테슬라는 IMU, GPS, Odometry, multi camera 영상들이 모여 최대 45초의 비디오 클립과 데이터 집합을 서버로 전송한 뒤 가공하여 사용한다 (참고6). 2017년 초기 서드파티를 사용하던 것을 퀄리티와 속도상의 이슈로 중단하고 (참고1) 인하우스에서 엔지니어가 밀착하여 일반적인 기업처럼 2D 레이블링을 하는 체제로 전환했다 (참고2). 하지만 2D 평면에서 모든 프레임에 대해서 처리하는 레이블링은 비효율적이었고, 이를 3D 벡터 공간 (참고4:벡터공간) 에서 레이블링을 하여 자동으로 2D 평면으로 변환해 주는 체제로 변경하여 1000 배 이상의 레이블링 속도 향상을 만들었다 (참고3).
하지만, 이것도 사람과 컴퓨터 각각이 잘 하는 일을 하는 것이라고는 생각하지 않았고 (참고5) 오토 레이블링 파이프라인에 투자하기 시작했다. 사람은 어떤 씬을 보고 의미적으로 구분하는 것을 잘 한다. 하지만, 어떤 물체의 속력을 구하거나, 어떤 정적 구조물을 3D 로 복원해 내는 일을 매우 어려워한다 (참고 5, 12).
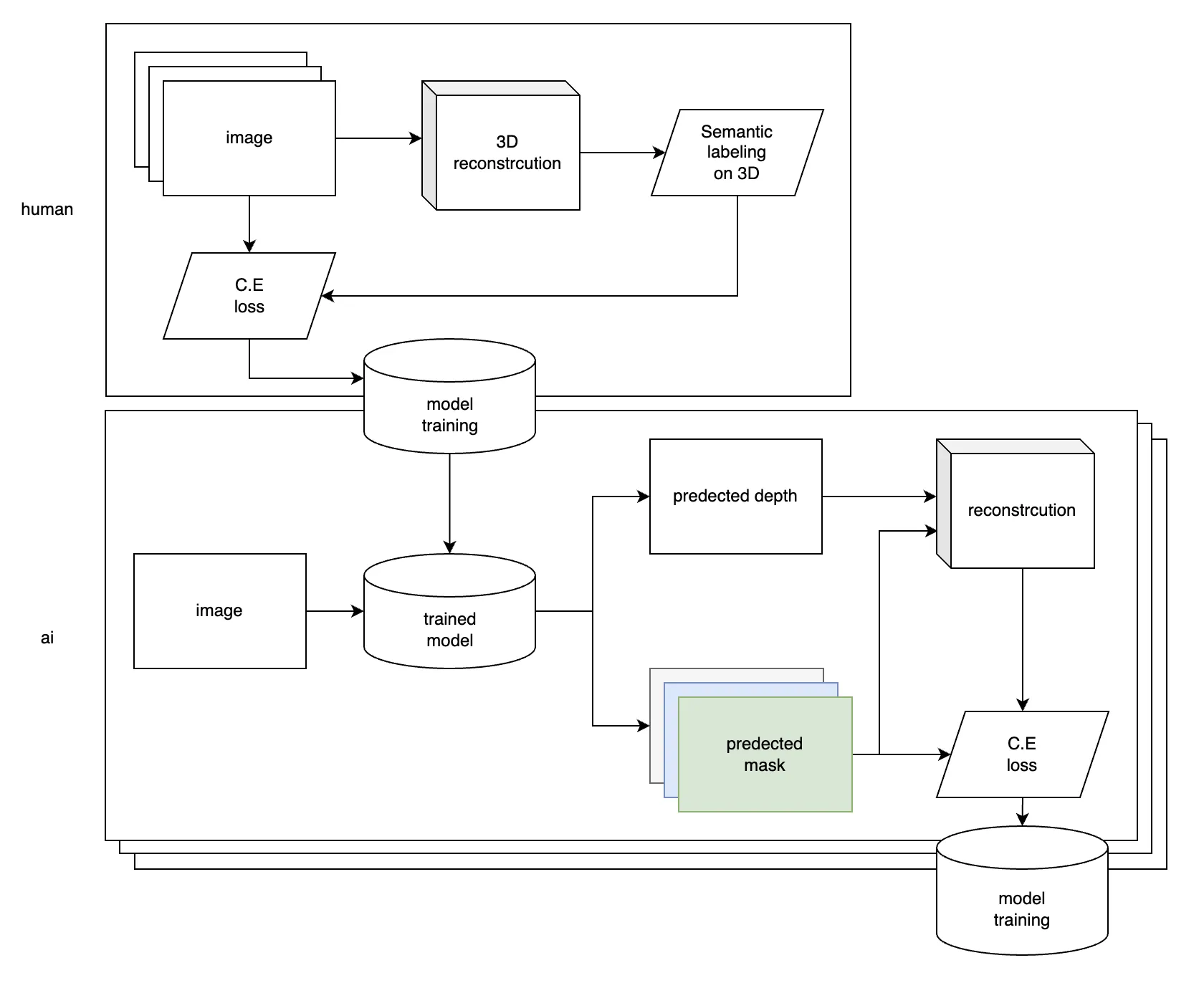
그래서 @11/28/2021, 8:38:00 PM 내가 생각하기에는 위와 같은 구조를 만들었다는 것 같다 (참고12).
만약 도로를 레이블링해야 한다고 생각해 보자. 우리가 보통 도로를 레이블링한다고 하면, 어떤 2차원 평면에다가 n차 다항식으로 표현되는 선을 만들거나 segmentation mask 를 만들어내는 방식으로 레이블했을 것이다. 테슬라는 이것이 미분불가능하다는 문제가 있다는 것을 지적하며, 도로 표면을 neural radiance field 에서 제안한 대로 implicit representation 으로 표현한다 (참고7).
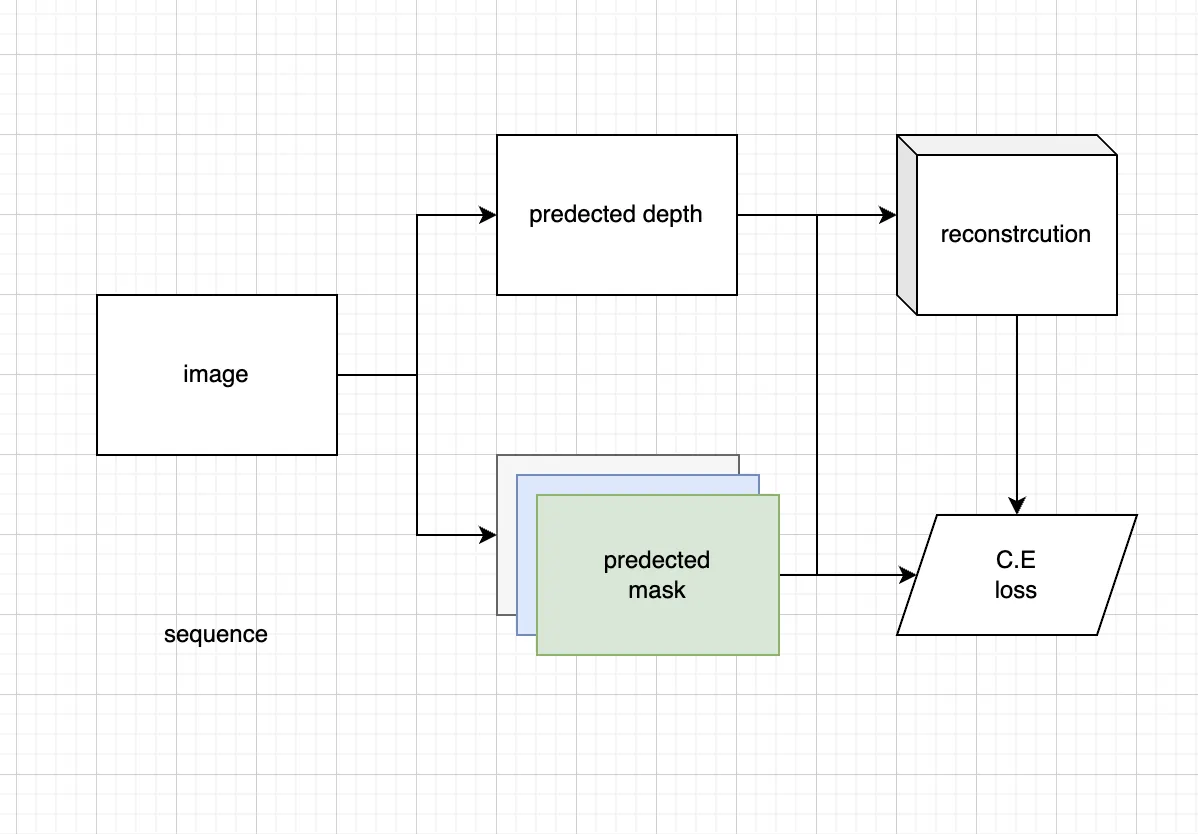
아직 implicit representation 이 뭔지 모르는 상태에서 그린 그림 ㅋㅋ

네트워크에 좌표 x, y 를 넣으면 (쿼링하면), 지표면의 높이나, 도로의 경계나, 차선 여부 등을 예측한다 (참고8). 2D 공간에서 depth 와 segmentation mask 를 얻는데, depth 가 있기 때문에 labeled pointcloud 를 만들어낼 수 있다. 이렇게 차량에 부착된 모든 카메라로부터 얻은 영상을 네트워크에 넣은 결과물을 3D 공간으로 만들어볼 수 있다. 3D 공간을 각각의 카메라에 맞게 2D 평면으로 reprojection 한 뒤, 2D 평면상의 예측 결과와 C.E loss 를 적용한다. 이것을 모든 시퀀스에 대해서 종합하여 optimization 한다 (참고9). 그렇게 하면 굉장히 consistent 한 representation 을 얻어낼 수 있다.
이 컨셉을 활용하면, 네트워크가 일부 패치를 유도리 있게 제외할 수 있게 되는 등 다수의 플릿이 비디오만 보내오면 해당 공간의 특징을 업데이트할 수 있기 때문에 유지보수 측면에서 굉장히 훌륭해진다 (참고10). 또한 훈련에 사용될 데이터셋에 가려진 부분을 모두 표현할 수 있다는 것이 장점이다 (참고13).

참고

4.