
자율주행에 HD Map 을 사용해야 한다고 말하려는 것이 아니다. 나는 이 글을 통해 데이터를 한 장 한 장 레이블링하는 방식에서 벗어나, 3D HD Map 이 만들어지는 '3D 공간' 상에서 레이블링해보는 것은 어떠냐고 제안하고 싶다. Mono/Stereo 카메라로부터 촬영된 영상들만 가지고도 3D Pointcloud Map 을 구축할 수 있다고 알려져 있다. 이렇게 영상의 집합으로부터 3D 모습을 추정해내는 것과 관련된 문제(task)에는 SfM(Structure from Motion), 3D Reconstruction, View Synthesis, Volume Rendering(참고42) 등이 있다.
무엇보다 이 Reconstructed 3D Pointcloud Map 을 만들게 되면 상당수의 데이터문제를 극복할 수 있다는 것이 HD Map 구축의 가장 큰 장점이다. 지금 디어의 상황을 돌아보았을 때, 앞으로 반드시 개선해 나가야 할 점은 데이터라고 생각했다. 구체적으로 말하면 우리 태스크에 알맞은 데이터 자체가 풍부하지 않은데다 우리가 사용하는 영상에 temporal/spatial semantic (시공간적 의미) 정보가 전혀 존재하지 않는다는 점이다(참고3,6,9). 이 문제를 '우리가 당장 해결할 수 없는 것' 이라고 여기며 회피하다 보니, 되려 마주칠 필요가 없었을지도 모르는 병목점들을 끊임없이 마주쳐 왔던 것 같다.
지금까지 만났던 병목들은 다음과 같다. 1. 현재 시퀀스의 1개 프레임의 영상만으로는 정확한 추론이 어려운 것이 사실인데도(참고9,10,22) 비디오 모듈 개발을 할 수 없다. 2. 점자블럭의 키포인트를 찾아내는 등 더 정교한 시도들을 하지 못한다. 3. 데이터셋의 도메인 차이 때문에(참고8,9) 덕지덕지 장착돼 있는 카메라를 포기하지 못하고, 카메라 개수를 줄이기 위해(참고34) 마음대로 광각 카메라로 바꿔 끼우지도 못한다(참고9,32,33). 4. 보행 영역이 moving object 에 의해서 가려지면, moving object 가 없을때를 기준으로 추론하지 않고 해당 부분을 그냥 '절대로 갈 수 없는 부분' 으로 치부할 수밖에 없다. 데이터셋이 없기 때문에 생겨나는 문제들을 피하기 위해 너무 많은 시간과 불필요한 비용들을 태우고 있다(참고9,22).

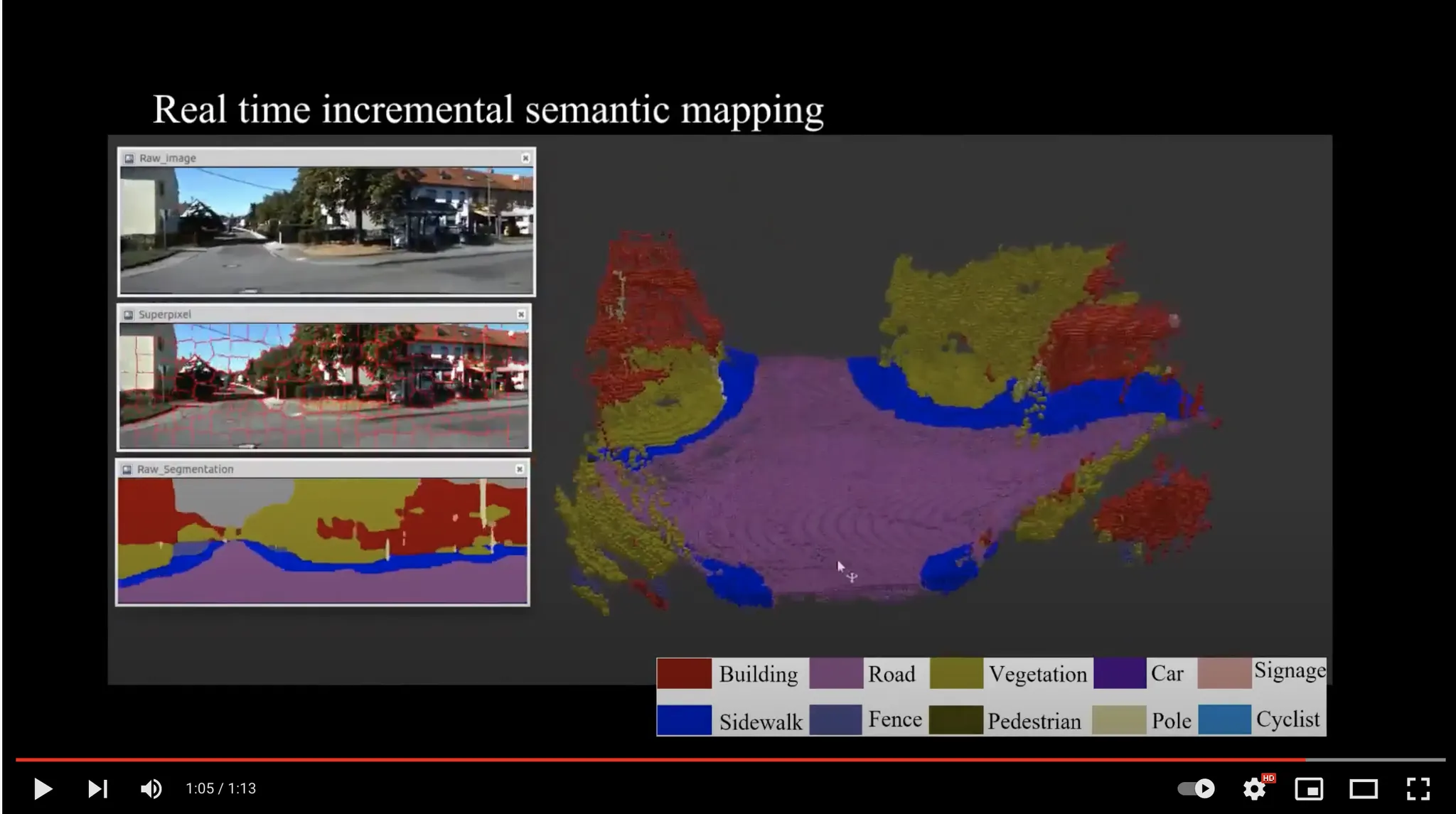
3D 공간상의 노란색 선이 도로의 경계를 표현한다. 3D 공간상에서는 선 한 번으로 모든 것이 정의되지만, 이를 시간에 따른 2D 평면의 움직임으로 해석하면 거의 무한한 데이터를 생성해낼 수 있는 것이라고 볼 수 있다.
그림(참고31) 그림에서 오른쪽 semantic 결과를 3D 공간상에서 만들어낼 수 있다면, 왼쪽 영상들 중 가장 아래 있는 영상은, 카메라 angle 이 어떻게 되든 다 만들어낼 수 있다.
위에서 언급한 각각의 문제들을 해결하기보다 문제의 본질을 찾아서 해결하려는 관점에서 접근해 보자. 잡다한 테크닉들이 필요해지는 이유는 다름아닌 "데이터의 부족"이다. Reconstructed 3D Map 을 바탕으로 labeling 하는 시스템을 잘 만들어 낼수만 있다면, 우리는 데이터를 이미지의 형태로 가지고 있는 것이 아니고, 공간의 형태로 가지고 있는 것이기 때문에 데이터를 우리가 필요한 방식으로 생성/관리/활용할 수 있고 필요한 공간만 뚝 떼어내어 사용할수도 있게 된다.
비록 레이블링 인하우스/외주 여부는 전략적 선택의 문제라지만, 자율주행 문제에서 효율적이고 다양한 도메인에 적용 가능하도록 Reconstructed Map 을 따 줄 업체는 없을 것이다(참고12) (참고41:팩트수집중). 흔치 않게 일부 업체는 Segmentation 데이터 수집을 위해 Reconstruction 을 사용하긴 하지만(참고28) Reconstructed 3D 공간상에서 차량 camera 시뮬레이션을 통해 sequential (temporal) data 를 수집하는 것이 아니라, sequential data 만을 위한 데이터셋을 따로 구축해야만 하는 듯했다(참고27). 대부분의 외주업체들은 2D 평면 레이블링을 할 것이고, 이는 3D 레이블링에 비해 비효율적이므로, 그 비용은 고스란히 디어의 지출이 된다. 가령 기구 위 하드웨어 배치가 달라지고 카메라 기종이 달라지거나 포즈가 달라져서 이에 맞는 데이터셋을 다시 요구한다면, 완전히 새로운 비용을 지불해야 한다는 것이다. 대부분의 MMS(Mobile Mapping System) 가 차도 데이터 수집 목적으로 설계되어 왔다는 것도 문제다(참고29). 하지만 3D Reconstructed Map 으로부터 영상을 추출할 수 있는 자체적인 기술이 있다면 그럴 걱정이 없다.
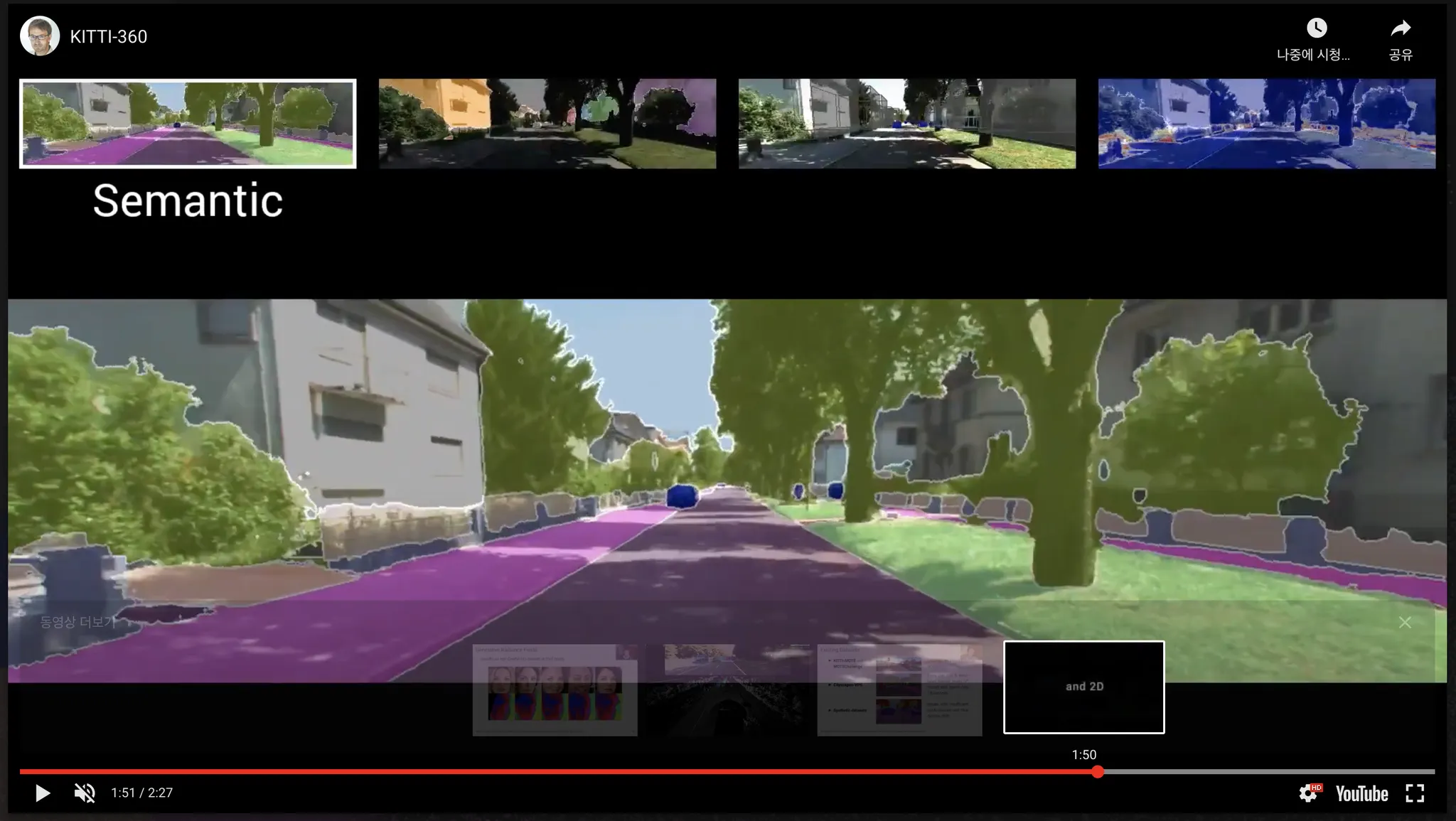
3D 데이터의 관점에서 레이블링할 때 작업 효율이 높아지는 이유는, 시간적/공간적으로 인접해 있는 영상들은 필연적으로 co-visible region(두 영상 모두에 동시에 보이는 영역) 이 큰데 이 영역을 모든 영상마다 다시 레이블링할 필요가 없기 때문이다(참고14). 이 주제를 우리 수준에서 구현할 수 있을까에 대한 질문을 다방면에 구한 결과, "어렵고 이슈가 많아 추천하기 어렵더라도 가능하긴 하다(참고13,14)" 라는 답변을 얻었다. 실제로 테슬라는 3D Labeling(영상에선 4D 라고 표현하기도 한다) 을 활용해 데이터 생산 속도를 1000배 높였다(참고1,2) 고 주장한다(참고35). 데이터수집업체 superbai 에서도 ‘데이터 생산 속도가 빨라지기는 할 것’ 이라고 말씀해 주셨다(참고36). 고려대학교 인공지능 대학원에서 3D Face Reconstruction task 를 연구했던 선배로부터 실제로 이 태스크와 관련된 주제들을 추천받을 수 있었다. 논문(참고19) 에서 발췌한 다음 그림에는 이 과정의 전반적인 파이프라인이 담겨 있다(참고18). 2016년에 공개된 오래된 논문이라 소개된 방법론을 받아들일 수는 없다. 하지만 큰 맥락에서 3D Data → 3D reconstruction → Pseudo label → User interaction → 3D/2D reprojection 의 파이프라인은 정리해 둘 만하다. 또한 Kitti 360 데이터셋은 라이다와(참고40:위험성) 카메라를 활용해 수집되었고 3D 공간에서 레이블링되었다. 3D 데이터로부터 만들어진 서브셋인 2D 데이터도 비슷한 파이프라인을 거쳐 만들어졌다(참고37,38,39).
그림 (참고18)
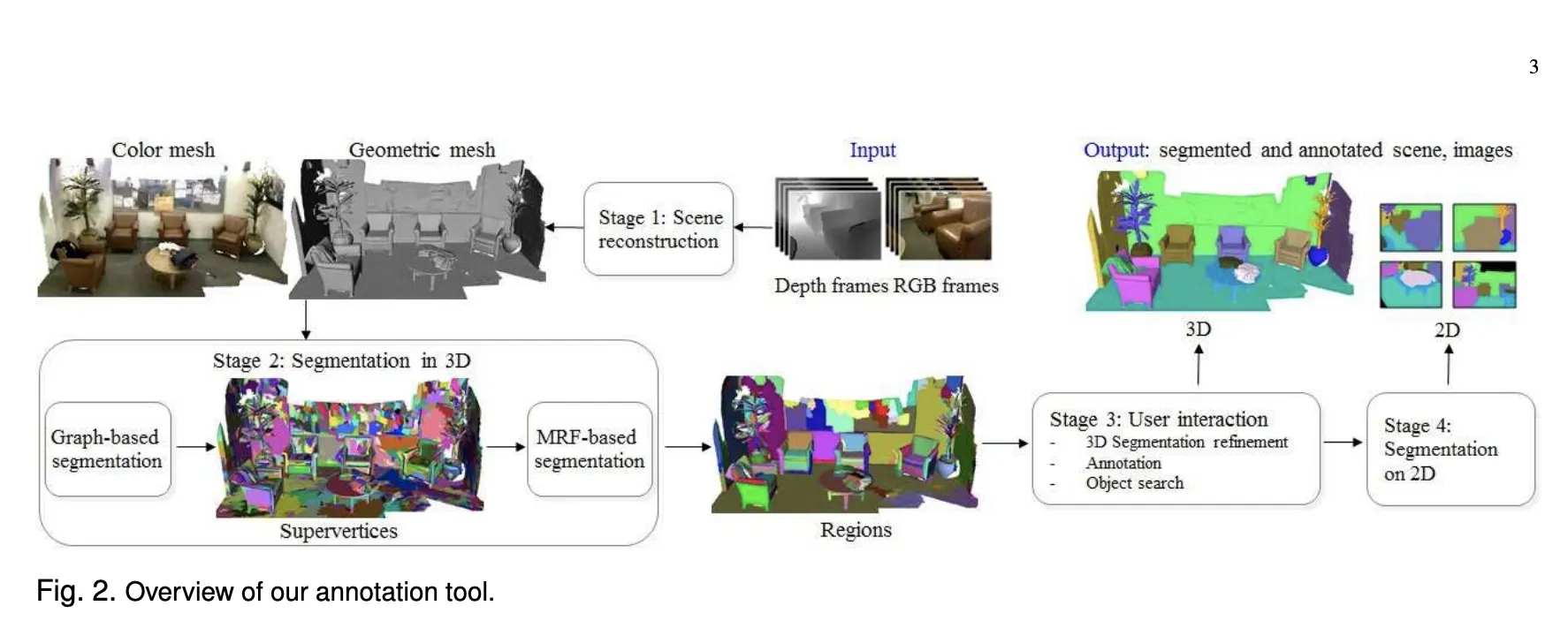
그림 (참고38)
훌륭한 모델과 최신의 모델을 구현하고 따라가는 것도 중요하지만, 데이터에 대해 집착하는 이유는 풀고자 하는 상황에 맞는 고품질의 데이터를 더 많이 준비하는 것이 좋은 모델을 구축하는 것보다 훨씬 더 중요하다고 강조되고 있기 때문이다. 딥러닝 민주화를 이끌었던 거장 앤드류 웅(Andrej Ng) 교수님은 2020년 있었던 공개적인 발표에서, GPT-3 정도의 성능을 만드는 인공지능일지라도 사람들은 모델만 기억하지만 실제로는 데이터가 80% 기여했으며(참고 21), 동일 시간을 주었을 때 모델에 집중한 팀은 전혀 성능을 높이지 못한 데 비해 데이터에 집중한 팀은 대부분 높은 성능 향상을 만들었다는 분석결과는 꽤 주목할 만하다(참고7). 이는 단지 아카데믹에 한정된 탁상공론이 아니며, 최근 딥러닝을 사용하는 수많은 업계 도메인에서도 이와 비슷한 여론이 형성되고 있다(참고15).
사실 나는 이러한 데이터문제들을 회피하고자 정답값 없이 학습할 수 있는 방법을 연구하는 분야: self-supervised learning 과 풀고자 하는 문제와 비슷한 문제에 데이터가 많을 때 많은 데이터를 이용해서 데이터가 빈곤한 도메인의 문제를 푸는 분야: transfer learning 에 대한 내용에 관심을 가졌다(참고16). 하지만 이 방법들은 본질적으로 데이터가 없다는 문제를 우회하는 연구들이다. 문제를 우회해서 해결하는 데에도 엄청난 리소스가 들어갈 것이라는 사실을 간과해서는 안된다. Vision task 의 transfer learning 에 대해서 회의적인 시각을 던진 논문(참고23) 에서는, downstream task 보다 수십~수백배 많은 데이터와 리소스가 필요한 upstream task 에 들어가는 리소스도 training 에 필요한 리소스라는 점을 상기시켰으며(참고26) 그 효과 또한 미미하여(참고24) 차라리 target task 데이터를 모을 것을 권유했다(참고25). Self-supervised 에서 최근 각광받고 있는 contrastive learning 을 보면, 2021년이 다 와서야 segmentation task 를 위한 contrastive learning 이 제안되고 있다는 사실을 알 수 있다. 이는 아직 작은 스타트업에서 사용하기에 설익고 검증되지 않은 기술로, 삽질할 시간에 데이터셋을 구축하는 것이 더 저렴할 수 있다. 즉, 데이터를 갖출 방법을 생각하지 않은 채, 방법들만 들이밀면 무조건 또다른 삽질에 갇힌다.
우리가 풀어야 하는 문제는 자율주행 문제인데, 문제에 데이터셋을 맞추는 것이 아니라, 데이터셋에 맞는 소프트웨어와 하드웨어를 사용해야만 했고, 이 괴리 사이에서 어떻게든 우리 문제에 끼워맞추려는 정말 많은 삽질들을 했다. 하지만 문제의 본질은 4D 데이터 (3D+time dimension) 가 없다는 것이다. 자율주행 문제를 풀려면 데이터가 있어야 한다. "데이터셋으로 사용하려고 3D Map 을 만들겠다" 는 것이 닭같이 보이는 데이터를 구축하기 위해 소 잡는 묵직한 칼을 사용하는 꼴로 보일지라도, 우리가 활용할 수 있는 데이터를 구축하는 일은 닭이 아니라 소에 훨씬 가깝다고 강조하고 싶다.
자사에서 데이터를 구축할 역량이 없다면 당연히 서드파티에 위탁해야 한다. 하지만 서드파티에는 분명히 리스크가 존재한다. 우리는 아직 ‘엄청 구체적인’ 전략이 없다. 또한 킥보드에 자율주행을 적용한 사례가 없다. 전략과 기술적으로 수많은 시행착오를 거치고 있는 자동차의 자율주행 업계와 다르게, 우리가 아무리 전략을 정밀하게 세운다고 한들 이것이 진리일 가능성이 적지 않은가(다양한 문제들에 대해서는 참고 30 에서 추가적으로 다룬다). 앞서 데이터 외주에 대해서 논하며 짧게 언급했듯, 우리의 전략이 조금 변경돼서 카메라의 각도를 조금 비틀어 버리는 의사결정들을 하게 되더라도 모든 레이블 정보를 다시 요청해야 할 리스크, 실제로 작업 결과물의 신뢰성(참고11) 및 태스크 적합성 등 많은 리스크가 있다는 것을 잊으면 안 된다.
현대자동차 컨퍼런스에서도 synthethic simulation 과 같은 것을 사용할 계획은 없냐고 질문이 들어왔었고, 현차측은 활용계획이 있다고 답변했다(참고17). 자율주행차 도메인에서는 궁극적인 시뮬레이션을 closed-loop (데이터수집-학습-추론-테스팅 전 과정에서 사람이 직접 해당 환경에 가서 문제를 파악하고 그에 맞는 액션을 취해야할 필요가 없는) data-driven (실제 세계 데이터로부터 만들어지고 더 많은 데이터가 쌓이면 쌓일수록 정교해지는) reactive (나의 행동에 의해 동적으로 반응하며, 시뮬레이션 내 객체들의 행동이 서로서로에게 영향을 미치는) simulation 이라고 한다(참고 4,5). 이 공간상에서 데이터를 레이블링할수도 있고, 시뮬레이션을 만들어 테스팅도 할 수 있다.
참고
6.
16.
40.
42.