
KDE란 커널함수(Kernel)(ref5)를 통해서 자연에 이미 존재하는 연속함수의 분포를 추정(Density Estimation) 하는 작업을 의미한다. 결국 정확한 자연의 연속함수를 모델링한 것은 아니라는 것을 기억할 필요가 있다. KDE는 결국 우리가 취득한 이산적인 데이터로부터 자연의 확률분포를 추정해 보는 것이다(ref2,ref3,ref4,ref7).
우리는 불연속으로부터 연속함수를 만들기 위해 그럴싸한 가정을 여러 개 덧붙인다. 첫째, 각 데이터포인트들을 대치하는 커널 함수에 대한 인간의 그럴싸한 가정. 둘째, 가우시안(커널이 가우시안인 경우)의 표준편차에 대한 그럴싸한 가정이다. 어떤 커널 함수를 선택하고, 어떤 표준편차값을 선택해야 하는지 고민하는 것도 결국 인간의 몫이다. 이를 직관적으로 이해하기 위해 아래 그림을 보자.
그림 (참고1)
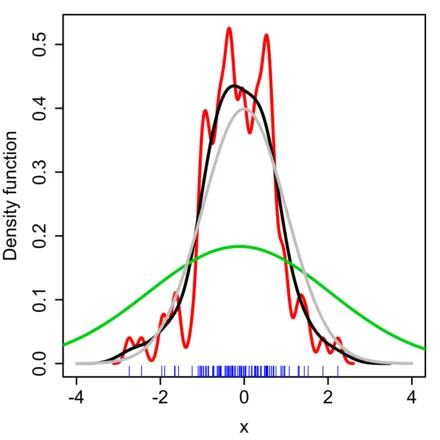
그래프에서 파란색은 자연에서 채취한 이산적인 데이터들이다. 그래프에서 빨간색, 초록색, 회색, 검정색 실선은 확률밀도함수이다. 우리는 고등학교 때 확률변수라는 함수의 치역이 이산적이라면 확률질량함수(probability mass function)를 그렸고, 확률변수라는 함수의 치역이 연속적이라면 확률밀도함수(probability density function)를 그렸다.
이산적인 100개의 데이터 포인트 (파란 점) 각각에 대해 조금씩 다른 정규분포를 적용한다고 상상해 보자. 위 그림의 빨간색, 초록색, 회색, 검정색 실선은 정규분포라는 연속함수의 합이 만들어낸 결과물이다. 다시말해 그림에서는, 인간의 첫 번째 직관인 “각 데이터포인트들을 대치하는 커널 함수에 대한 인간의 그럴싸한 가정”이 정규분포(가우시안)이고(ref5,ref6:어떤 feature 들로 데이터포인트를 구성할 것인가도 가정이다), “정규분포(커널이 가우시안이므로)의 표준편차에 대한 여러 가지 후보들”을 제시하여, 어떤 표준편차를 선택하는가에 따라 예상되는 자연의 데이터 분포를 각각 다른 색깔로 표현했다.
그림(ref5)
커널로 사용할 수 있는 다양한 함수들
우리는 어떤 색깔의 선이 가장 파란색 데이터를 잘 표현한다고 생각하는가? 정말 슬프게도 정답은 없다. 순전히 내가 이러한 작업을 하는 목적에 잘 맞는다고 알려진 그럴싸한 가정을 채택하고 이것이 정답이라고 가정하고 다음 논리를 전개할 뿐이다.
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료을 보관해 두는 영역입니다.
1.
None
from : 과거의 어떤 원자적 생각이 이 생각을 만들었는지 연결하고 설명합니다.
1.
•
KDE와 같이 이산적인 각각의 점들에 인간의 직관을 더해서 확률밀도함수를 추정하는 행위를 비모수적 밀도 추정(Non Parametric Density Estimation)이라고 부른다.
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는지 연결합니다.
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는지 연결합니다.
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되거나 이어지는지를 작성하는 영역입니다.
2.
ref : 생각에 참고한 자료입니다.