
원본 영상에서 부분영상을 추출해낼 때 어떤 전략을 취할 것인지 결정하는 일은 굉장히 중요하다. 딥러닝 영상처리에서 가장 우선적으로 고려되어야 하는 것은 런타임에 스트리밍되는 영상과 훈련 영상이 형태(ref1)의 분포와 색상의 분포가 유사해야 한다.
우선 카메라의 상태가 학습 데이터를 얻은 카메라 상태와 최대한 비슷해야 한다. 카메라 상태란 FOV에 대한 정보를 담고 있는 Camera intrinsic(ref2), 카메라가 실제 촬영시에 얼마나 기울여진 채로 촬영됐는지, 지면에서 얼마나 높이 떨어져 있는지의 정보를 담고 있는 Camera extrinsic, 영상의 전체적인 색감과 밝기 등을 모두 포함한다. 하지만 인터넷에서 얻은 데이터셋에 대해 이들을 엄밀하게 수행하는 것은 어려우므로, 정성적으로 비교하며 맞추어 가야 한다.
그림(ref3)

cityscapes

pedestrian (aihub, surface mask)

pedestrian (aihub, object detection)

KU, real world (intel realsense, 640x480, deer corp.)
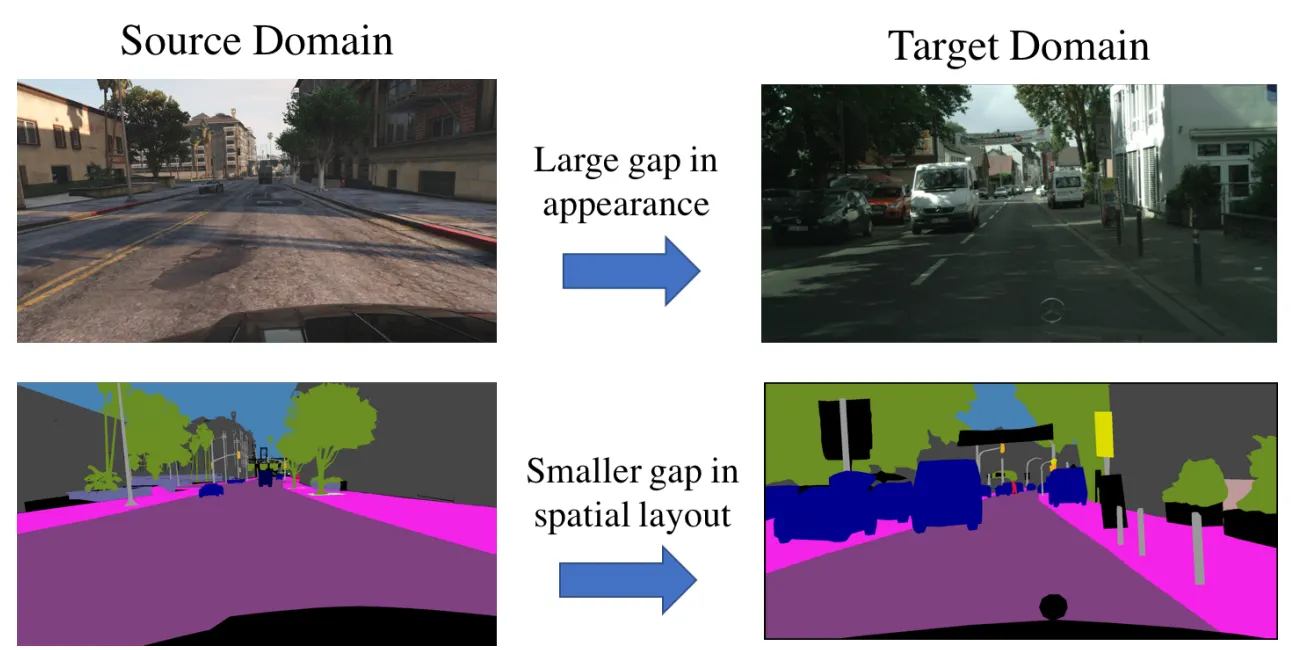
domain gap (Learning to Adapt Structured Output Space for Semantic Segmentation) 그림 발췌
이렇게 유사성을 최대한 높이는 것을 ‘도메인 차이’(domain gap)을 줄이는 일이라고 부른다. 도메인 차이가 생기는 상황은 아주 흔한데 실제로 현대자동차도 이와 비슷하게 차종마다 카메라의 부착 위치가 달라서 카메라의 pose 에 따라 동일한 모델을 적용할 수 없는 어려움을 겪고 해결 중에 있다고 말한 적 있다(ref4:현대자동차의 사례).
parse me : 언젠가 이 글에 쓰이면 좋을 것 같은 재료을 보관해 두는 영역입니다.
2.
5.
from : 과거의 어떤 원자적 생각이 이 생각을 만들었는지 연결하고 설명합니다.
1.
None
•
연결한 이유
supplementary : 어떤 새로운 생각이 이 문서에 작성된 생각을 뒷받침하는지 연결합니다.
1.
None
opposite : 어떤 새로운 생각이 이 문서에 작성된 생각과 대조되는지 연결합니다.
1.
None
to : 이 문서에 작성된 생각이 어떤 생각으로 발전되거나 이어지는지를 작성하는 영역입니다.
ref : 생각에 참고한 자료입니다.