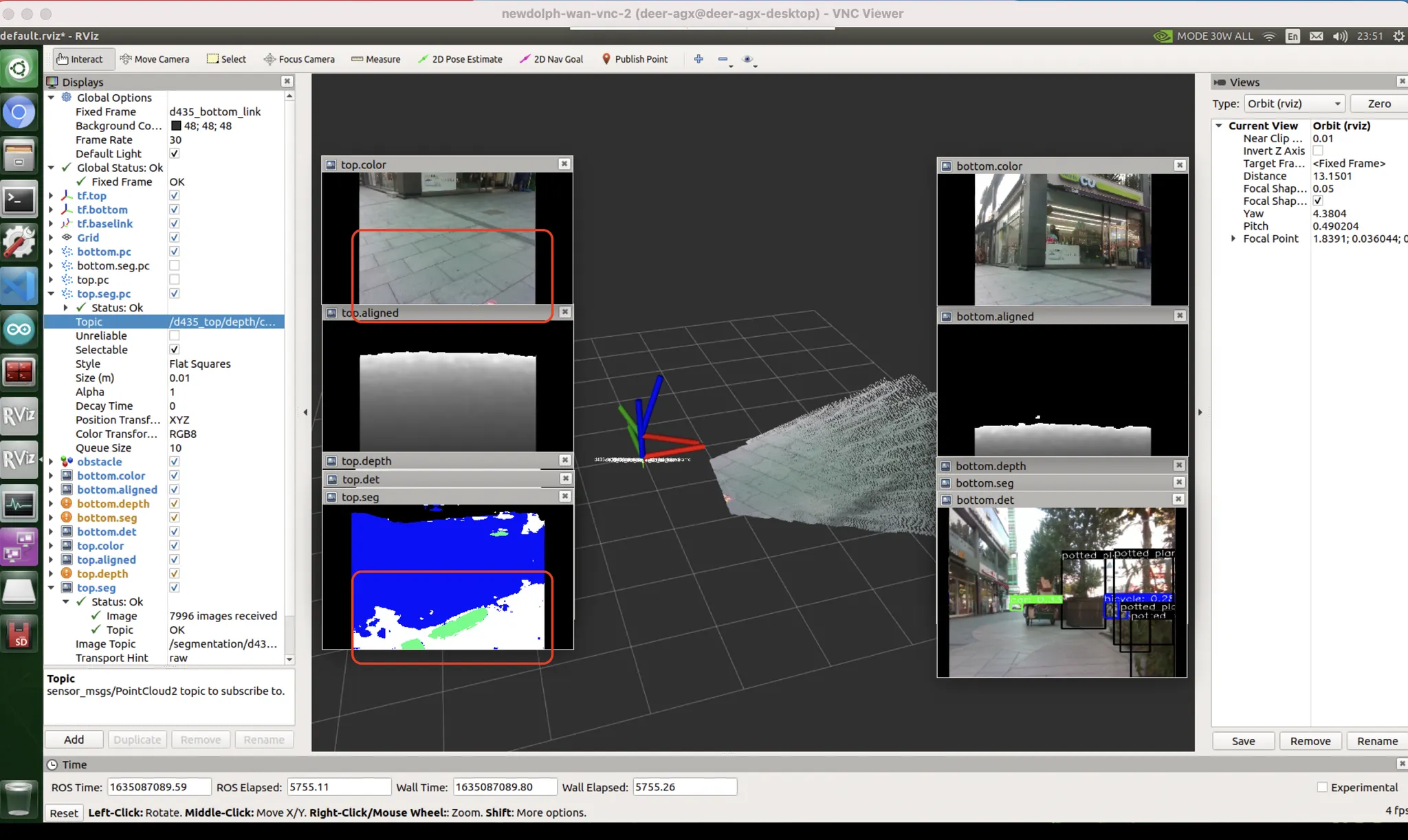
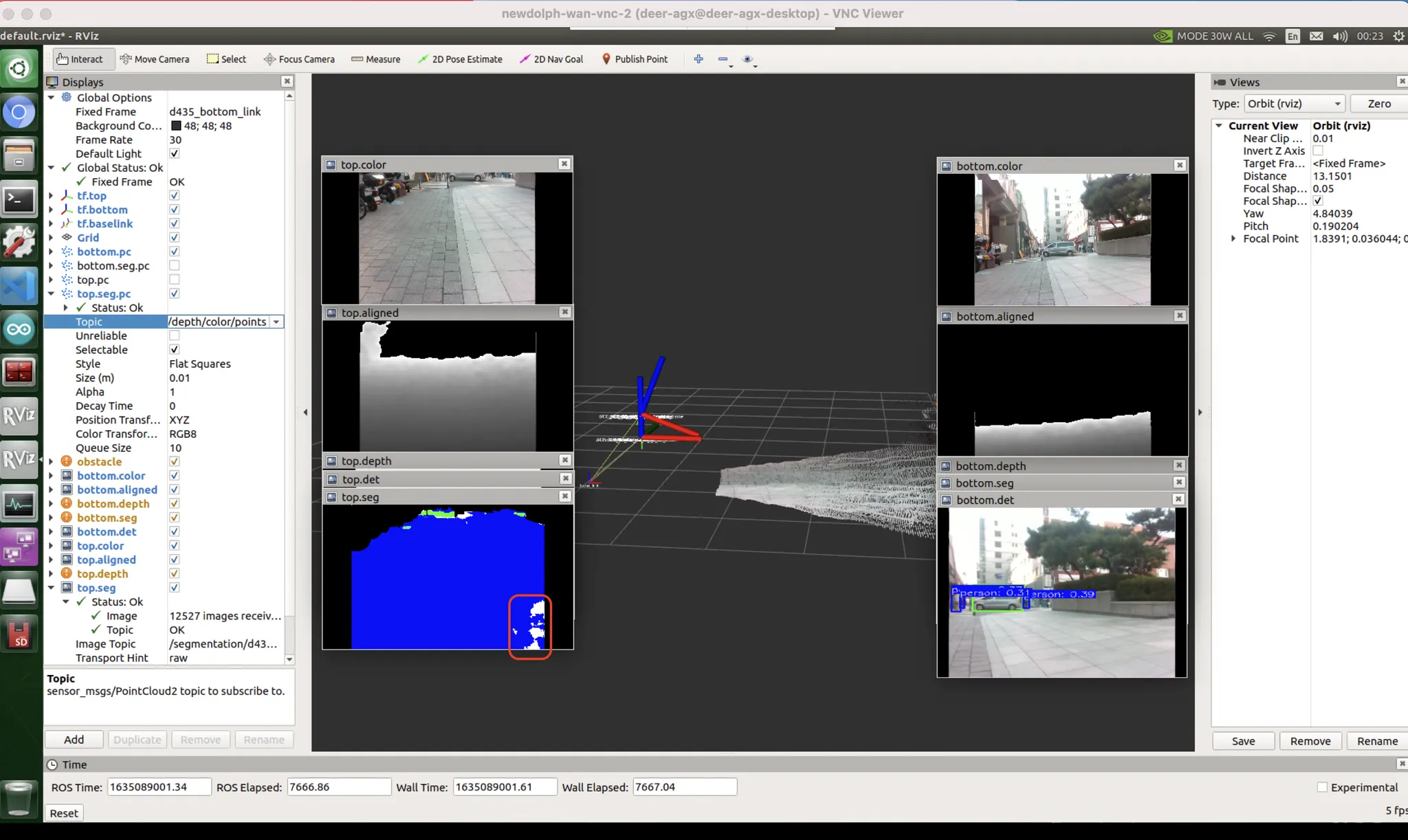
보지 못한 데이터(위상기하적, 카메라세팅, 노출값 등) 에 의한 편향 (domain gap)
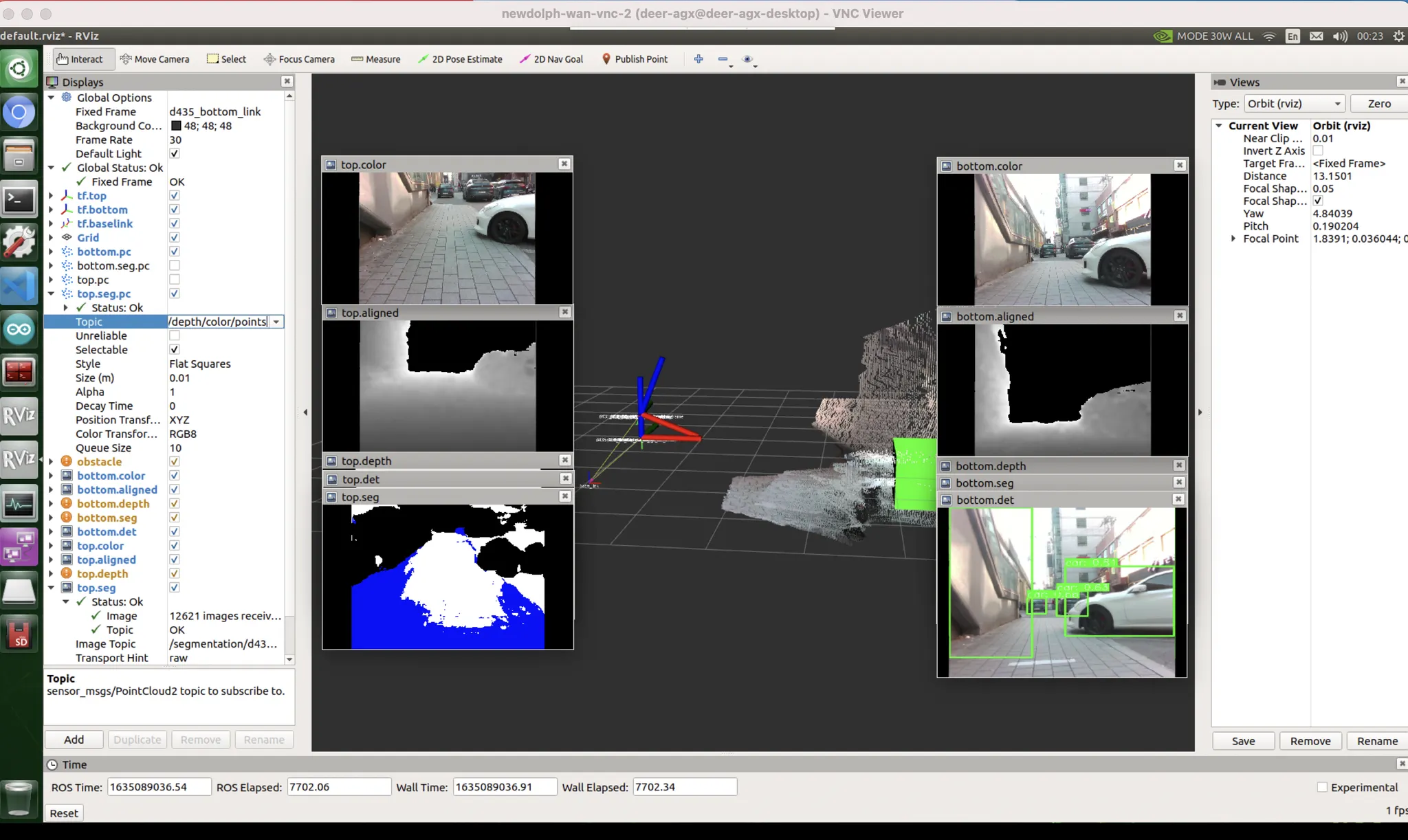
unseen data bias : 자전거를 본격적으로 본 적 없을거다. 또한 물체가 얇아 판별이 어렵다.
unseen data bias : 차량에도 마찬가지로 취약
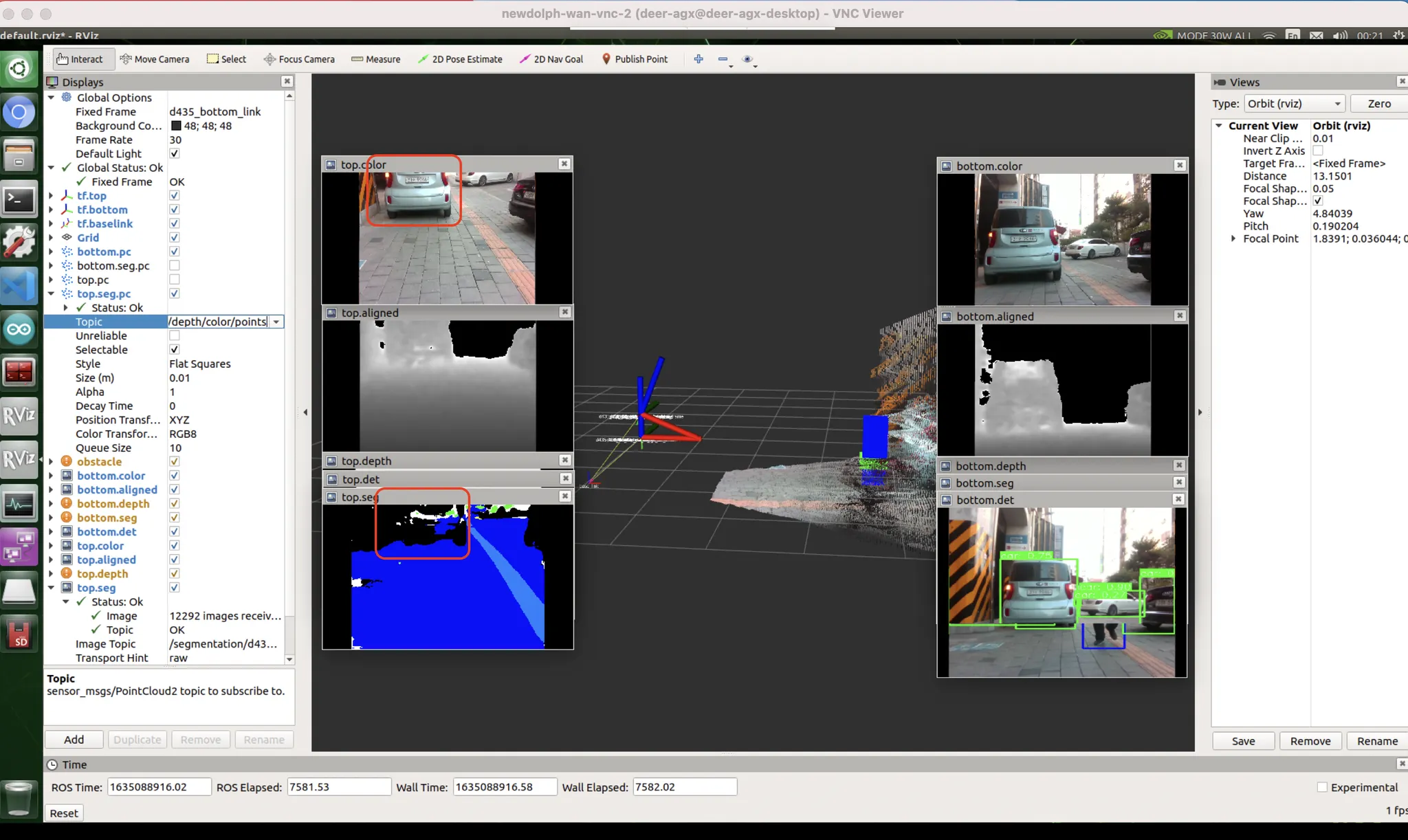
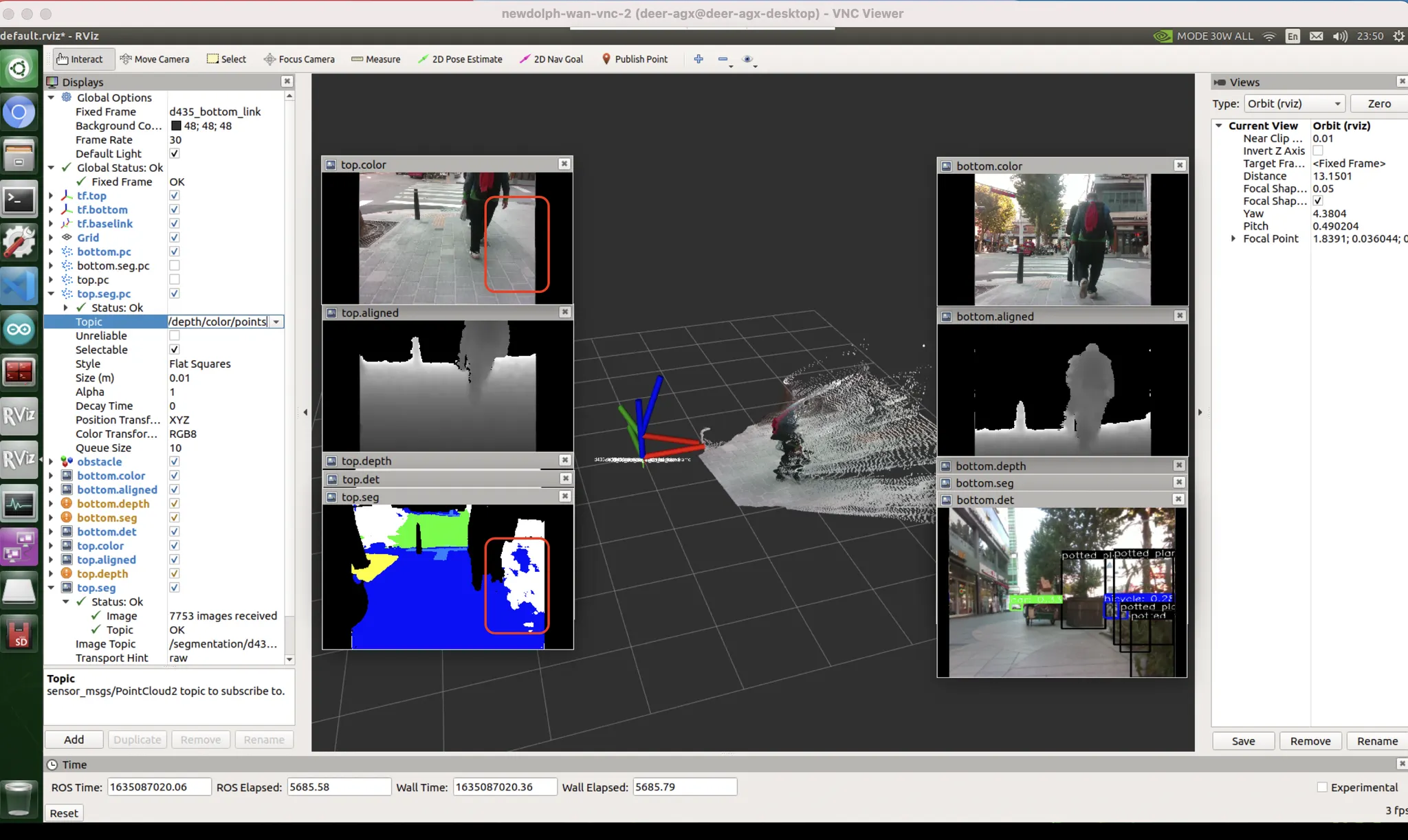
[우측 빨간박스] unseen data bias
[좌측 빨간박스] exposure bias : 카메라 노출값이 어두운 면에 맞추어지다 보니, 밝은 면에 대응하지 못했음. 하지만 데이터셋에는 그런 것이 없음. HDR 기술을 통해 보정 가능할거라고 생각하지만 한번도 써본 적 없고 꽤 느릴 것으로 예상.
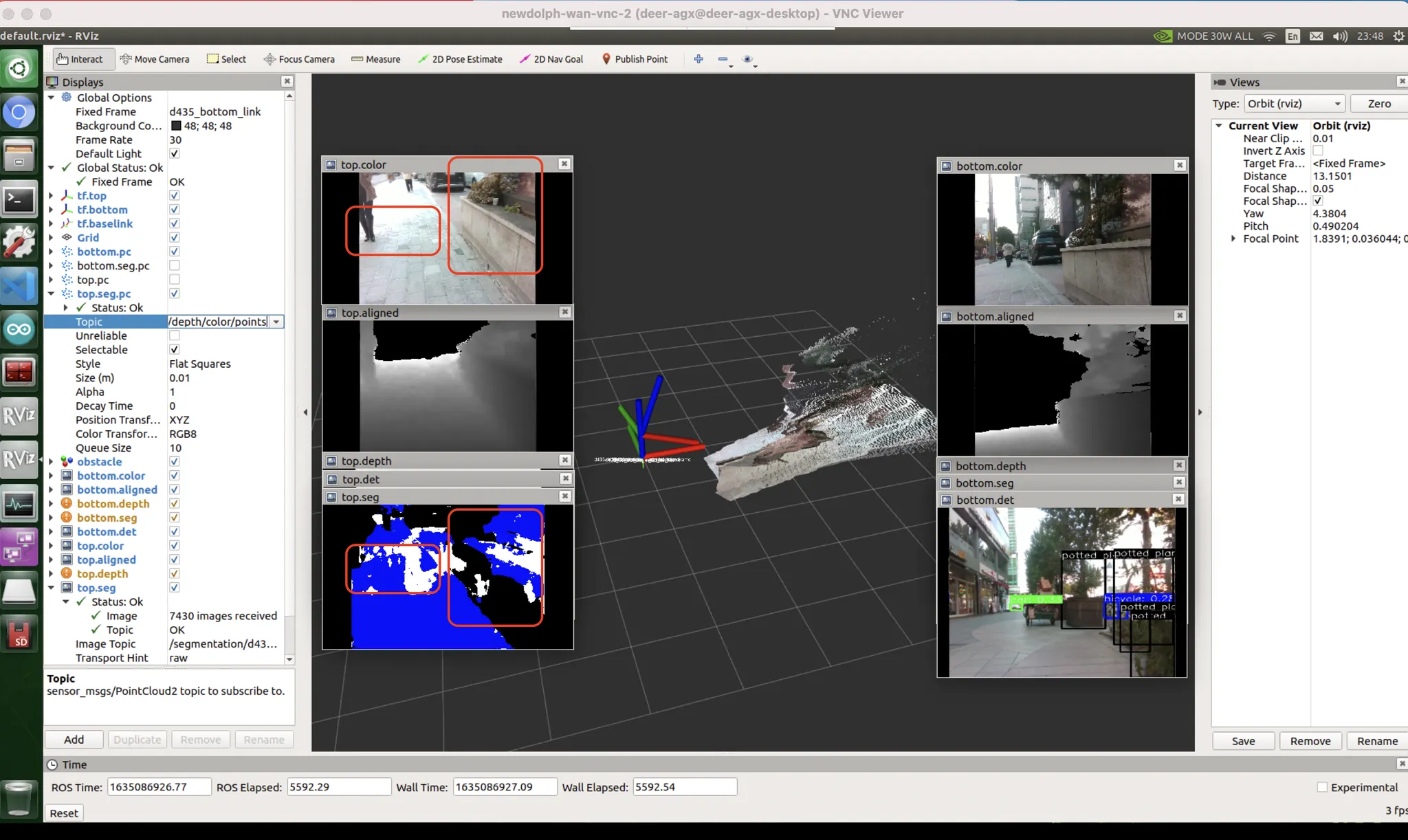
dataset & exposure bias : 내가 서있는 곳은 자전거도로고, 붉은 박스 영역이야말로 자동차도로임. 자동차도로를 no label (도로도, 자전거도로도, 인도도 아닌 그 무엇도 아닌 영역) 으로 인식함. 이런식으로 분류해버렸음.
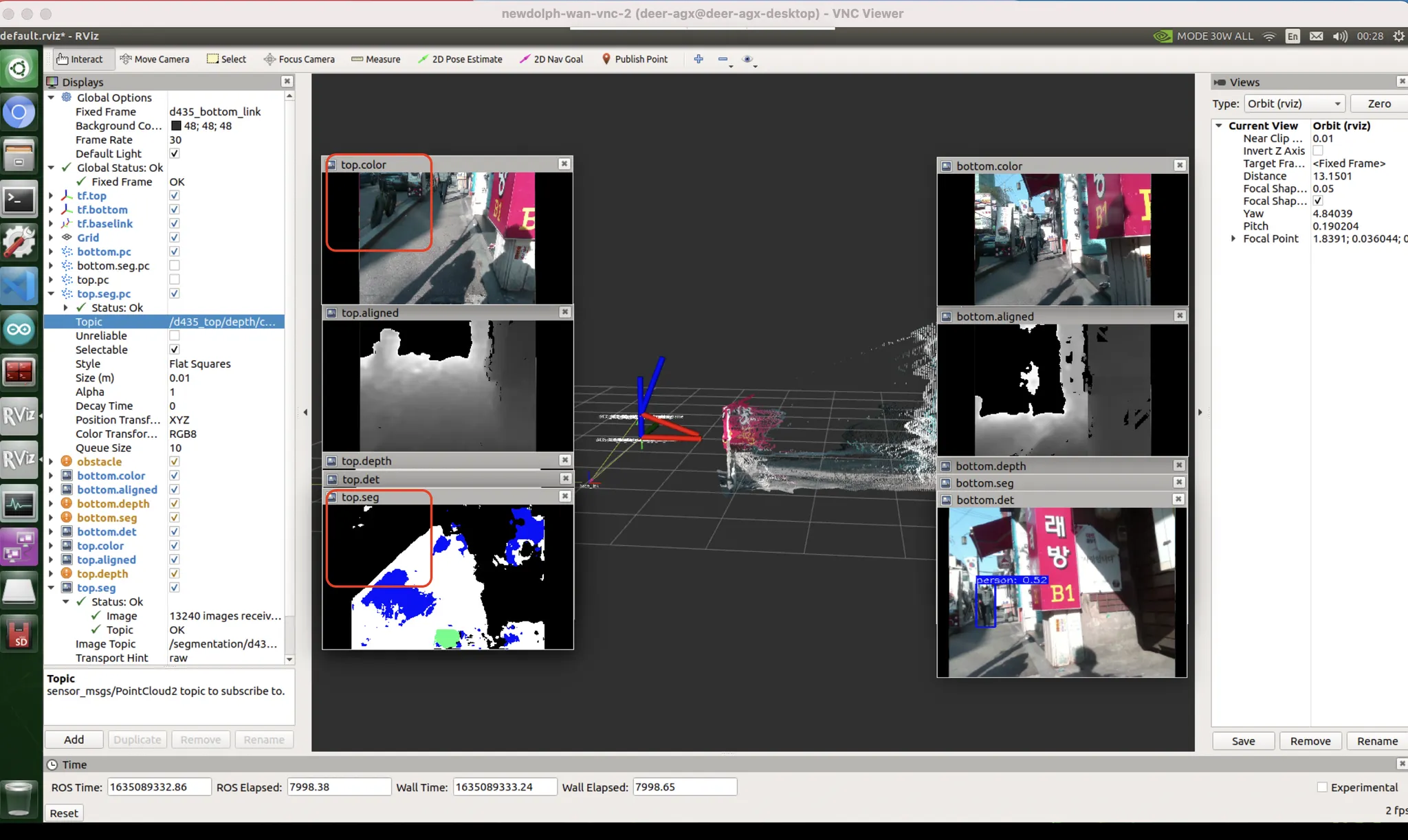
파란색 : 인도, 하얀색 : 차도, 검정색 : no lab
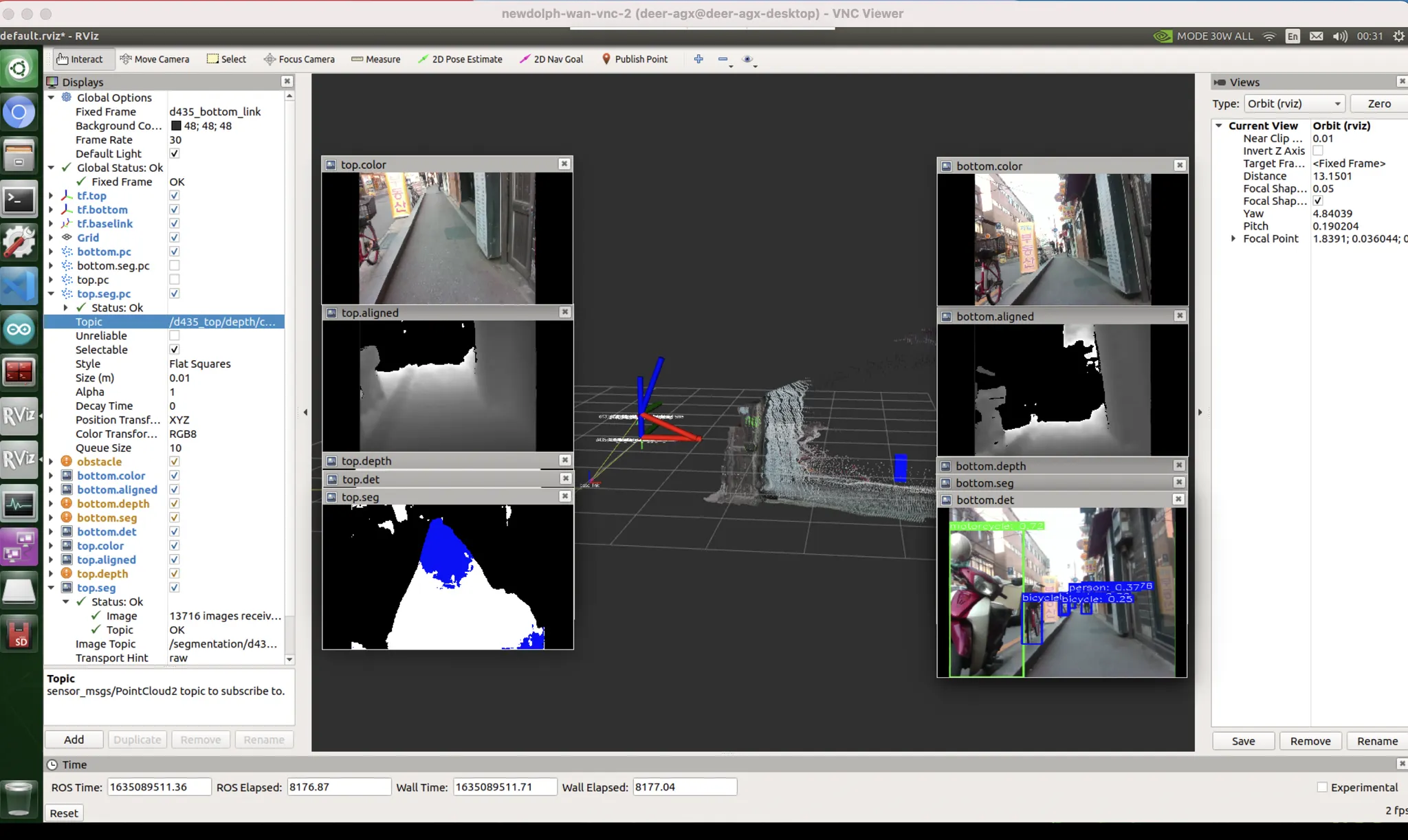
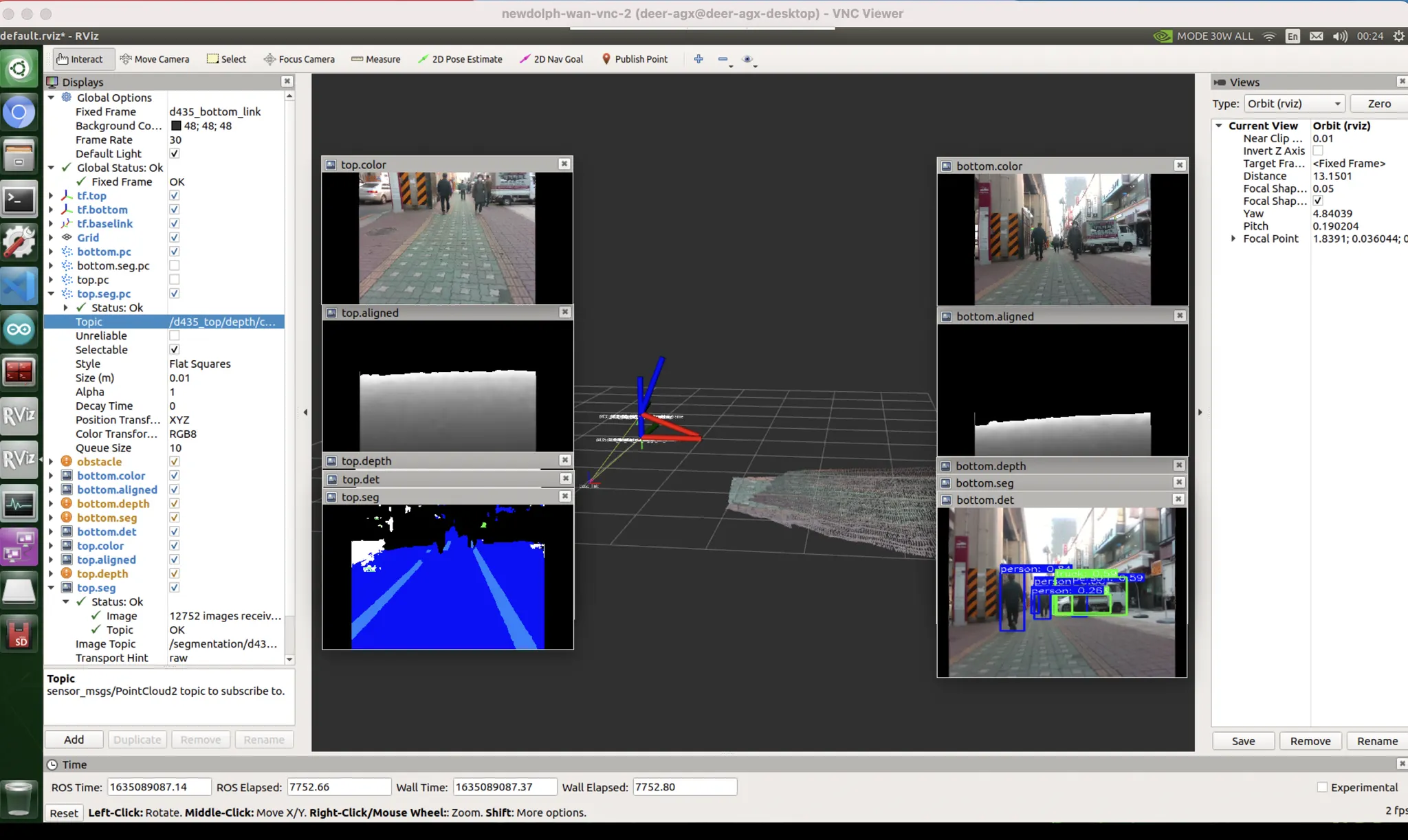
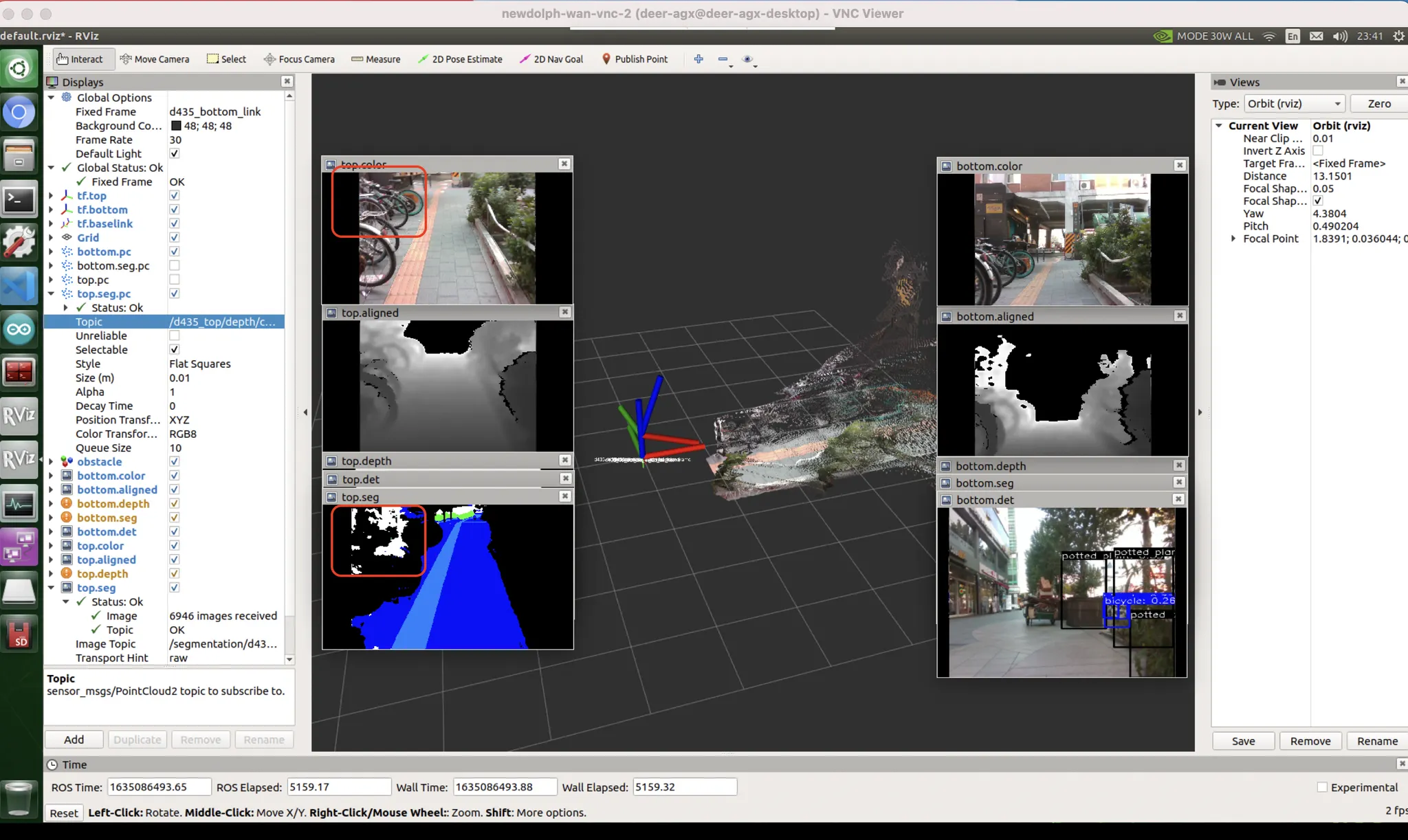
color and pattern bias
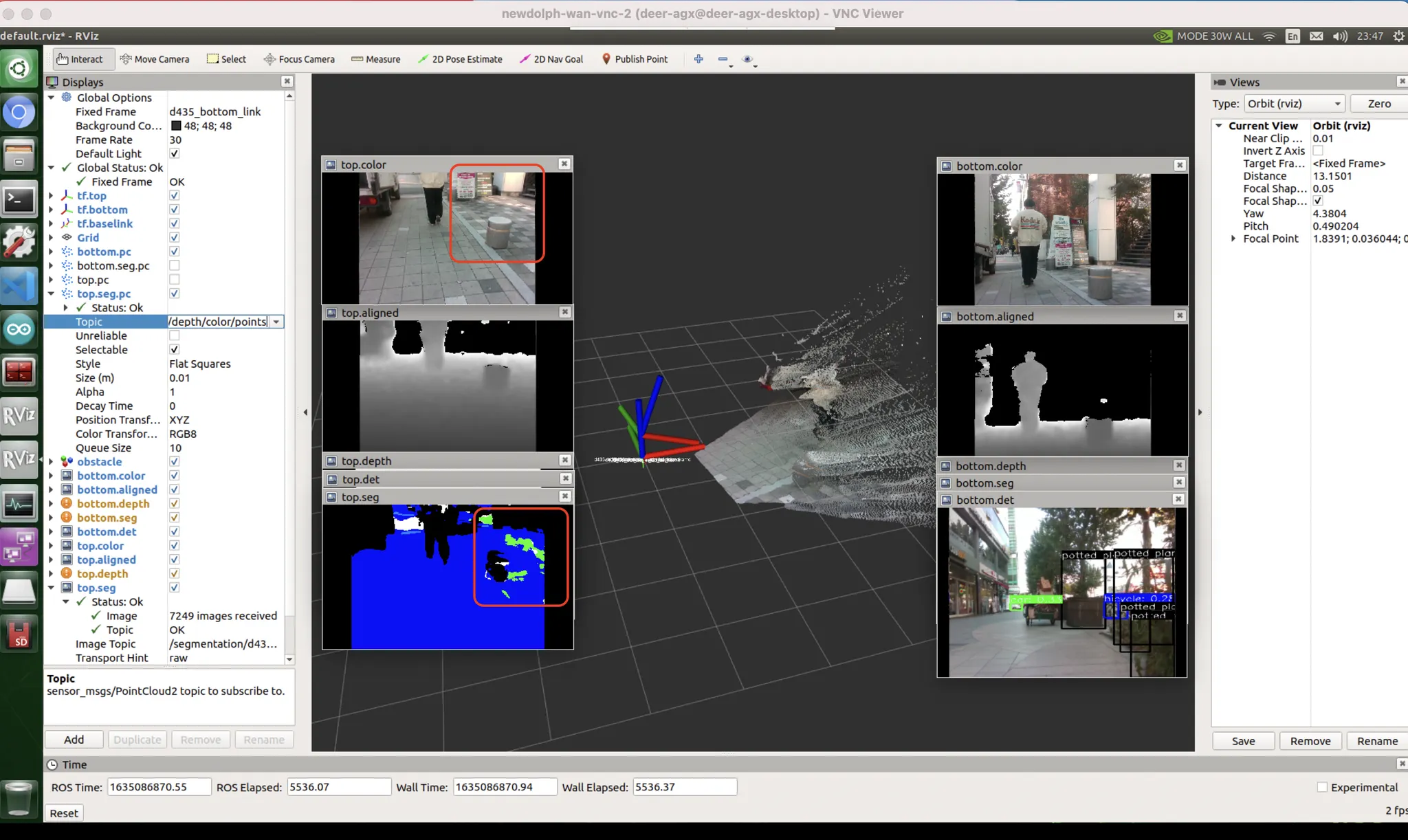

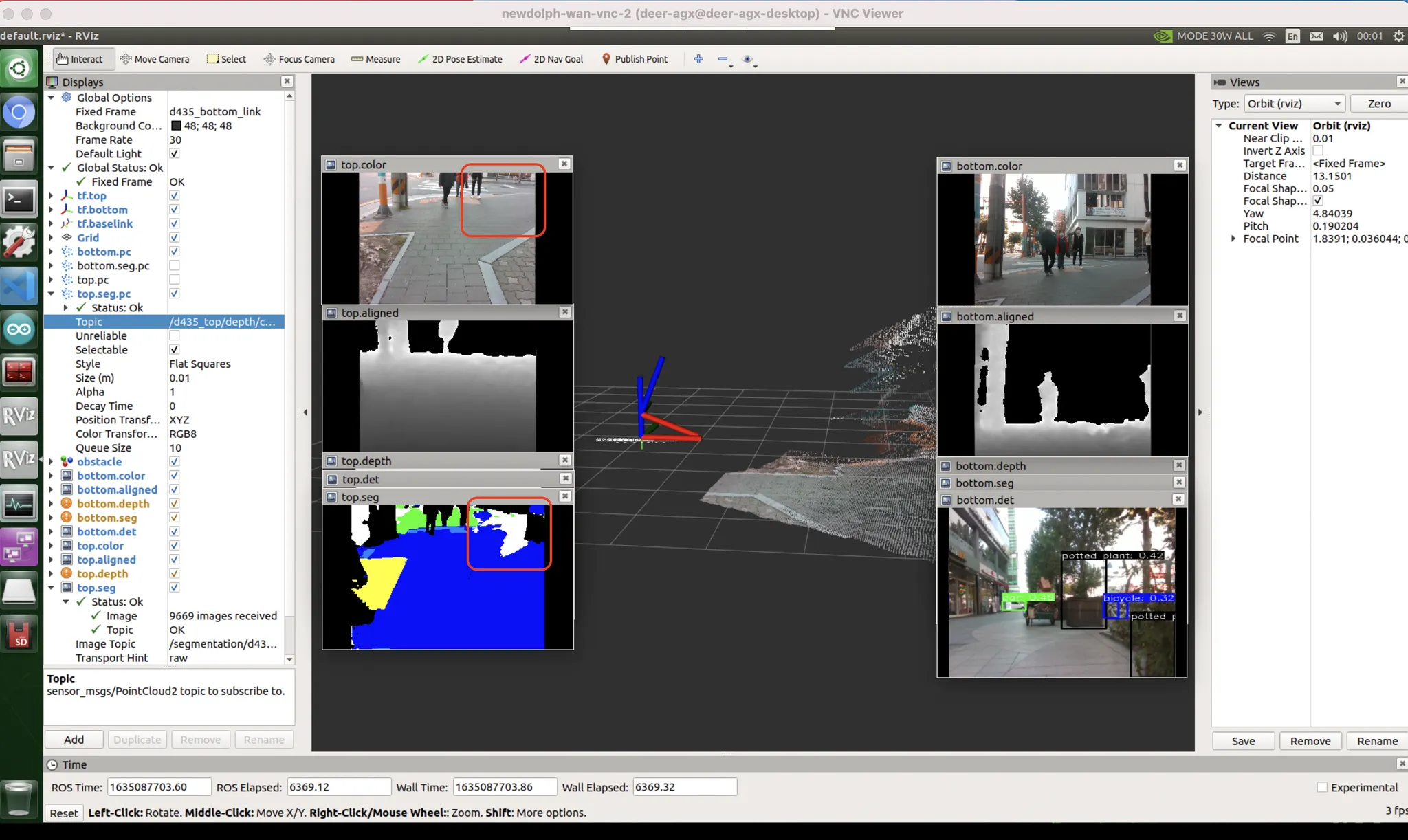
[좌측 빨간박스] video 로 보정 가능
[우측 빨간박스] unseen bias
data bias : 실제로 이렇게 있는 경우에 횡단보도가 어디서부터 시작되고 어디서 끝났는지 알 길이 없기때문에 이를 예측하는 것은 굉장히 어렵다. 이를 보완하려면 횡단보도는 경계부분만 따로 레이블링해서 line 을 예측하도록 만드는 것이 낫다. (물론 대각선형 횡단보도에서는 또 죽어버리겠지만.) 이정도로 튀지 않도록 하려면, 원본 데이터에서 횡단보도를 항상 조금 더 크게 썰어서 시야에 다 들어오지 않도록 데이터를 augmentation 시켜 학습시키는 것이 방법일 수 있다.
조금 안좋은 상황 : pattern & color bias
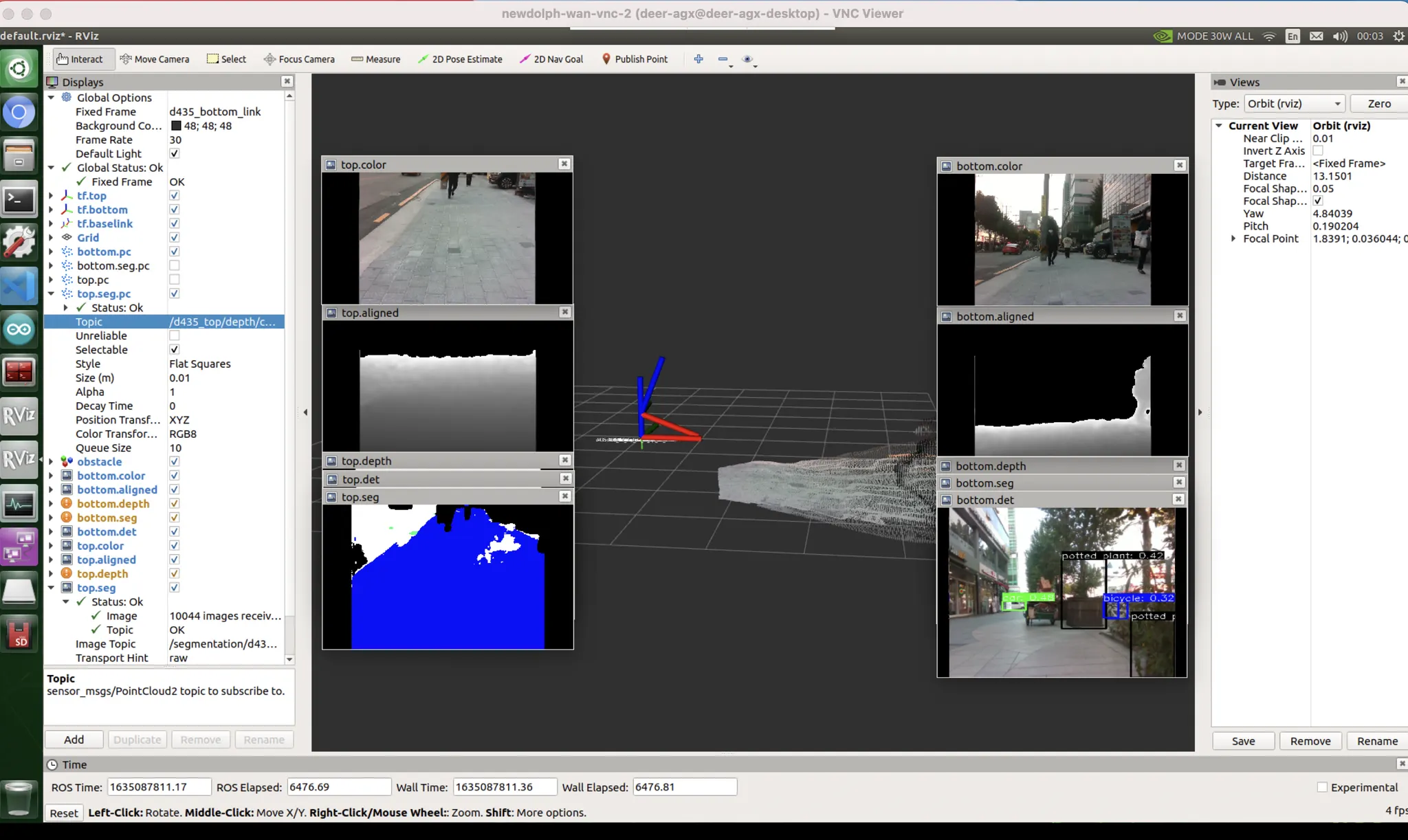
해상도의 부족
resolution 이 낮아서, 도로 연석의 특징을 제대로 포착하지 못하고 도로로 인식하는 영역이 더 넓어진 것은 아닐까 하는 의심을 해봅니다.
인사이트 : thresholding
임곗값을 다양하게 설정함으로써 '조금 불확실한 정보' 에 대해서 둔감해지도록 만들 수 있음.
파라미터 서버에 등록해놓고 동적으로 바꿀 수 있게 하면서 어떤 상태가 가장 optimal 인가 구경하면 재밌을듯
가장 린함
작은 노이즈
자글자글한 노이즈들. 이런 것들은 영상처리로 쳐버릴 수 있다. 하지만 이것을 쳤을 때 무슨 일이 연달아 일어날 지 모른다. 우리가 하는 웬만한 영상처리 연산은 딥 모델 스스로도 할 수 있는 연산이기 때문이다.



인사이트 : 이걸 개선하기보다는 맵 정보를 같이 참고하는게 더 좋지 않을까?
뭔가 맵과 합을 맞추고 싶어진다. 사람도 그렇지 않은가. 아 이쯤 뭔가 이제 인도가 막혔으니까 오른쪽으로 돌까..?