
우리는 보통 엣지 디바이스에 모델을 포팅할 때 성능만을 생각하는 경향이 있고, 나 또한 그랬던 경험이 있다. 모델 벤치마크 (성능 기록표) 를 보고, 더 높은 성능순으로 쭉 정렬한 뒤, 비슷한 성능의 GPU 에서 실험한 FPS 를 비교해 보고 충분히 빠른 것을 찾아보는 방식으로 이 모델을 엣지 디바이스에서 쓸 수 있을까를 판가름했다. 하지만 타겟 디바이스가 일반적인 데스크탑 GPU 가 아니라 엣지 디바이스라는 전제가 붙는다면 간단하게 해결되는 문제만은 아니라는 사실을 배우게 됐다.
이번 글에서 강조하고 싶은 것은 <벤치마크상 더 빠른 것> 이 반드시 <최적화 후에도 더 빠른 것> 이라고 할 수 없다는 점이다. 이 현상은 굉장히 빈번히 일어난다. 엣지 디바이스에서 돌리기 위해서는, 일반적으로 최적화 과정을 거친다. TensorRT 나 tflite 등의 프레임워크는 다양한 최적화를 도와주기도 하지만, 이러한 프레임워크에 온전히 의존하기 어려운 경우가 정말 많다. 실제로 이기종 엣지 디바이스에서 최적화 방식과 양자화방식이 다른 문제를 challenges 라고 표현하기도 할 만큼 어려운 문제이다 (참고3). 세상에는 제각각의 목적에 맞게 설계된 정말 많은 프로세서들이 있는데, 이들 모두가 최적화된 연산이라고 할 수 있는 부분이 다르다는 것이다. 게다가 세상에는 수많은 모델이 존재한다. 어떤 모델의 경우에는 너무 복잡한 연산이 들어가서 최적화 자체에 어려움을 만들기도 한다 (참고6:XLA). 어떤 모델이든지 어떤 디바이스에서든 빠르게 실행시킬 수 있도록 만든다는 것은 식당에서 어떤 손님이 오든 모두가 만족할 수 있도록 모두의 입맛에 맞는 밑반찬을 모두 준비한다는 것과 같은 꼴이기 때문이다.
최근까지 SOTA 를 달렸던 Backbone 모델인 EfficientNet 의 경우를 보자. 이름부터 "효율적인 네트워크" 인데다 성능도 좋아서 많은 후속 연구 모델들이 EfficientNet backbone 을 채택했고, 다양한 태스크에 쓸 수 있는 EfficientNet 기반 모델이 오픈소스로 공개되어 있다. 이들 모델을 tflite (TensorFlow Lite) 나 tensorRT 같은 최적화 도구로 최적화시켜서 엣지디바이스에 탑재할 수 있지 않을까? 하는 생각은 누구나 할 수 있다. 그런데 이렇게 효율적이고 성능 좋은 efficientnet 을 tflite 로 양자화하면 모델 크기 면에서는 이익을 얻지만 속도 면에서는 오히려 큰 손해를 본다 (참고4의 표).
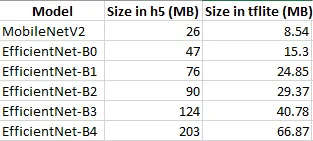
사이즈
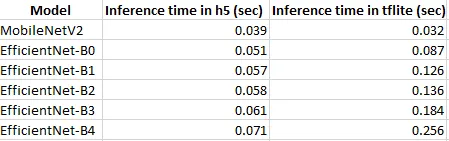
추론속도
당연히 모델을 작고 빠르게 만들어주는 도구여야 하는 tflite 를 썼더니 모델이 되려 더 느려질 수 있다는 사실은 꽤 충격적이다. 이런 현상이 나타나는 이유는 tflite 라는 프레임워크에서 지원하지 않는 squeeze-excitation 같은 연산(ops) 이 efficientnet 에 포함되어 있기 때문 (참고4) 이다.
만약 우리의 팀에 엔지니어링 리소스가 많고, 더 높은 정확도가 절실히 요구된다면 프레임워크에서 지원하지 않는 것을 추가로 구현하기 위해 (참고1: 를 참고하자.) 더 복잡한 도구와 더 많은 시간을 써서 조금 더 좋은 모델을 탑재할 수 있을 것이다.
하지만 학교 프로젝트이거나, 스타트업에서 무엇인가를 프로토타이핑해야 한다면 이미 만들어진 모델을 사용하는 것 (참고2:) 가 더 좋을지도 모른다. 일례로 구글 연구진은 efficientnet 의 위와 같이 오히려 속도면에서 손해를 보는 문제를 해결하기 위해, 내부 연산을 수정한 모델인 efficientnet lite 을 오픈소스로 공개했다.
이와 같은 이유로 만약 우리가 edge tpu 같이 tflite 기반의 모델을 올려야 하는 엣지 디바이스를 사용한다고 해 보자. 이 경우에는 구글 연구진이 미리 엔지니어링을 해 둔 EfficientNet Lite 같은 모델이 훨씬 더 좋은 선택지일 수 있다는 이야기가 된다. 현재 기준 성능이 가장 좋거나 가장 빠르다고 해서, sota model 이라고 해서 무작정 선택하면 안되는 이유가 바로 이것이다. 만약 나의 엣지 디바이스가 Jetson 이기 때문에, tensorRT 를 사용해야 하는데 tensorrt 에서 efficientnet 에서 지원하는 연산을 tflite 처럼 지원하지 않는다면 위에서 언급했던 것과 비슷한 손해를 볼 수 있는 것이다.
참고
1.
2.
5.