

그림 (참고1)
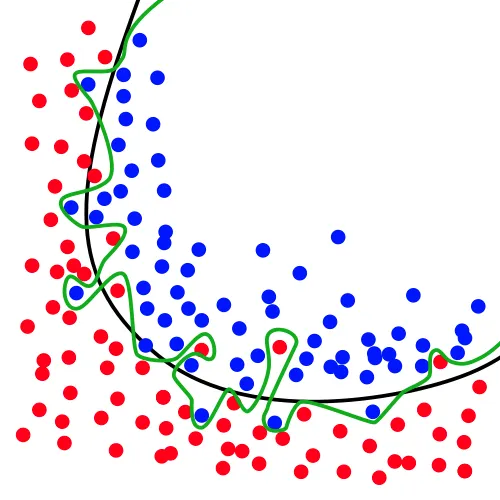
불쌍한 오버피팅과 언더피팅
머신러닝을 공부한 사람이 한번쯤 들어보는 유명한 용어로 과대적합(overfitting) 과 과소적합(underfitting)(참고1,2) 이 있다. 머신러닝이 할 수 있는 대표적인 작업에는 분류작업이 있다. 많은 사람들이 분류기를 학습시킬 때 위 그림(그림 참고1)에서 초록색 선과 같이 분류기준이 만들어진다면 과대적합이라 좋지 않은 것이라고 가르친다. 검정색 선과 같이 분류기준이 만들어져야 이상적이라고 말한다.
검정색 선을 옹호하는 사람들에게, 실제 데이터가 초록색 선이 나타내는 것처럼 분포할수도 있는 가능성은 왜 배제하는지 물어보고 싶다. 위 그림에서 검정색 경계선이 더 나을 것이라는 확신은 도대체 어디에서 왔을까? 사람은 어떻게 검정색 경계선이 초록색 경계선보다 실제 데이터를 잘 갈라낼 것이라고 확신할 수 있는가. 정말 혹시라도 검정색 경계선이 초록색 경계선보다 더 좋다고 생각이 된다면, 왜 좋다고 생각하게 되었는가?
억지로 트집을 잡는 것이 아니다. 나는 이것이 완전히 인간의 직관의 영역이라는 결론을 내렸다. 인간의 직관은 정말 훌륭한 판단을 내리는 데 도움을 주기도 하지만(참고5), 직관에 의한 판단이 상당히 비이성적일 수 있다는 사실을 부정하는 사람은 없을 것이다. 지금부터 왜 과적합이나 과소적합을 판별하는 것이 직관의 영역이라고 생각하게 되었는지를 설명해 보려고 한다.
오버피팅, 언더피팅이라는 단어 어디 히스토그램에도 한번 써보시죠
그림 (참고4)
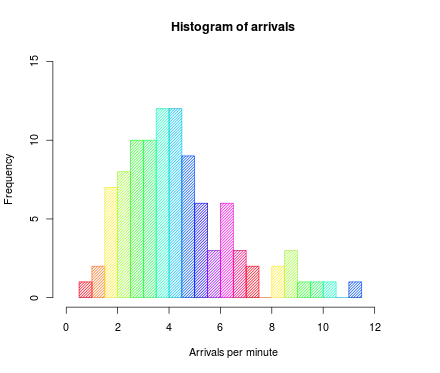
이렇게 생긴 그래프를 히스토그램이라고 한다.
import numpy as np
friends_tall = np.random.randn(100)*10 + 160
Python
복사

대표적으로 히스토그램의 구간을 어떻게 설정하느냐도 직관에 달렸다. 위 자료가 내 친구들 중 50명을 골라 키를 재어 만든 목록이라고 생각해 보자. 아래 그림은 그 데이터를 히스토그램으로 바꾸어낸 결과물이다. 이중에서 어떤 것이 가장 ‘적절한’ 히스토그램인가?
import matplotlib.pyplot as plt
bin_candidates = [5, 7, 9, 11]
plt.figure(figsize=[8, len(bin_candidates)*3])
for i, n_bins in enumerate(bin_candidates, 1):
plt.subplot(len(bin_candidates), 2, i)
plt.hist(friends_tall, bins=n_bins)
Python
복사

위에 존재하는 네 개의 히스토그램이 모두 다 정답이 될 수 있다.
이번에도 똑같은 히스토그램을 그려 보겠다.
import matplotlib.pyplot as plt
bin_candidates = [3, 19, 25, 31]
plt.figure(figsize=[8, len(bin_candidates)*3])
for i, n_bins in enumerate(bin_candidates, 1):
plt.subplot(len(bin_candidates), 2, i)
plt.hist(friends_tall, bins=n_bins)
Python
복사
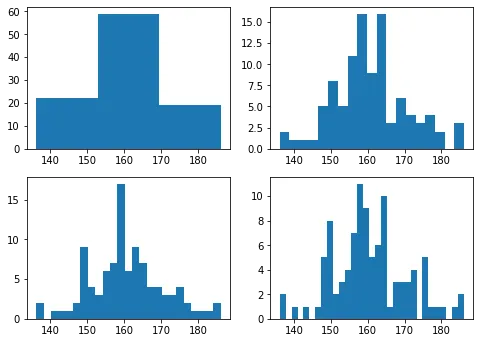
그런데 이번에 그린 히스토그램은 보이다시피 조금 못생겼다. 왜 우리는 이걸 못생겼다고 생각할까? 조금 더 수학적인 질문을 해 보면, 히스토그램의 적절한 구간(bin) 을 정할 수 있는 기준은 무엇일까? 나는 없다고 본다. 하지만 왜인지 모르게 방금 만들어낸 못생긴 네 개의 히스토그램보다 조금 더 앞서 보여 준 네 개의 히스토그램이 조금 더 ‘편안’ 하다.
그림 (참고3)
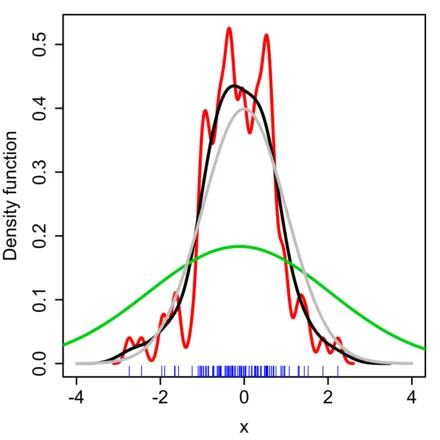
자연에서 무엇인가를 관측하여 데이터로 집어넣는 순간 불연속성을 가지게 된다. 위 그래프(그림 참고3)를 보자. 그래프 하단의 얇은 파란색 선은 자연에서 채취한 이산적인 데이터들이다. 그래프에서 빨간색, 초록색, 회색, 검정색 실선은 확률밀도함수이다. 우리는 고등학교 때 확률변수라는 함수의 치역이 이산적이라면 확률질량함수(probability mass function), 확률변수라는 함수의 치역이 연속적이라면 확률밀도함수(probability density function)를 그렸다.
“커널밀도추정”(from2) 이라는 도메인에서는, 파란색 이산적 데이터를 가지고 어떻게 확률밀도함수를 그려낼 수 있을까를 고민한다. 그런데 여기서 의문이 생긴다. 빨간색같이 디테일이 살아있는 그래프가 좋은 그래프일까? 아니면 진짜 커다란 윤곽만 남긴 초록색 그래프가 좋은 그래프일까? 인간은 정답이 무엇이라고 단정지을 수 없다(to2).
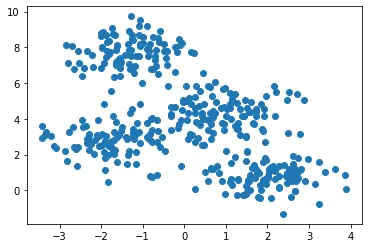
대표적으로 클러스터링(군집화)은 커널밀도추정이라는 개념을 활용한 응용 애플리케이션이다. Mean Shift 라는 클러스터링 방법론은 결국 각 데이터 포인트들을 어떤 연속함수로 바라볼지에 대해 인간의 직관을 개입시킨다. 인간의 직관에 근거하여 다양한 방법으로 데이터들을 군집화해볼 수 있다. 위 그래프에 나타난 산개점분포도(scatter plot) 에 클래스를 매긴 아래 그림을 보자. 어떤 결과가 정답일까?
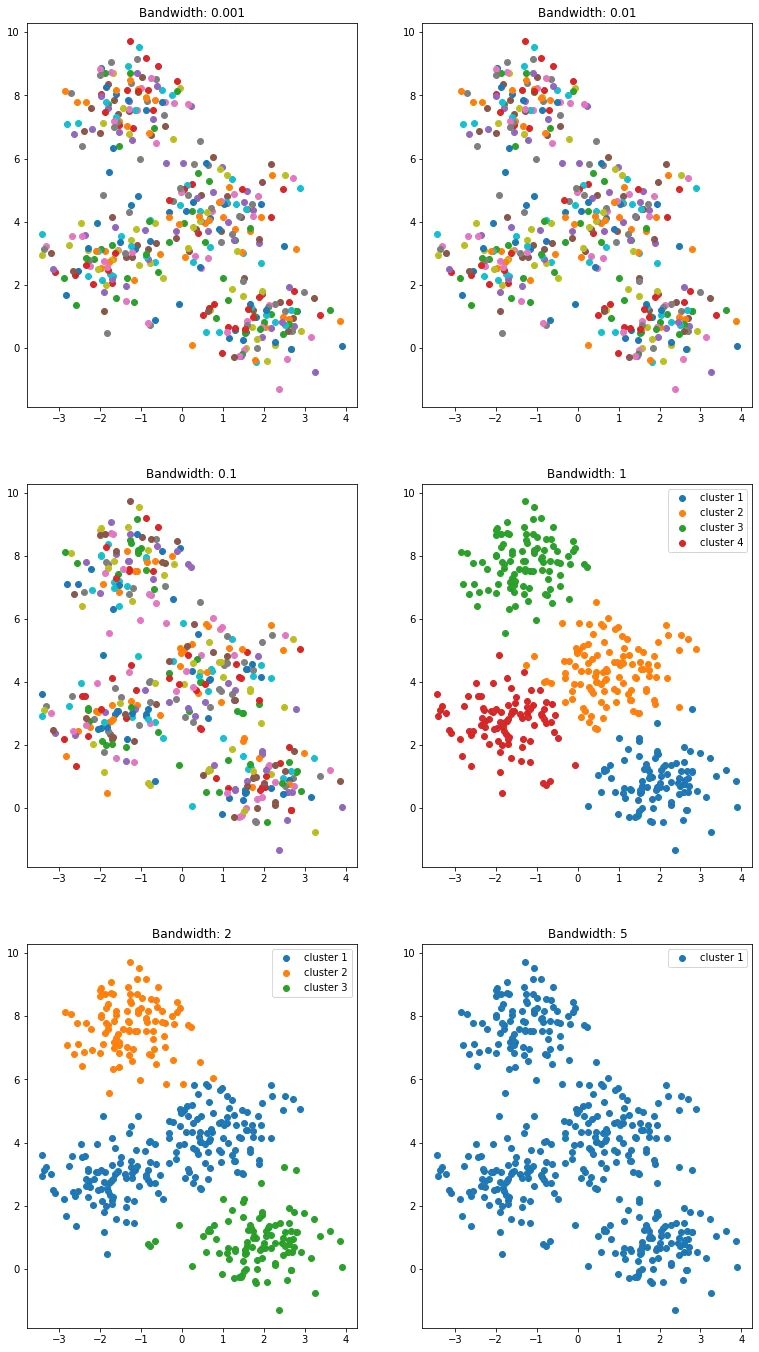
평범하게 살아 온 인간이라면 위 여섯 개의 결과물 중에 두 개(bandwidth: 1, 2) 에 높은 만족도를 보일 것이다. 그런데 만약 저 데이터들을 표현하는 일에 정답이 있다면 그 두 개 중 왜 하나로 정답을 내리지 못하고 있는가 생각해 볼 필요가 있다. 그럼 한발 더 나아가서, 저 두개를 무슨 근거로 정답으로 인정해 주어야 하는걸까?
오버피팅과 언더피팅은 진리가 아니라 인간의 경험에서 나온 직관
그림 (참고1)
다시 돌아와서 이 그림을 보자. 오버피팅과 언더피팅은 2017년 이후 딥러닝과 머신러닝 분야를 통틀어 가장 많이 사용된 단어다. 이들 단어들은 데이터에 대한 표현력을 논할 때 소통을 정말 많이 편하게 만들어 준다는 점에서 충분히 제 역할을 잘 하고 있다(from4).
하지만 내가 말하고 싶은 것은, 우리는 자연이 어떻게 생겼는지 모르기 때문에, 오버피팅, 언더피팅에는 어떠한 정답이 없다는 것이다. 부족한 데이터로 굽이굽이 초록색 실선처럼 구분하는 모델을 만들었는데 실제로 저것이 현실세계를 더욱 잘 모사할 수 있다는 것이다. 문제에 대한 최적해는 풀고자 하는 문제와 해당 문제의 평가지표(metric)에 의해 수동적으로 결정되어 버린다. 문제를 정확히 정의하는 것이 정말 중요한 이유이기도 하다(from3).
혹시 머신러닝을 업으로 삼을 생각이라면, 그냥 그래프가 구불구불하다고 다짜고자 오버피팅되었다고 여기는 편협한 생각은 위험하다는 것을 인지해야 한다. 그 본질에는 자연에서 샘플링된 데이터로부터 자연의 분포를 추정하려고 하는 인간의 욕망이 있고, 다양한 추정치들 중 어떤 것이 자연의 분포를 더 잘 표현하는가를 결정하는 것은 순전히 인간의 경험적 직관에 달렸다는 진리가 있다(참고6).
작성: 이장후 @4/4/2022
참고
from (글을 쓰는 데 반영된 생각들과 경험들)
to (이 생각으로부터 이어진 생각들과 경험들)
1.
2.