컴퓨터비전에서 Self-supervised Constrative learning (SSL) 모델의 핵심 아이디어는 레이블이 없는 이미지를 통해 (참고3) "이미지의 변형에 상관없이, 일관된 이미지 표현 (visual representation) 이 학습되도록 만들자" (참고1, 2) 이다.
Contrastive learning 은 이러한 아이디어를 각 개별 이미지마다 고유의 클래스 달고, 자기 자신의 (동일한 클래스) 특징은 끌어당기며 다른 이미지 (다른 클래스) 특징은 밀어내는 방식으로 구현한다 (참고4).
처음에는 과연 이런 방식이 실제로 가능하긴 할까 의구심이 들 수 있다. 나도 그렇게 헤매던 와중에 꽤 직관적인 설명을 들을 수 있었다.
이 사례를 보면 직관적으로 "어, 진짜 그렇잖아! 그럼 레이블 없이도 영상의 유사성 (e.g. 형태적(참고5),위상기하적(참고6)) 만가지고도 모델을 충분히 사전학습시킬 수 있다는 것 아닐까?" 하는 생각이 든다.
참고
3.
이렇게 supervised contrastive learning 도 있다. Recently, [32]* proposed supervised contrastive loss for the task of image classification. This loss can be seen as a generalization of the widely-used metric learning losses such as N-pairs [46] and triplet [56] losses to the scenario of multiple positives and negatives generated using class labels.
4.
We treat each image in the batch as if it had its own class. Unsupervised feature learning via non-parametric instance discrimination (2018) 에서는 L2 정규화를 한 뒤, 메모리 뱅크에서 현재 타깃 이미지의 과거 임베딩 벡터 (positive) & 나머지 이미지들의 일부 임베딩 벡터를 (negative) 샘플링한다. 현재 타깃 이미지의 임베딩 벡터를 앵커(anchor) 라고 하고, anchor 과 positve 을 끌어당기고 (pull), anchor 과 negative 가 밀어내도록 (push) 손실함수를 만든다. 이때 유사도를계산하는 것으로 Cosine 유사도를 사용한다. anchor 과 positive 를 분자로 올리고, softmax 로 만들면 NCE (Noise Contrast Estimation) loss 가 된다.  For image recognition, our model takes two images, x and y, as inputs. If x and y are slightly distorted versions of the same image, the model is trained to produce a low energy on its output. For example, x could be a photo of a car, and y a photo of the same car that was taken from a slightly different location at a different time of day, so that the car in y is shifted, rotated, larger, smaller, and displaying slightly different colors and shadows than the car in x.
For image recognition, our model takes two images, x and y, as inputs. If x and y are slightly distorted versions of the same image, the model is trained to produce a low energy on its output. For example, x could be a photo of a car, and y a photo of the same car that was taken from a slightly different location at a different time of day, so that the car in y is shifted, rotated, larger, smaller, and displaying slightly different colors and shadows than the car in x.
For image recognition, our model takes two images, x and y, as inputs. If x and y are slightly distorted versions of the same image, the model is trained to produce a low energy on its output. For example, x could be a photo of a car, and y a photo of the same car that was taken from a slightly different location at a different time of day, so that the car in y is shifted, rotated, larger, smaller, and displaying slightly different colors and shadows than the car in x.그림
•
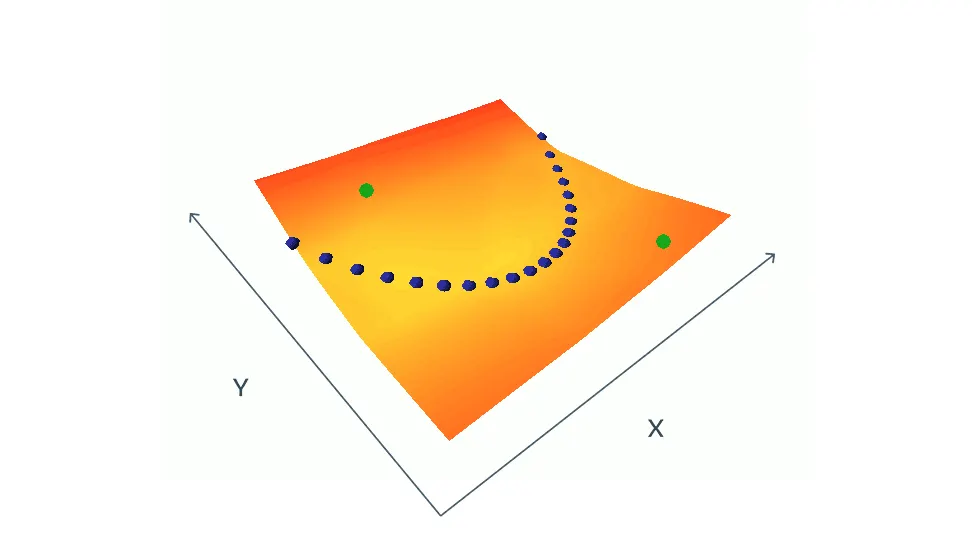
파랑 점 : energy of compatible (x,y) pairs from the training set
초록 점 : well chosen (x,y) pairs that are incompatible, symbolized by the green dots
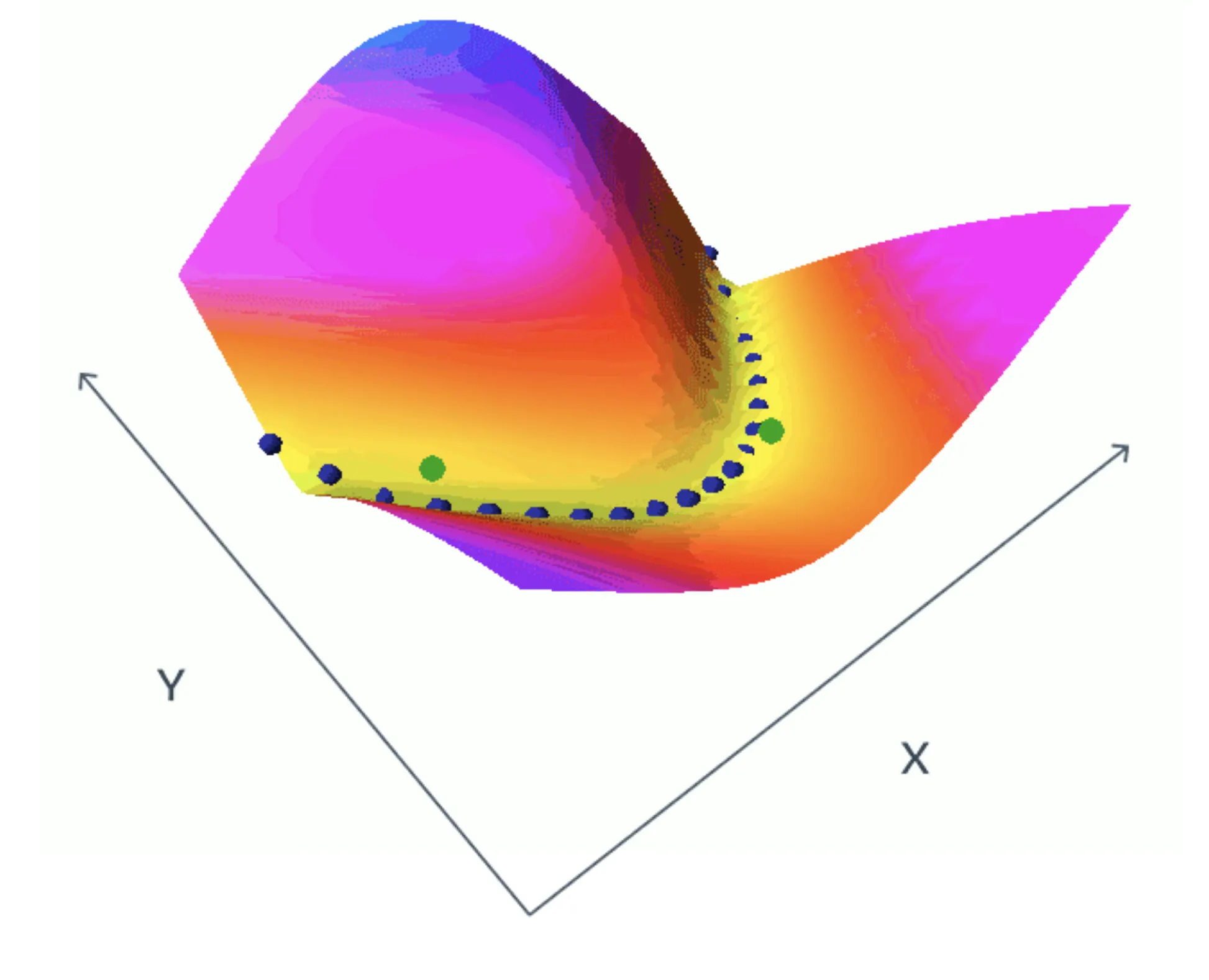
학습 결과