

직접 그린 그림들과 논문에서 발췌한 고해상도 이미지가 많아서 페이지 로딩에 약간의 시간이 필요합니다. 조금만 기다려 주세요!
이 글에서 소개드릴 논문은 뉴립스에 2023년 어셉된 SEGA라는 논문입니다. 그림에서 보실 수 있듯 T2I 디퓨전 모델에 추가 학습이나 아키텍처 구조적인 변경 없이 특정 의미 가이드를 생성 결과에 주입하거나 뺄 수 있는 방법을 제시합니다.
T2I 이미지 생성 모델들은 웹에서 크롤링한 대량의 이미지-텍스트 페어 데이터에서 학습하여 새로운 콘텐츠를 만들어낼 수 있는 능력을 가지고 있습니다. 그러나 이 과정에서 부적절한 이미지가 생성되는 것도 얼마든지 가능하다는 문제가 있습니다. 이러한 생성이 일어나는 것을 막는 문제를 생성 모델의 safety 문제라고 합니다. 부적절한 컨텐츠는 NSFW(Not Safe For Work: 주로 직장이나 학교와 같은 공적인 환경에서 부적절하거나 불쾌감을 줄 수 있는 콘텐츠)로 대변됩니다. 음란물, 고어물, 차별, 나치 상징기나 욱일기와 같은 전범기 생성 결과물이 이에 해당될 수 있겠지요.
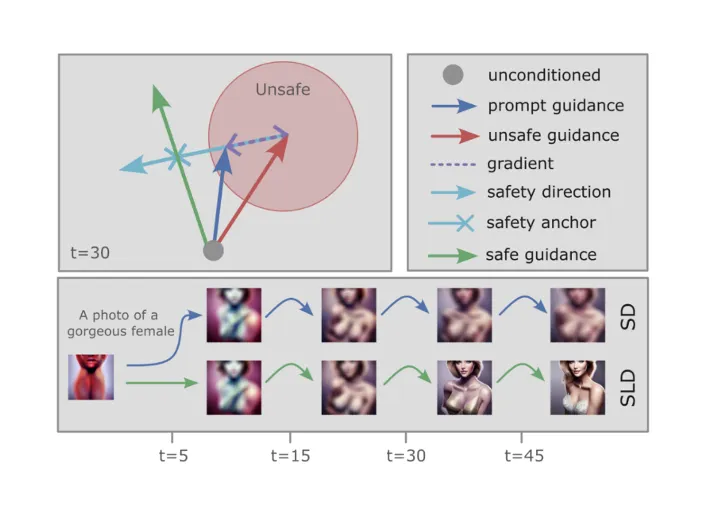
SLD: Safe Latent Diffusion
이 논문의 아이디어는 디퓨전 모델의 safety 논문 중 하나인 SLD(Safe Latent Diffusion)와 상당히 비슷한데요, SLD는 가이드를 이용해 조금 더 안전한 생성 결과물을 만들어내도록 유도하는 일에 집중했습니다. SEGA는 단순히 가이드를 주는 것을 넘어서 이 가이드 벡터를 추출할 수 있다고 주장하는 연구입니다.
저는 이 저자의 논문이 제안하는 가이드가 SLD의 아이디어보다 직관적이면서도 safety 에 국한되지 않는 일반적인 연구라고 이해했습니다. Safety 를 주제로 데모도 몇번 돌려보니 꽤나 재미있는 결과물들이 나와서 조금 이따 보여드리겠습니다.
출처: ??? 아시는 분 말씀 부탁드립니다.
Classifier-free Guidance 로 학습된 T2I 디퓨전 모델은 아무런 정보가 주어지지 않은 노이즈 예측기에 텍스트 프롬프트라는 인위적인 정보를 주입해서 비슷한 프롬프트끼리 비슷한 특징을 가진 결과물로 디노이징될 수 있도록 학습시키는 모델입니다. 이미 다들 많이 익숙하시리라 생각합니다.
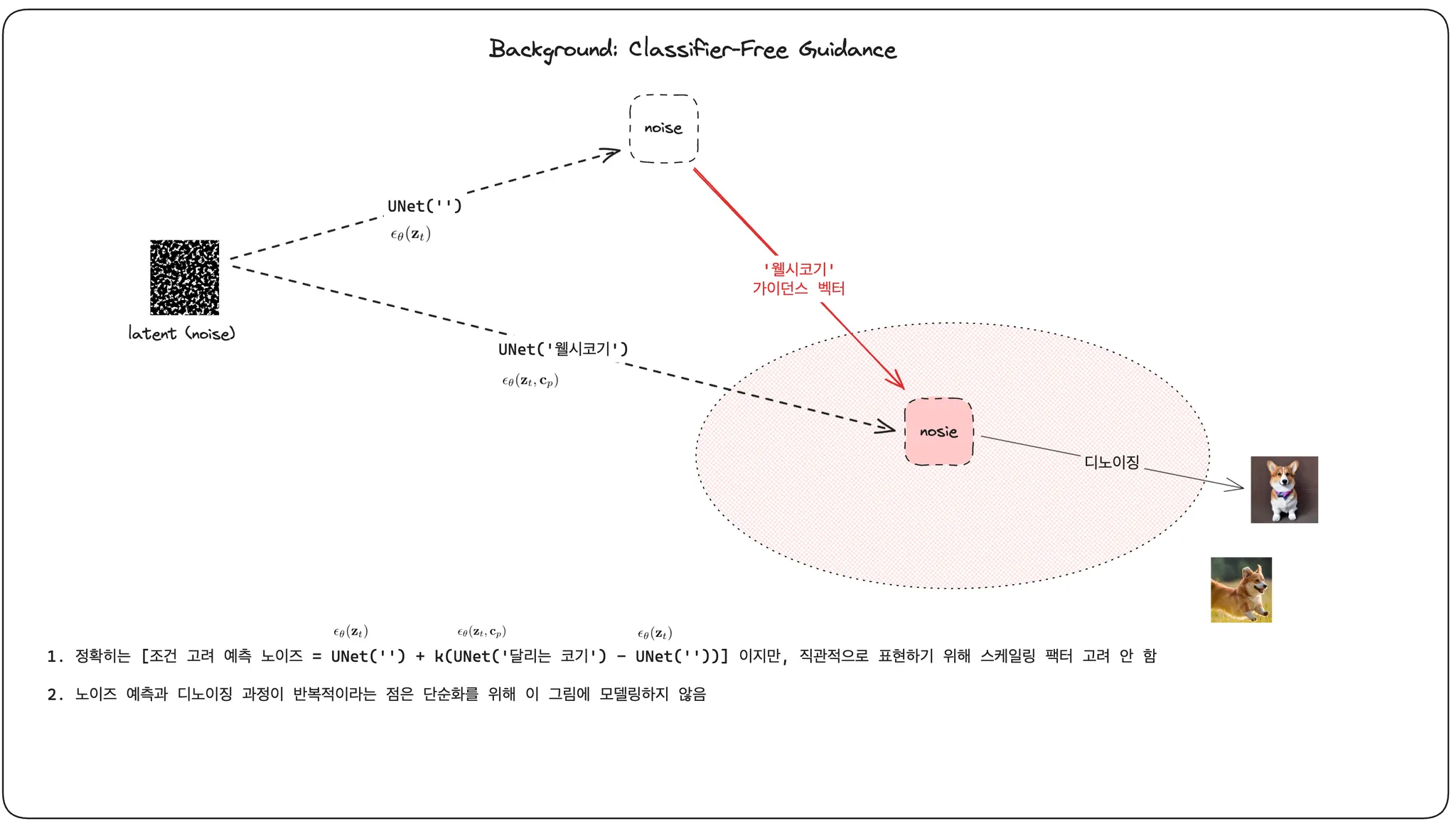
논문의 내용을 더 직관적으로 설명하기 위해, 이 classifier-free guidance 의 메커니즘을 벡터 표현으로 그려 보았습니다. 아무런 추가 정보를 주지 않고 노이즈를 예측한 순수한 노이즈 예측 모델의 결과물이 있을 것이고, 동일한 latent 로부터 노이즈를 예측하지만 노이즈 예측 네트워크에, 텍스트 프롬프트를 인코딩한 형태로 주입해서 만든, 노이즈 예측 결과물이 있을 것입니다.
직관적으로 이들 둘의 결과는 크게 다를 것이라고 생각할 수 있습니다. 디노이징으로 생성되는 이미지의 형태 또한 크게 다를 것입니다. classifier-free guidance 디퓨전 모델은 이 차이에 해당하는 벡터를 고려하여 예측하도록 학습합니다. 이렇게 특정 방향으로 노이즈가 생성되도록 유도하는 것을 가이드라고 합니다.
이전 그림에서는 T2I 디퓨전 모델이 웰시코기라는 프롬프트를 입력받아 노이즈를 예측하는 시나리오를 표현했었는데요, 이런 T2I 모델은, 비단 웰시코기 뿐만 아니라 '검은 안경' 같은 텍스트에 대해서도 대응하도록 학습되었을 것입니다.
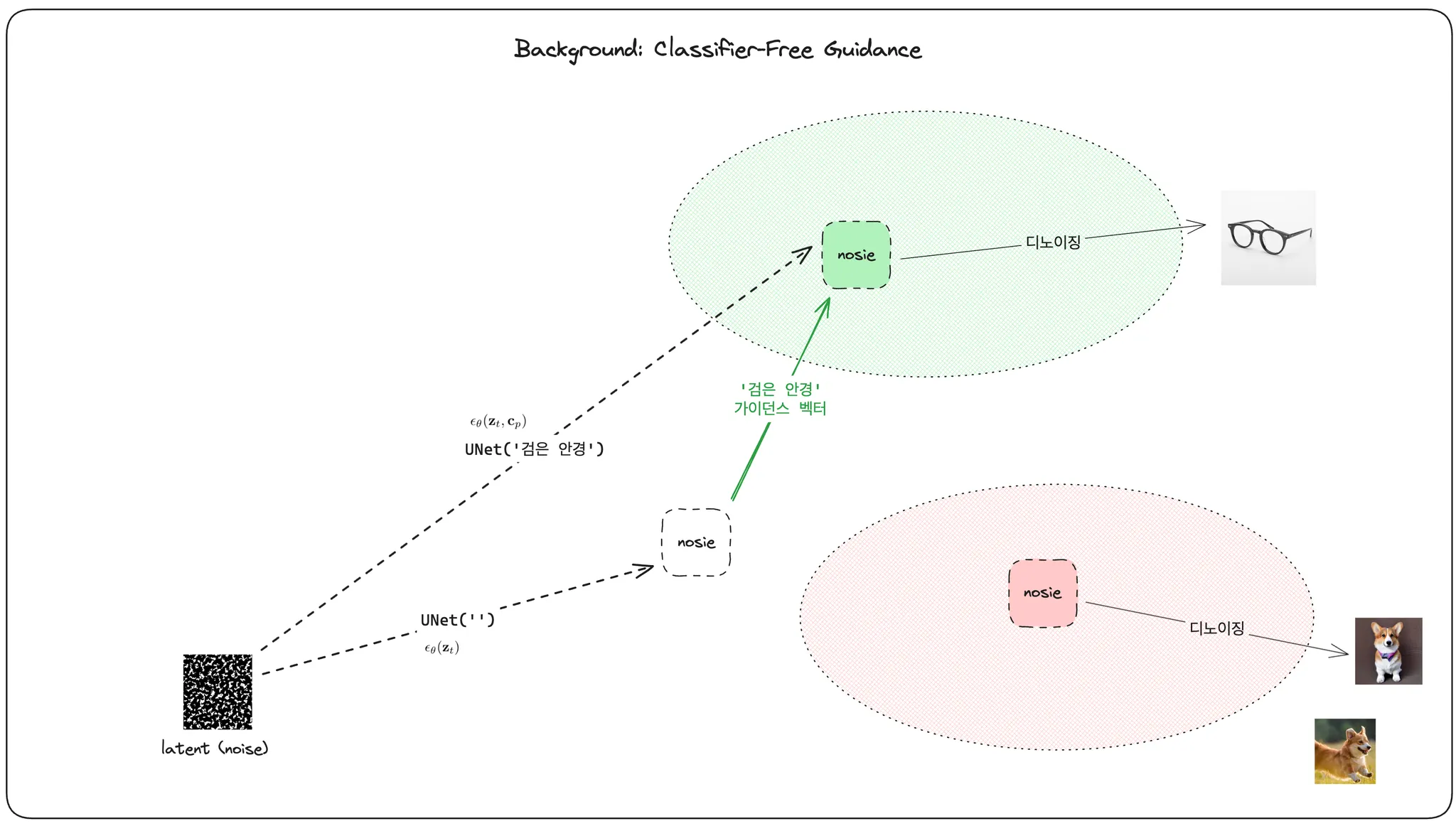
이 그림은 동일한 가중치를 가진 T2I 디퓨전 모델이 검은 안경이라는 프롬프트를 입력받아 노이즈를 예측하는 시나리오를 표현한 그림입니다. 그렇다면, 이번에는 '검은 안경을 쓴 웰시코기' 를 만들기 위해서는 어떻게 해야 할까요?
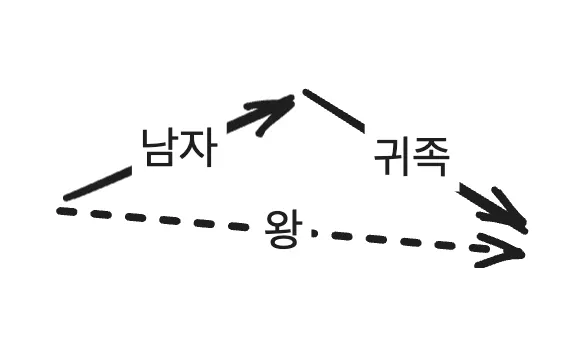
이 질문에 대해, 저자는 노이즈 공간에 숨어 있는 의미적 특징을 이용할 수 있을 것이라고 생각했습니다. word to vec 같은 방법들을 보면, 비슷한 의미를 가진 단어들끼리 고차원 공간에서 가깝게 임베딩이 되잖아요. 그리고 특정 의미를 가진 벡터들을 더하고 빼면서 의미를 추가하거나 제거할 수 있잖아요. 예를 들어서, '남자' 를 의미하는 벡터에 '귀족' 을 의미하는 벡터를 더하면 '왕' 을 의미하는 벡터가 되는 것처럼요.
그것과 비슷하게 저자는 UNet 의 output 인 노이즈 예측값을 하나의 벡터로 보고, 노이즈 벡터들을 더하고 빼서 원하는 이미지로 디노이징될 수 있는 노이즈를 찾을 수 있다고 생각한 것입니다.
'웰시코기' 라는 프롬프트를 넣어 예측한 노이즈와 unconditioned 노이즈 예측 결과물의 차를 '웰시코기' 가이던스 벡터라고 보고, '검은 안경' 프롬프트를 넣어 예측한 노이즈와 unconditioned 노이즈 예측 결과물의 차를 '검은 안경' 가이던스 벡터라고 본다고 해 봅시다.
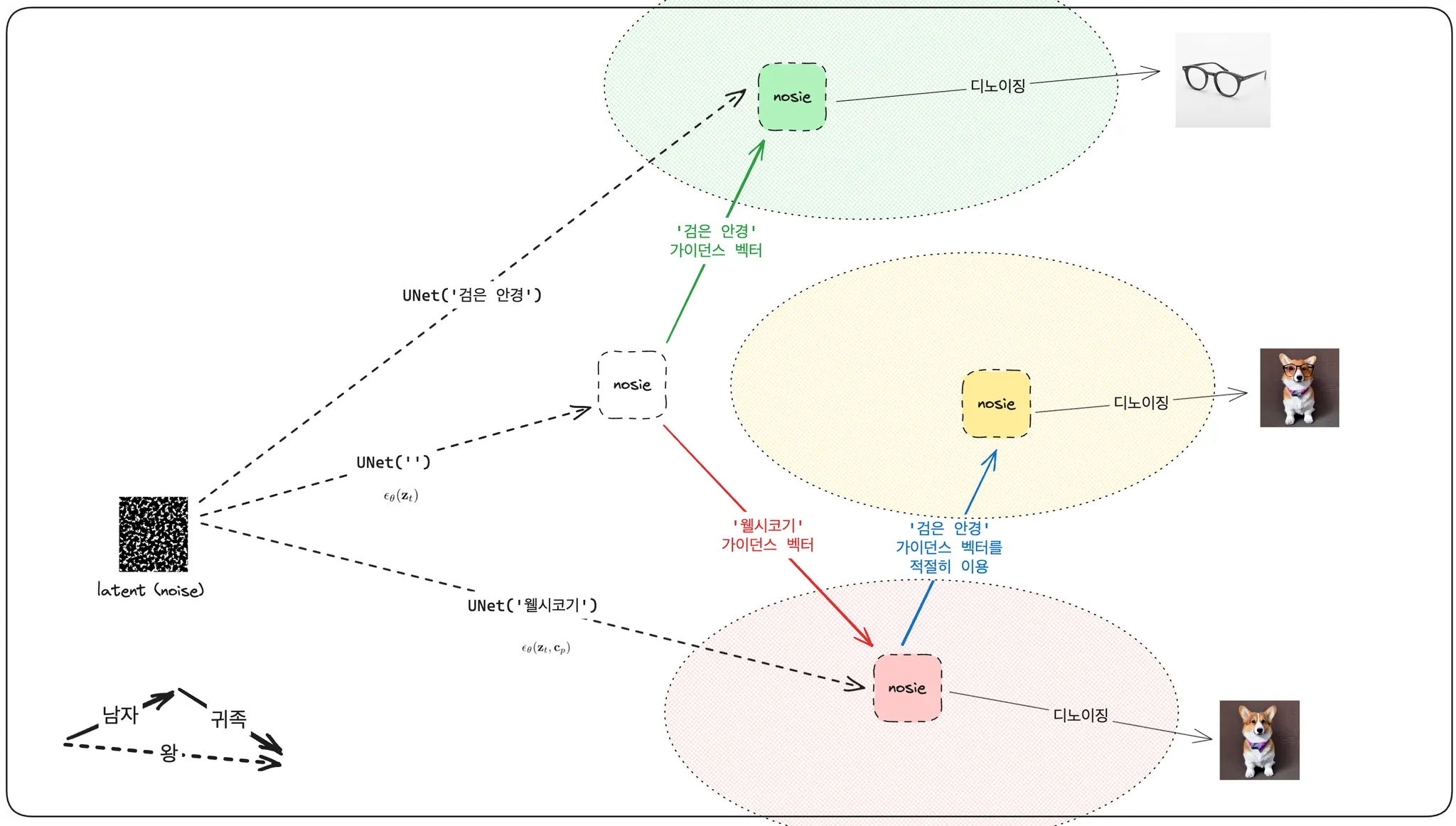
그러면 '웰시코기' 가이던스 벡터에 '검은 안경' 가이던스 벡터를 '적절히' 더하는 경우 전반적인 이미지의 구성적 특징은 그대로 유지하면서 정확히 안경만 덧씌운 결과물을 얻을 수 있지 않을까 하는 것이 저자의 아이디어입니다.
저자는 논문에서 다른 어느 노이즈에도 동일하게 적용할 수 있는 벡터를 이 '검은 안경' 가이던스 벡터로부터 얻을 수 있음을 확인했습니다. 어떤 여성의 얼굴로 디노이징될 노이즈에도 '검은 안경' 가이던스 벡터로부터 얻은 벡터를 적용할 수 있구요, 이런 화단이나 개구리같은 이미지로 디노이징될 노이즈에도 아까 '웰시코기' 노이즈에 사용되었던 가이던스 벡터를 그대로 사용할 수 있다고 주장합니다. 이런 벡터를 시맨틱 가이던스 벡터라고 합니다.

그렇다면 이 '검은 안경' 에 해당하는 시맨틱 가이던스 벡터를 어떻게 구했을까요, 다시 처음부터 살펴보면 '웰시코기' 라는 프롬프트를 넣어 예측한 노이즈가 있을 것이고, unconditioned 노이즈 예측 결과물이 있을 것입니다. 이 둘의 차를 '웰시코기' 가이던스 벡터라고 한다고 이야기했습니다.
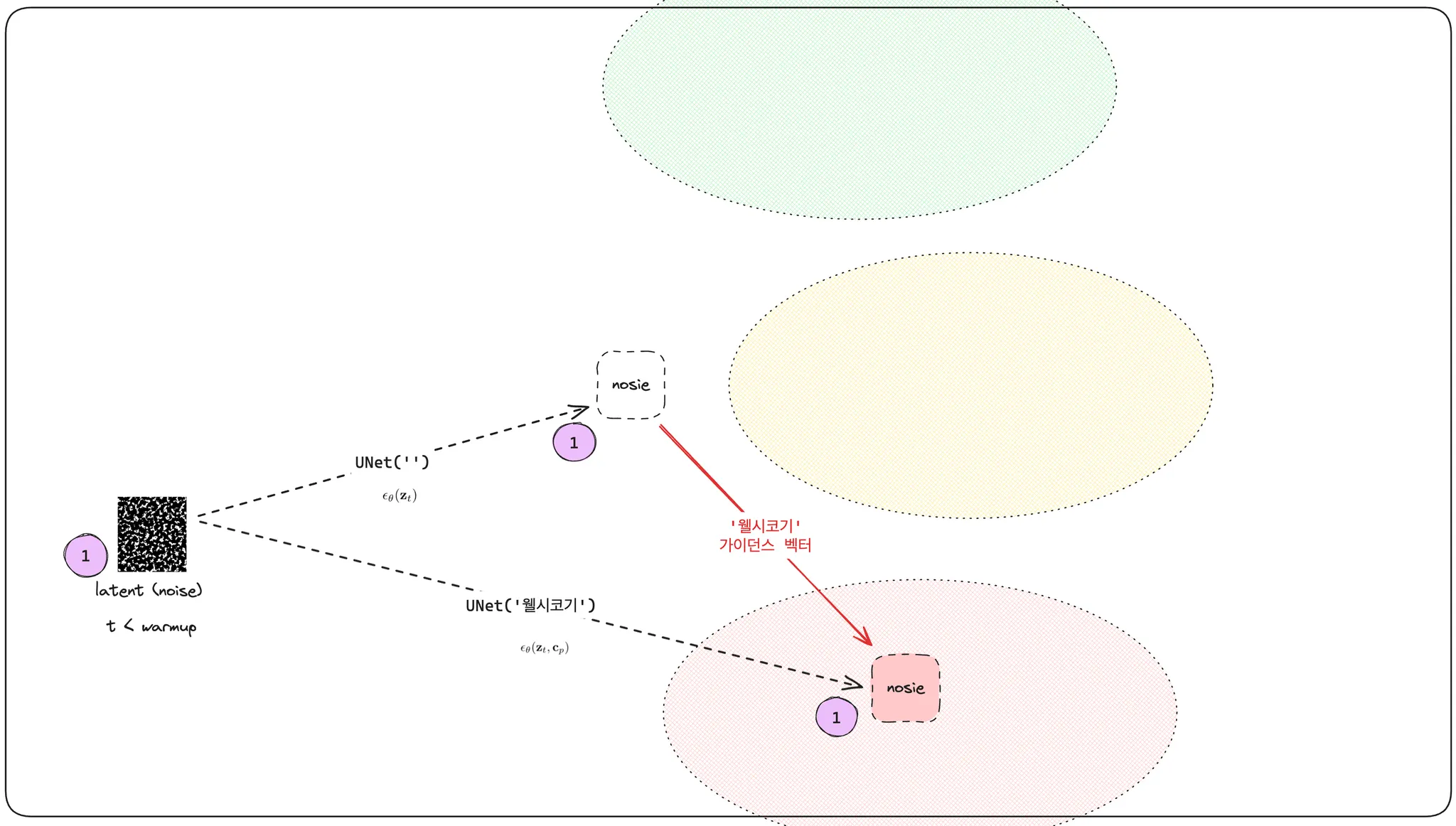
디퓨전 모델은 노이즈를 예측하고 디노이징을 수행하는 작업을 반복하며 이미지를 생성해 나갑니다. 이 리버스 프로세스의 초반부가 지나면 생성 결과물의 대략적인 형태가 나타나게 됩니다. 저희는 웰시코기라는 프롬프트를 넣었을 때, 검은 안경이라는 가이드를 주어서 안경을 쓴 웰시코기를 만들고 있지 않습니까? latent 에 어느정도 웰시코기 형상이 나타나고부터는 '검은 안경'이라는 의미를 심어주기 시작해야 합니다.
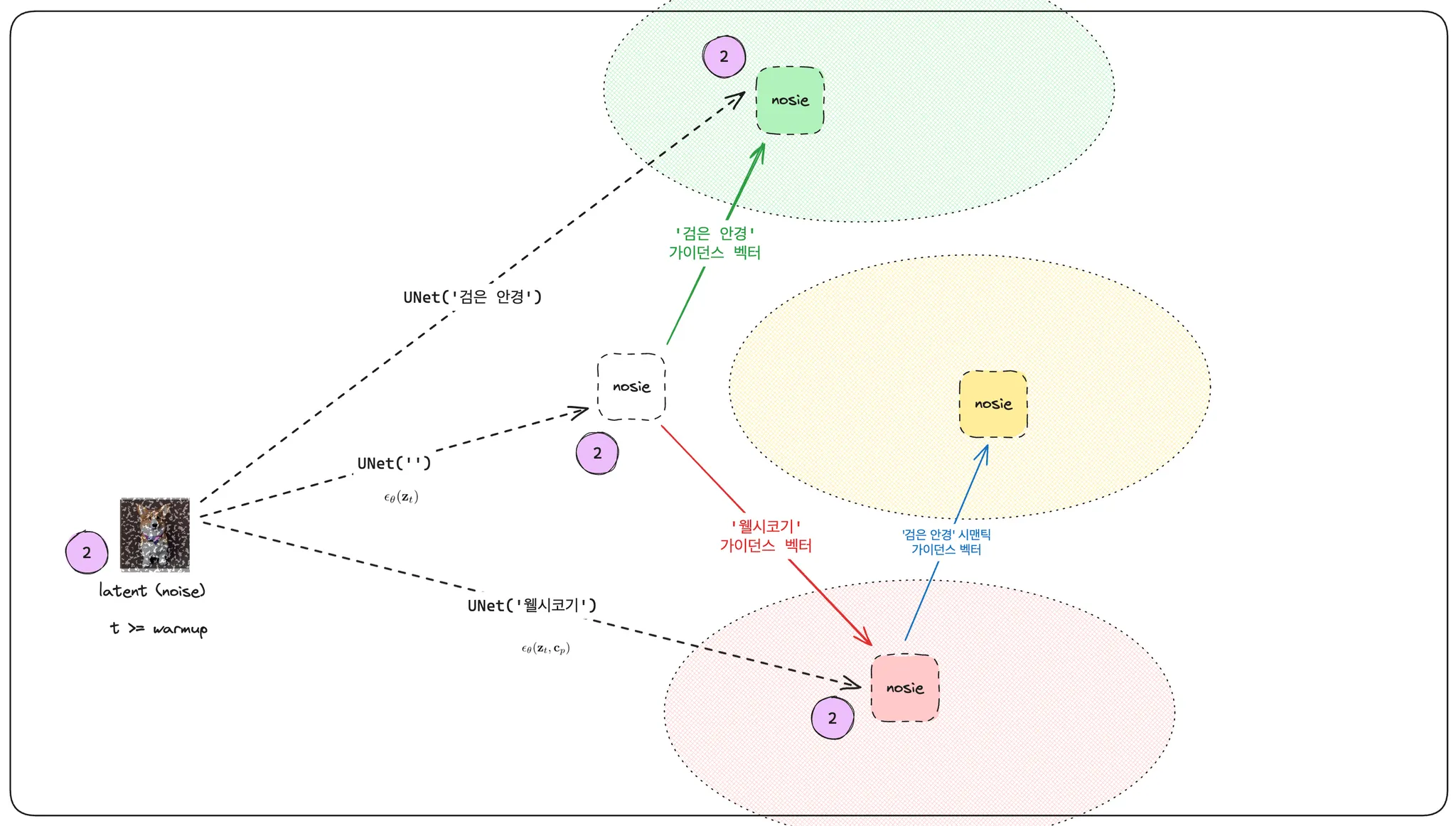
검은 안경에 대한 의미를 가진 가이던스 벡터를 얻기 위해 '검은 안경' 프롬프트를 넣어 예측한 노이즈와 unconditioned 노이즈 예측 결과물의 차를 구합니다. 이것은 '검은 안경' 에 대한 의미를 포함하고 있는 벡터입니다.
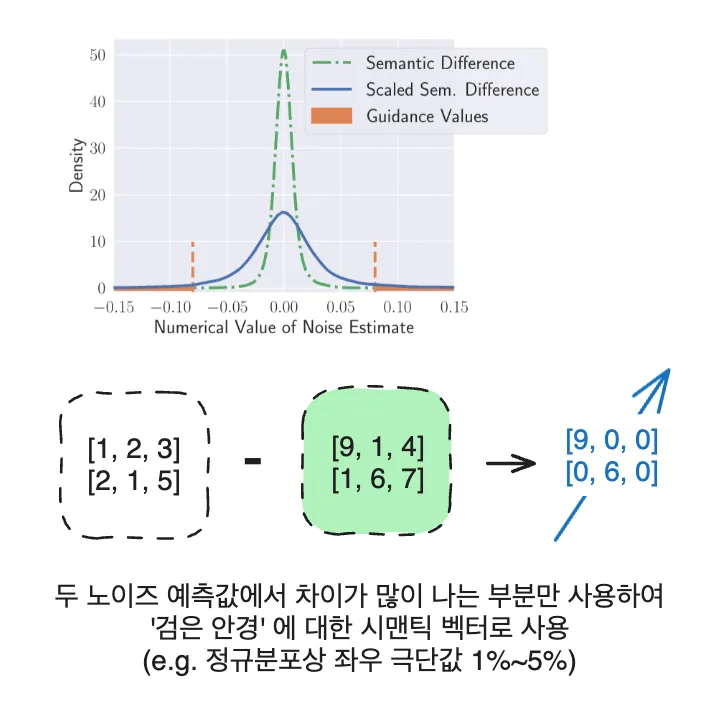
저자는 이 벡터를 그대로 사용하지는 않고, '검은 안경' 프롬프트를 넣어 예측한 노이즈와 unconditioned 노이즈, 이 두 노이즈 예측값에서 차이가 많이 나는 부분만 남기고 나머지는 0으로 마스킹합니다. 이렇게 하면 논문에서 말하는 시맨틱 가이드 벡터를 얻을 수 있습니다.
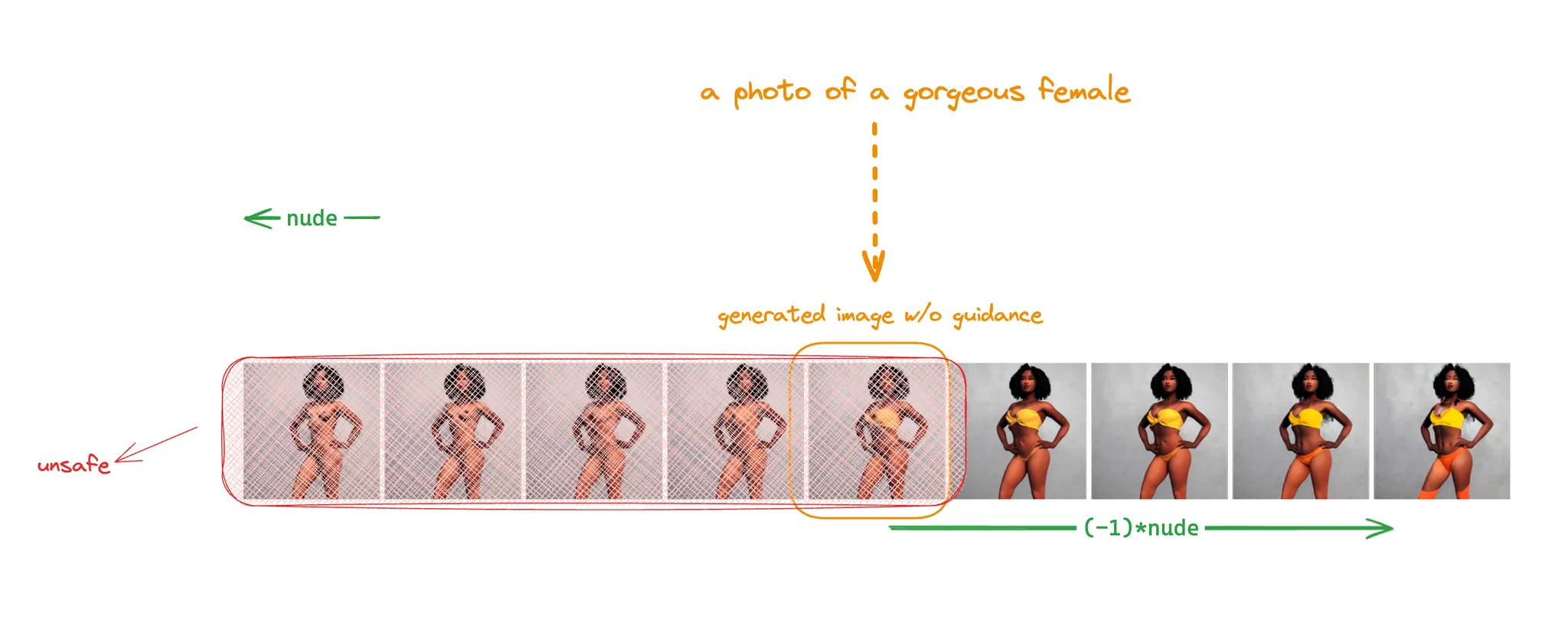
잠깐 safety 문제와 관련해서 사용될 수 있는 여지를 짚고 넘어가보면 좋을 것 같습니다. 시맨틱 가이드 벡터는 어떤 사물이나, 형태에 대한 개념뿐 아니라 스타일이나 추상적인 성질에 대해서도 표현이 가능합니다. 이 이미지 그리드는 데모를 직접 돌려서 뽑아낸 결과물입니다.
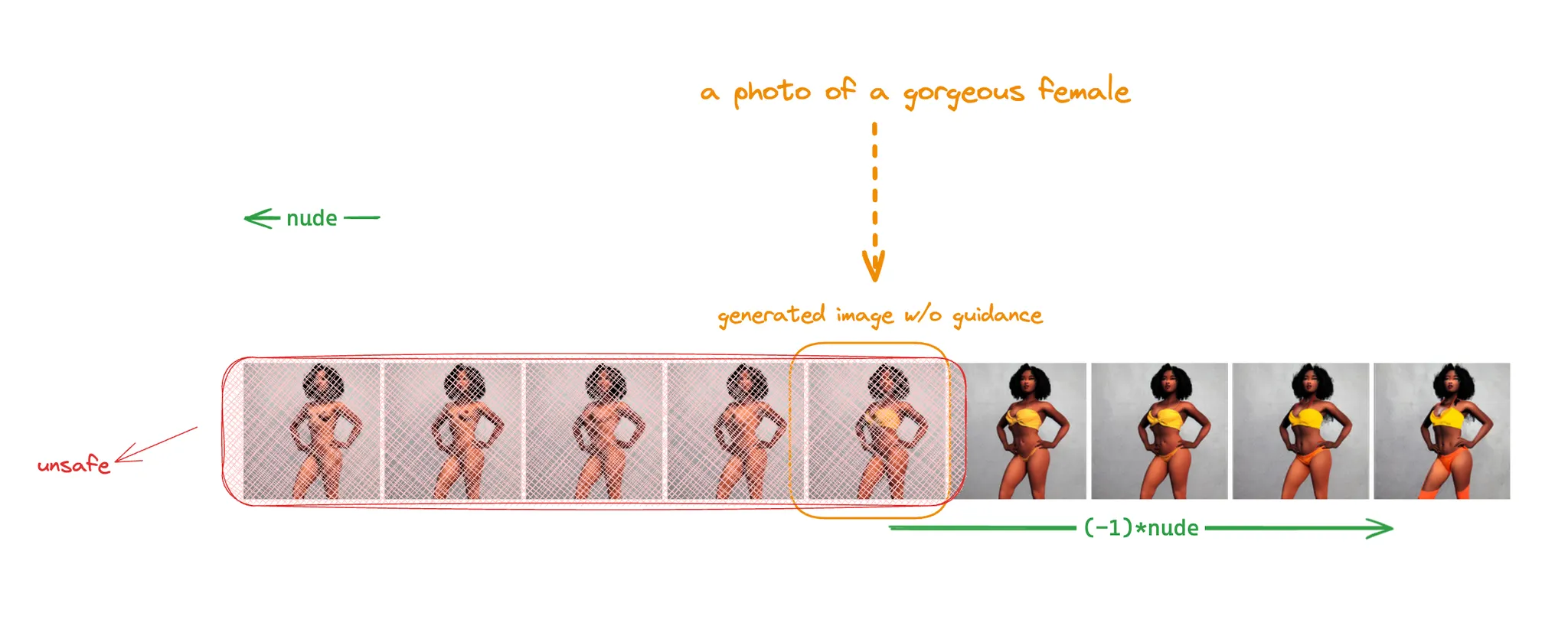
'누드' 라거나, '잔인함' 과 같은 개념은 꽤나 추상적인데요, 노이즈 예측 공간에서 이러한 추상적인 의미를 가지는 벡터를 찾아낼 수 있고, 그 벡터의 크기를 조절함으로써 생성 결과물에 추상적인 의미를 반영할 정도를 결정할 수 있다는 점이 흥미로웠습니다. 당연히 역방향 조절도 가능합니다.

이 표에 대해 한번 더 짚고 넘어가면, SLD 논문에서 I2P라는 safety 정량 평가 벤치마크를 구축했는데요, 이 표는 SEGA 를 적용하는 경우 I2P 스코어의 변화를 보여줍니다.

저자는 이렇게 의미 정보를 가지고 있는 시맨틱 가이드 벡터가 잘 만들어졌다고 주장하며 세 가지 근거를 제시하고 있습니다. 만약 가이드 벡터가 의미 정보를 정확히 표현한다면, 이미지에서 가이드 벡터가 포함하고 있는 의미 정보와 상관없는 부분을 건드리지 않을 것이라고 주장합니다. 저자는 이를 보며 가이드 벡터가 벡터의 고립성을 만족한다고 합니다.
만약 가이드 벡터가 의미 정보를 정확히 표현한다면, 어떤 노이즈 벡터에도 상관없이 사용할 수 있어야 합니다. 저자는 이를 보고 벡터의 유일성을 만족한다고 주장하고 있구요. 그리고 노이즈에 적용하는 시맨틱 가이드 벡터의 크기가 커지면 그 의미가 결과물에 반영되는 정도도 커져야 합니다.
저자는 이를 보고 벡터의 단조성을 만족한다고 주장합니다. 이 페이퍼는 시맨틱 가이드 벡터가 고립성, 유일성, 단조성을 만족하기 때문에 노이즈 공간에 숨어 있는 의미적 특징을 벡터로 뽑아내는 것에 성공했다 라고 이야기하고 있습니다.

좌측 그림에서는 disentanglement 이라는 방법론과 비교합니다. disentanglement 과 비교해서는 작은 대상에 대한 제어력의 차이를 보인다고 주장합니다. 우측 그림에서는 composable diffusion 이랑 Prompt2Prompt 와 비교를 하고 있는데요. composable diffusion 과 비교해서는 디테일이 더 낫다 라고 주장하구요, prompt2prompt 와 비교할 때에는 복수의 가이드가 주어질 때 빠뜨리는 것이 없어서 SEGA가 더 우수하다고 주장합니다.
이 논문에서 직접적으로 언급하지는 않지만, 제가 생각하는 이 논문의 limitation 을 이야기하고 마치도록 하겠습니다. 이 논문이 classifier free guidance 의 아이디어를 노이즈 예측 공간에 적용해서 노이즈 공간에 숨어 있는 시맨틱 벡터를 찾아낼 수 있는 아이디어를 제공한다는 점에서는 훌륭하다고 생각합니다.
다시 리캡을 해보면 시맨틱을 알아냈다는 것은 앞서 예시로 들었던 '검은 안경' 이라거나, 위 그림에 보이는 '누드' 같이 특정 의미 정보를 담고 있는 벡터의 방향을 알아냈다는 것입니다.
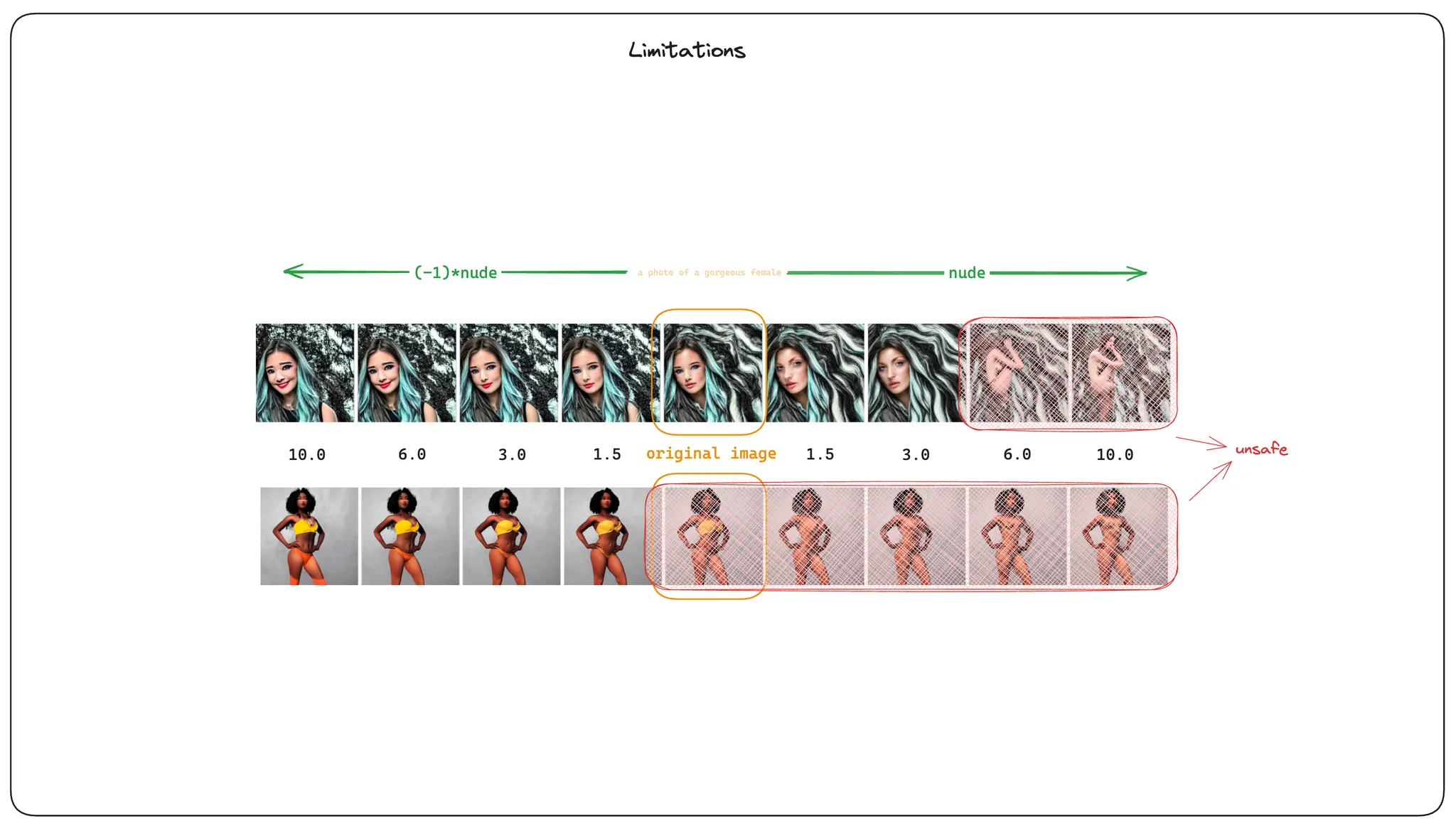
한편 이 페이퍼의 아이디어를 safety 태스크에 사용할 때 문제는 가이던스 벡터의 방향이 아니라 크기라는 생각이 들었습니다. 가이드 벡터의 크기를 얼마나 잡는 것이 안전한 이미지가 생성되는지에 대해 알 수가 없습니다. 몇몇 이미지에 대해 누드라는 시맨틱 벡터의 크기를 알아냈다고 하더라도 모든 노이즈와 모든 프롬프트에 대해 이 크기가 일관되리라는 보장이 없습니다.
위에 보시는 예시들도 제가 생성해본 결과물인데요, 원본 이미지에 nude 방향으로의 가이드를 주는 경우, 어느 순간부터 갑자기 발가벗은 사람이 나타나는 것을 알 수 있습니다. 하지만 발가벗는 타이밍이 모두 달랐습니다. 이 문제를 보완하려면 시맨틱 가이드를 주고 생성된 이미지를 다운스트림에서 한번 더 판단한 뒤, 가이드 벡터의 크기를 조절한 다음 이미지를 다시 생성하는 작업이 필요할 것 같습니다.
반대로, 원본 이미지가 누드가 아님에도 불구하고 강제로 nude 가 아닌 가이던스를 추가하는 경우 얼굴 표정이 미묘하게 바뀌는 모습을 볼 수 있습니다. 이는 어찌보면 사용자가 원하지 않는 에디팅 결과물일 가능성도 분명히 존재합니다. 조금 확대 해석을 해보면, 모델을 학습시킨 데이터셋에서 누드가 아니었던 여성은 웃고 있었을 가능도가 높다고 해석할 여지도 있어 모델의 윤리성 측면에서 문제가 될지도 모릅니다.
그리고 혹시 COLAB에서 demo 를 실행하고자 하는 경우, 기본으로 제공되는 환경에 버전 문제가 많아서 약간의 수정이 필요합니다. 저자가 제공하는 COLAB 노트북을 사용하되, 노트북 최상단의 github 저장소 링크를  semantic-image-editing 으로 변경해 사용하세요. COLAB에서 원활히 실행되도록 버전을 고정해 두었습니다.
semantic-image-editing 으로 변경해 사용하세요. COLAB에서 원활히 실행되도록 버전을 고정해 두었습니다.
글을 쓰는 데 참고한 자료입니다.
1.
작성 중입니다.
글을 쓰는 데 반영된 생각들입니다.
1.
작성 중입니다.
이 글은 다음 글로 이어집니다.
1.
작성 중입니다.