
디어에서 자율주행 킥보드를 만들 때 이미지 segmentation 추론 결과가 특히 가장자리 부분에서 프레임별로 흔들리는 경우가 많았다. 처음에는 이것이 이미지 전체의 정보를 고려하지 못해서 발생하는 문제로, 부족한 receptive field가 원인이 아닐까 추측했다. 하지만 당시에도 충분히 깊이가 깊은 convolution 모델을 사용하고 있었기 때문에 이것이 문제라고 생각하기는 어렵다고 판단했다. 그 대신, 하기한 문제들이 총체적으로 조합되어 segmentation 결과물의 가장자리 추론 결과가 흔들리는 문제가 발생했던 것이 아니었을까.
다음 용의자는 domain gap이었다. 학습 시에 사용했던 이미지의 분위기(어렵게 말하면 데이터 분포)와 크게 달라진 환경, 카메라 세팅에서 segmentation 결과물을 사용하려고 하는 것이 문제일 수 있겠다는 생각이 들었다. 우리는 domain gap 문제를 해결해야 했다(ref2).
또다른 용의자는 semantic loss였다. semantic loss는 적절한 단어를 찾지 못해 내가 임시로 만들어 붙인 용어이다. 아래와 같은 이미지가 있다고 할때, 좌측 하단의 조금 더 새까만 영역은 횡단보도의 일부일까, 인도의 일부일까, 차도의 일부일까?

segmentation이 수행되어야 하는 이미지
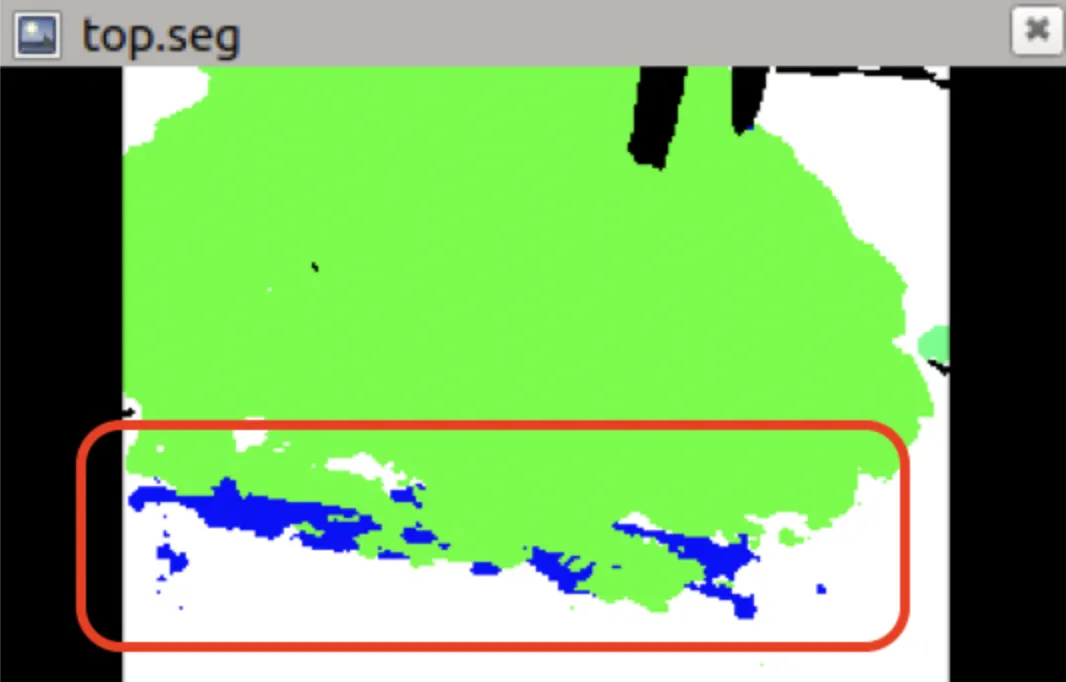
segmentation 추론 결과. 굉장히 불안정한 추론을 보여준다.
솔직히 그 당시에는 당연하다고 생각하지 못했지만, 현재 프레임, 한 장의 이미지만을 가지고는 영상 가장자리의 영역이 어떤 클래스인지 맞추는 것은 무리가 있다. 우리는 어떻게 부족한 semantic 정보를 주입해줄 수 있을지 고민해야 했다.
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료을 보관해 두는 영역입니다.
1.
from : 과거의 어떤 원자적 생각이 이 생각을 만들었는지 연결하고 설명합니다.
1.
•
앞의 글에는 자율주행 킥보드를 개발하며 발견한 domain gap 문제와 그와 관련있었던 이슈들에 대해 집중적으로 다룬다.
2.
•
‘의미를 가진(Semantic) 정보 손실’은 앞의 글에서 내가 정의한 단어이다. 더 좋은 단어가 있을지도 모른다. 나는 이미지 대신 동영상을 이용한다면 이 문제를 해결할 수 있을 것이라고 생각했다.
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는지 연결합니다.
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는지 연결합니다.
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되거나 이어지는지를 작성하는 영역입니다.
ref : 생각에 참고한 자료입니다.
1.
None